
9.1 运行 Streams 的 Demo 程序
本教程假定您是新手并且没有现成的 Kafka 或 ZooKeeper 数据。 但是,如果您已经启动了Kafka和ZooKeeper,请随时跳过前两个步骤。
Kafka Streams 是用于构建关键任务的实时应用程序和微服务的客户端库,输入或输出数据存储在Kafka集群中。 Kafka Streams 结合了在客户端开发和部署标准Java和Scala应用程序的简易性,以及通过 Kafka 服务器端集群技术的优势,使这些应用程序具有高度可伸缩性,弹性,容错性,分布式等特性。
这个简易示例将演示如何在这个库中运行一个流应用程序。以下是 WordCountDemo 的示例代码(转换为使用Java 8 lambda表达式以便于阅读)。
// Serializers/deserializers (serde) for String and Long types
final Serde<String> stringSerde = Serdes.String();
final Serde<Long> longSerde = Serdes.Long();
// Construct a `KStream` from the input topic "streams-plaintext-input", where message values
// represent lines of text (for the sake of this example, we ignore whatever may be stored
// in the message keys).
KStream<String, String> textLines = builder.stream("streams-plaintext-input",
Consumed.with(stringSerde, stringSerde);
KTable<String, Long> wordCounts = textLines
// Split each text line, by whitespace, into words.
.flatMapValues(value -> Arrays.asList(value.toLowerCase().split("\\W+")))
// Group the text words as message keys
.groupBy((key, value) -> value)
// Count the occurrences of each word (message key).
.count()
// Store the running counts as a changelog stream to the output topic.
wordCounts.toStream().to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long()));
以上代码实现了WordCount算法,它根据输入文本计算一个单词出现频次的直方图。
但是,这个程序与您之前可能看到过的对有界数据进行操作的其他WordCount程序不同,这个WordCount演示应用程序的行为稍有不同,因为它是
设计用于操作无穷、无界的流数据。 类似于有界变体,它是一个可以跟踪和更新单词的数量的有状态的算法。
但是,因为它必须假设输入数据是无界的,因此它将定期输出当前状态和结果,同时继续处理更多数据,因为它无法知道它何时能处理完“全部”输入数据。
第一步,我们将启动 Kafka (除非你已经启动),然后我们将为 Kafka topic 准备输入数据,随后将由 Kafka 流应用程序处理流数据。
步骤1: 下载源代码
下载 1.0 release版本并解压。
注意有多个可下载的Scala版本程序,我们选择推荐的版本 ({{scalaVersion}}) :
> tar -xzf kafka_{{scalaVersion}}-{{fullDotVersion}}.tgz
> cd kafka_{{scalaVersion}}-{{fullDotVersion}}
步骤2: 启动 Kafka 服务
Kafka 使用到 ZooKeeper ,如果还没安装 ZooKeeper 的话需要先安装并启动 ZooKeeper 服务。 可以使用 kafka 打包的便捷脚本获取一个简单粗糙的单节点 ZooKeeper 实例。
> bin/zookeeper-server-start.sh config/zookeeper.properties [2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig) ...
现在可以启动 Kafka 服务:
> bin/kafka-server-start.sh config/server.properties [2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties) [2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties) ...
步骤3:准备 input topic 和启动 Kafka producer
接下来,我们创建名字为 streams-plaintext-input 的 input topic 以及名字为 streams-wordcount-output 的 output topic:
> bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
Created topic "streams-plaintext-input".
注意:因为 output stream 是changlog stream,因此我们创建 output stream 的时候启动了压缩。
Note: we create the output topic with compaction enabled because the output stream is a changelog stream
(参考 explanation of application output ).
> bin/kafka-topics.sh --create \
--zookeeper localhost:2181 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
Created topic "streams-wordcount-output".
已创建的 topic 可以使用同样的 kafka-topics 工具来查询描述信息:
> bin/kafka-topics.sh --zookeeper localhost:2181 --describe
Topic:streams-plaintext-input PartitionCount:1 ReplicationFactor:1 Configs:
Topic: streams-plaintext-input Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:streams-wordcount-output PartitionCount:1 ReplicationFactor:1 Configs:
Topic: streams-wordcount-output Partition: 0 Leader: 0 Replicas: 0 Isr: 0
步骤4: 启动 Wordcount 程序
以下命令将启动 WordCount 示例程序:
> bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
示例程序会从 input topic streams-plaintext-input 读取数据,以 WordCount 算法计算每条读到的消息,
并持续将当前的计算结果写到 output topic streams-wordcount-output。
因此,除了日志之外不会哟其他输出结果打印到STDOUT标准输出流,因为计算结构都回写到 Kafka 中。
现在我们可以在另外一个终端启动 Producer 会话来为这个 topic 写入数据:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
然后可以在另外一个终端启动 consumer 会话从 output topic 中读取并检查 WordCount 示例程序的输出:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
步骤5:处理数据
Now let's write some message with the console producer into the input topic streams-plaintext-input by entering a single line of text and then hit <RETURN>.
This will send a new message to the input topic, where the message key is null and the message value is the string encoded text line that you just entered
(in practice, input data for applications will typically be streaming continuously into Kafka, rather than being manually entered as we do in this quickstart):
现在我们可以在 producer 控制台通过输入单行文本并回车的方式输入消息到 input topic streams-plaintext-input。
这样会输入一条新的消息到 input topic,这条消息的key值是null,value值是刚刚输入的文本(实践中,应用程序的输入数据通常会不断地流进 Kafka,而不是像我们在这样子手动输入):
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input all streams lead to kafka
该消息将被 Wordcount 程序处理而且以下结果将写入到 streams-wordcount-output topic 并打印在consumer控制台:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
这里的第一个字段是 Kafka 消息的key值,格式是 java.lang.String,代表一个被统计到的单词,第二个字段是消息的value值,格式是 java.lang.Long,代表单词的最新统计次数。
接着我们继续在 producer 会话写入消息到input topic streams-plaintext-input。
输入文本"hello kafka streams"并回车。
终端应该如下:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input all streams lead to kafka hello kafka streams
在另外一个运行着consumer的终端上,将观察到 WordCount 程序的如下输出数据:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
hello 1
kafka 2
streams 2
这里显示的最后两行 kafka 2 和 streams 2 表示 kafka 和 streams 这两个key的计数已经更新,从 1 增长到 2 。
只要将更多输入消息写入 input topic ,都可以在 streams-wordcount-output topic 上观察到新消息,它们代表由WordCount应用程序计算出的最新字数。
在圆满完成这个快速示例之前让我们在producer控制台向input topic streams-wordcount-input 输入最后一行文本 "join kafka summit" 并回车:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-wordcount-input all streams lead to kafka hello kafka streams join kafka summit
streams-wordcount-output topic 将随后显示单词的计数更新(查看最后三行):
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
hello 1
kafka 2
streams 2
join 1
kafka 3
summit 1
可以看出,Wordcount应用程序的输出实际上是连续更新的流,其中每个输出记录(即上面原始输出中的每行)是一个单词的更新计数,诸如“kafka”之类的记录的key值。
对于有相同key值的多条记录,每条新的记录都是前一条记录的更新。
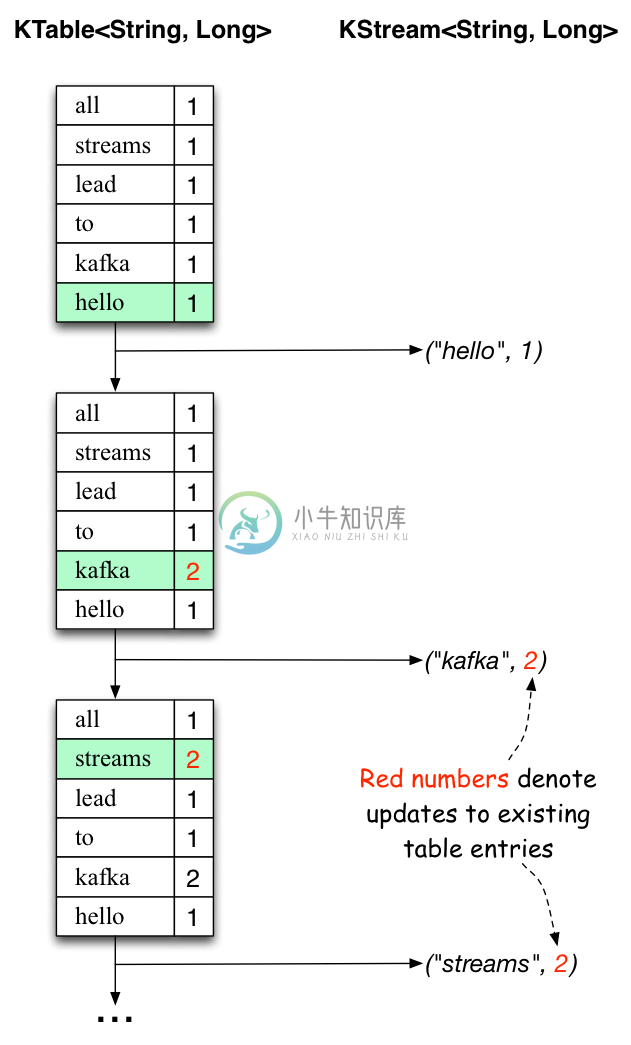
下面的两张图说明了后台实际发生的内容。
第一列显示代表单词出现次数 count 的 KTable<String, Long> 的当前状态的演变。
第二列显示从KTable的状态更新以及发送到Kafka output topic streams-wordcount-output 的更改记录。
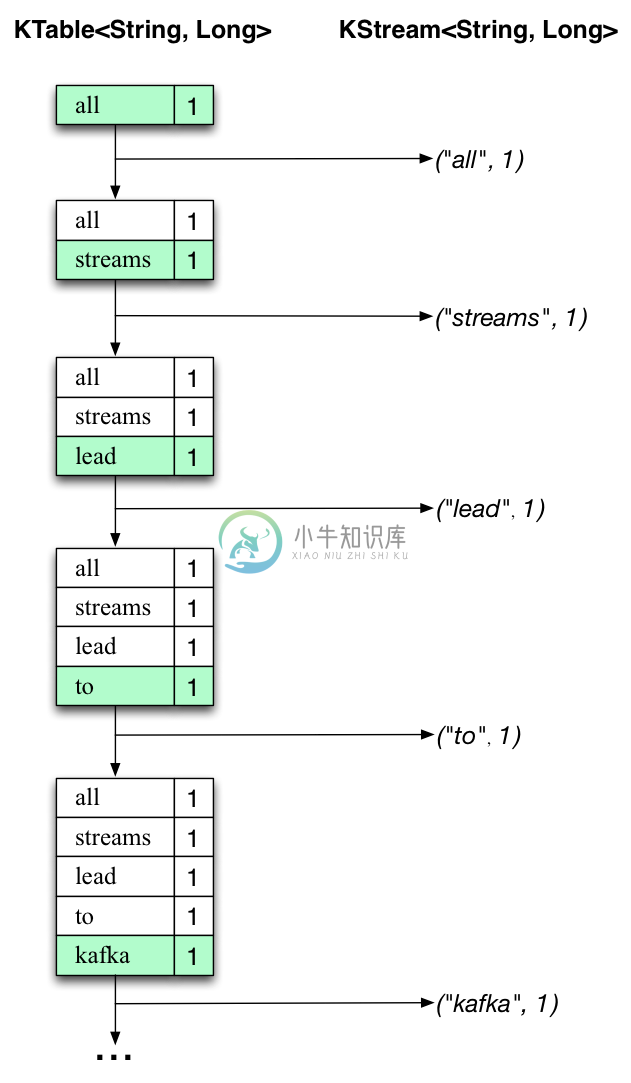
首先,当第一行文本 "all streams lead to kafka" 开始被处理。
当每个新单词产生一个新表项(用绿色背景突出显示)时,KTable 也开始创建,并将相应的更改记录发送到下游KStream。
当处理第二行文本“hello kafka streams”时,我们首次观察到KTable中现有的条目更新(这里是:"kafka"和"streams"两个key值)。同样地,更改记录也被发送到 output topic 。
处理过程大致如此(我们跳过了第三行如何处理的说明)。 这解释了为什么 output topic 具有我们上面显示的内容,因为它包含完整的更改记录。
除了这个具体例子之外,Kafka Streams 还演示了如何利用 table 和 changelog stream 之间的对偶性(这里:table = KTable,changelog stream =下游KStream):你可以将table的内容发布并转换为流,并且如果从头到尾使用整个 changelog stream ,则我们可以重新构建整个table的内容。
Step 6: Teardown the application
现在,你可以通过 Ctrl + C 按钮按顺序停止 consumer,producer,Wordcount程序, Kafka broker和ZooKeeper服务。