
4.8 日志压缩
迄今为止,我们只介绍了简单的日志保留方法(当旧的数据保留时间超过指定时间、日志大达到规定大小后就丢弃)。这样的策略非常适用于处理那些暂存的数据,例如记录每条消息之间相互独立的日志。然而在实际使用过程中还有一种非常重要的场景——根据key进行数据变更(例如更改数据库表内容),使用以上的方式显然不行。
让我们来讨论一个关于处理这样的流式数据的具体的例子。假设我们有一个topic,里面的内容包含用户的email地址;每次用户更新他们的email地址时,我们发送一条消息到这个topic,这里使用用户Id作为消息的key值。现在,我们在一段时间内为id为123的用户发送一些消息,每个消息对应email地址的改变(其他ID消息省略):
123 => bill@microsoft.com . . . 123 => bill@gatesfoundation.org . . . 123 => bill@gmail.com日志压缩为我提供了更精细的保留机制,所以我们至少保留每个key的最后一次更新 (例如:bill@gmail.com)。 这样我们保证日志包含每一个key的最终值而不只是最近变更的完整快照。这意味着下游的消费者可以获得最终的状态而无需拿到所有的变化的消息信息。
让我们先看几个有用的使用场景,然后再看看如何使用它。
- 数据库更改订阅。 通常需要在多个数据系统设置拥有一个数据集,这些系统中通常有一个是某种类型的数据库(无论是RDBMS或者新流行的key-value数据库)。 例如,你可能有一个数据库,缓存,搜索引擎集群或者Hadoop集群。每次变更数据库,也同时需要变更缓存、搜索引擎以及hadoop集群。 在只需处理最新日志的实时更新的情况下,你只需要最近的日志。但是,如果你希望能够重新加载缓存或恢复搜索失败的节点,你可能需要一个完整的数据集。
- 事件源。 这是一种应用程序设计风格,它将查询处理与应用程序设计相结合,并使用变更的日志作为应用程序的主要存储。
- 日志高可用。 执行本地计算的进程可以通过注销对其本地状态所做的更改来实现容错,以便另一个进程可以重新加载这些更改并在出现故障时继续进行。 一个具体的例子就是在流查询系统中进行计数,聚合和其他类似“group by”的操作。实时流处理框架Samza, 使用这个特性正是出于这一原因。
想法很简单,我们有无限的日志,以上每种情况记录变更日志,我们从一开始就捕获每一次变更。使用这个完整的日志,我们可以通过回放日志来恢复到任何一个时间点的状态。然而这种假设的情况下,完整的日志是不实际的,对于那些每一行记录会变更多次的系统,即使数据集很小,日志也会无限的增长下去。丢弃旧日志的简单操作可以限制空间的增长,但是无法重建状态——因为旧的日志被丢弃,可能一部分记录的状态会无法重建(这些记录所有的状态变更都在旧日志中)。
日志压缩机制是更细粒度的、每个记录都保留的机制,而不是基于时间的粗粒度。这个理念是选择性的删除那些有更新的变更的记录的日志。这样最终日志至少包含每个key的记录的最后一个状态。
这个策略可以为每个Topic设置,这样一个集群中,可以一部分Topic通过时间和大小保留日志,另外一些可以通过压缩压缩策略保留。
这个功能的灵感来自于LinkedIn的最古老且最成功的基础设置——一个称为Databus的数据库变更日志缓存系统。不像大多数的日志存储系统,Kafka是专门为订阅和快速线性的读和写的组织数据。和Databus不同,Kafka作为真实的存储,压缩日志是非常有用的,这非常有利于上游数据源不能重放的情况。
日志压缩基础
这是一个高级别的日志逻辑图,展示了kafka日志的每条消息的offset逻辑结构。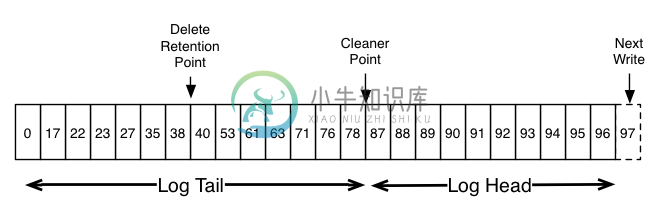
Log head中包含传统的Kafka日志,它包含了连续的offset和所有的消息。日志压缩增加了处理tail Log的选项。上图展示了日志压缩的的Log tail的情况。tail中的消息保存了初次写入时的offset。即使该offset的消息被压缩,所有offset仍然在日志中是有效的。在这个场景中,无法区分和下一个出现的更高offset的位置。如上面的例子中,36、37、38是属于相同位置的,从他们开始读取日志都将从38开始。
压缩也允许删除。通过消息的key和空负载(null payload)来标识该消息可从日志中删除。这个删除标记将会引起所有之前拥有相同key的消息被移除(包括拥有key相同的新消息)。但是删除标记比较特殊,它将在一定周期后被从日志中删除来释放空间。这个时间点被称为“delete retention point”,如上图。
压缩操作通过在后台周期性的拷贝日志段来完成。清除操作不会阻塞读取,并且可以被配置不超过一定IO吞吐来避免影响Producer和Consumer。实际的日志段压缩过程有点像这样:

What guarantees does log compaction provide?
日志压缩的保障措施如下:- 任何滞留在日志head中的所有消费者能看到写入的所有消息;这些消息都是有序的offset。 topic使用min.compaction.lag.ms来保障消息写入之前必须经过的最小时间长度,才能被压缩。 这限制了一条消息在Log Head中的最短存在时间。
- 始终保持消息的有序性。压缩永远不会重新排序消息,只是删除了一些。
- 消息的Offset不会变更。这是消息在日志中的永久标志。
- 任何从头开始处理日志的Consumer至少会拿到每个key的最终状态。 另外,只要Consumer在小于Topic的delete.retention.ms设置(默认24小时)的时间段内到达Log head,将会看到所有删除记录的所有删除标记。 换句话说,因为移除删除标记和读取是同时发生的,Consumer可能会因为落后超过delete.retention.ms而导致错过删除标记。
日志压缩的细节
日志压缩由Log Cleaner执行,后台线程池重新拷贝日志段,移除那些key存在于Log Head中的记录。每个压缩线程如下工作:- 选择log head与log tail比率最高的日志。
- 在head log中为每个key的最后offset创建一个的简单概要。
- 它从日志的开始到结束,删除那些在日志中最新出现的key的旧的值。新的、干净的日志将会立即被交到到日志中,所以只需要一个额外的日志段空间(不是日志的完整副本)
- 日志head的概要本质上是一个空间密集型的哈希表,每个条目使用24个字节。所以如果有8G的整理缓冲区, 则能迭代处理大约366G的日志头部(假设消息大小为1k)。
配置Log Cleaner
Log Cleaner默认启用。这会启动清理的线程池。如果要开始特定Topic的清理功能,可以开启特定的属性:log.cleanup.policy=compact这个可以通过创建Topic时配置或者之后使用Topic命令实现。
Log Cleaner可以配置保留最小的不压缩的head log。可以通过配置压缩的延迟时间:
log.cleaner.min.compaction.lag.ms这可以保证消息在配置的时长内不被压缩。 如果没有设置,除了最后一个日志外,所有的日志都会被压缩。 活动的 segment 是不会被压缩的,即使它保存的消息的滞留时长已经超过了配置的最小压缩时间长。
关于cleaner更详细的配置在 这里。