
Tornado HTTP 服务器的基本流程
本小节介绍Tornado HTTP服务器的基本流程,分别分析httpserver, ioloop, iostream模块的代码来剖析Tornado底层I/O的内部实现。
httpserver.py中给出了一个简单的http服务器的demo,代码如下所示:
from tornado import httpserver
from tornado import ioloop
def handle_request(request):
message = "You requested %s\n" % request.uri
request.write("HTTP/1.1 200 OK\r\nContent-Length: %d\r\n\r\n%s" % (
len(message), message))
request.finish()
http_server = httpserver.HTTPServer(handle_request)
http_server.bind(8888)
http_server.start()
ioloop.IOLoop.instance().start()
该http服务器主要使用到IOLoop, IOStream, HTTPServer, HTTPConnection几大模块,分别在代码ioloop.py, iostream.py, httpserver.py中实现。工作的流程如下图所示:
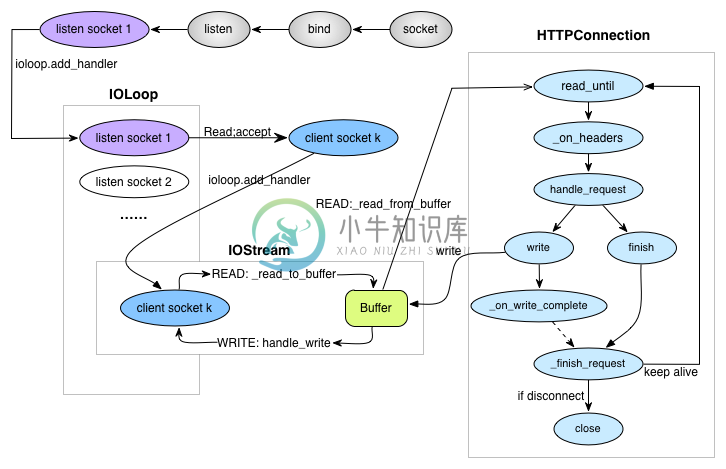
服务器的工作流程:首先按照socket->bind->listen顺序创建listen socket监听客户端,并将每个listen socket的fd注册到IOLoop的单例实例中;当listen socket可读时回调_handle_events处理客户端请求;在与客户端通信的过程中使用IOStream封装了读、写缓冲区,实现与客户端的异步读写。
HTTPServer分析
HTTPServer在httpserver.py中实现,继承自TCPServer(netutil.py中实现),是一个无阻塞、单线程HTTP服务器。支持HTTP/1.1协议keep-alive连接,但不支持chunked encoding。服务器支持'X-Real-IP'和'X-Scheme'头以及SSL传输,支持多进程为prefork模式实现。在源代码的注释中对以上描述比较详细的说明,这里就不再细说。
HTTPServer和TCPServer的类结构:
class HTTPServer(TCPServer):
def __init__(self, request_callback, no_keep_alive=False, io_loop=None, xheaders=False, ssl_options=None, **kwargs):
def handle_stream(self, stream, address):
class TCPServer(object):
def __init__(self, io_loop=None, ssl_options=None):
def listen(self, port, address=""):
def add_sockets(self, sockets):
def bind(self, port, address=None, family=socket.AF_UNSPEC, backlog=128):
def start(self, num_processes=1):
def stop(self):
def handle_stream(self, stream, address):
def _handle_connection(self, connection, address):
文章开始部分创建HTTPServer的过程:首先需要定义处理request的回调函数,在tornado中通常使用tornado.web.Application封装。然后构造HTTPServer实例,注册回调函数。接下来监听端口,启动服务器。最后启动IOLoop。
def listen(self, port, address=""):
sockets = bind_sockets(port, address=address)
self.add_sockets(sockets)
def bind_sockets(port, address=None, family=socket.AF_UNSPEC, backlog=128):
# 省略sockets创建,address,flags处理部分代码
for res in set(socket.getaddrinfo(address, port, family, socket.SOCK_STREAM,
0, flags)):
af, socktype, proto, canonname, sockaddr = res
# 创建socket
sock = socket.socket(af, socktype, proto)
# 设置socket属性,代码省略
sock.bind(sockaddr)
sock.listen(backlog)
sockets.append(sock)
return sockets
def add_sockets(self, sockets):
if self.io_loop is None:
self.io_loop = IOLoop.instance()
for sock in sockets:
self._sockets[sock.fileno()] = sock
add_accept_handler(sock, self._handle_connection,
io_loop=self.io_loop)
def add_accept_handler(sock, callback, io_loop=None):
if io_loop is None:
io_loop = IOLoop.instance()
def accept_handler(fd, events):
while True:
try:
connection, address = sock.accept()
except socket.error, e:
if e.args[0] in (errno.EWOULDBLOCK, errno.EAGAIN):
return
raise
# 当有连接被accepted时callback会被调用
callback(connection, address)
io_loop.add_handler(sock.fileno(), accept_handler, IOLoop.READ)
def _handle_connection(self, connection, address):
# SSL部分省略
try:
stream = IOStream(connection, io_loop=self.io_loop)
self.handle_stream(stream, address)
except Exception:
logging.error("Error in connection callback", exc_info=True)
这里分析HTTPServer通过listen函数启动监听,这种方法是单进程模式。另外可以通过先后调用bind和start(num_processes=1)函数启动监听同时创建多进程服务器实例,后文有关于此的详细描述。
bind_sockets在启动监听端口过程中调用,getaddrinfo返回服务器的所有网卡信息, 每块网卡上都要创建监听客户端的请求并返回创建的sockets。创建socket过程中绑定地址和端口,同时设置了fcntl.FD_CLOEXEC(创建子进程时关闭打开的socket)和socket.SO_REUSEADDR(保证某一socket关闭后立即释放端口,实现端口复用)标志位。sock.listen(backlog=128)默认设定等待被处理的连接最大个数为128。
返回的每一个socket都加入到IOLoop中同时添加回调函数_handle_connection,IOLoop添加对相应socket的IOLoop.READ事件监听。_handle_connection在接受客户端的连接处理结束之后会被调用,调用时传入连接和ioloop对象初始化IOStream对象,用于对客户端的异步读写;然后调用handle_stream,传入创建的IOStream对象初始化一个HTTPConnection对象,HTTPConnection封装了IOStream的一些操作,用于处理HTTPRequest并返回。至此HTTP Server的创建、启动、注册回调函数的过程分析结束。
HTTPConnection分析
该类用于处理http请求。在HTTPConnection初始化时对self.request_callback赋值为一个可调用的对象(该对象用于对http请求的具体处理和应答)。该类首先读取http请求中header的结束符b("\r\n\r\n"),然后回调self._on_headers函数。request_callback的相关实现在以后的系列中有详细介绍。
def __init__(self, stream, address, request_callback, no_keep_alive=False,
xheaders=False):
self.request_callback = request_callback
# some configuration code
self._header_callback = stack_context.wrap(self._on_headers)
self.stream.read_until(b("\r\n\r\n"), self._header_callback)
def _on_headers(self, data):
# some codes
self.request_callback(self._request)
多进程HTTPServer
Tornado的HTTPServer是单进程单线程模式,同时提供了创建多进程服务器的接口,具体实现是在主进程启动HTTPServer时通过process.fork_processes(num_processes)产生新的服务器子进程,所有进程之间共享端口。fork_process的方法在process.py中实现,十分简洁。对fork_process详细的分析,可以参考 番外篇:Tornado的多进程管理分析。
FriendFeed使用nginx提供负载均衡、反向代理服务并作为静态文件服务器,在后端服务器上可以部署多个Tornado实例。一般可以通过Supervisor控制Tornado app,然后再通过nginx对Tornado的输出进行反向代理。 具体可以参考下这篇文章: Supervisord进程管理工具的安装使用。