Tornado 源码必须要读的几个核心文件
前面我们看了一些关于 Tornado 的总体框架设计图,还有一些模块设计。比如 为什么要阅读Tornado的源码? 里面的文件组织,真的不少,那么我们应该具体去读哪几个文件呢?
为了方便,约定$root指带tornado的根目录。总的来说,要用 Tornado 完成一个网站的构建,其实主要需要以下几个文件:
- $root/tornado/web.py
- $root/tornado/httpserver.py
- $root/tornado/tcpserver.py
- $root/tornado/ioloop.py
- $root/tornado/iostream.py
- $root/tornado/platfrom/epoll.py
- $root/app.py
另外可能还需要一些功能库的支持而需要引入的文件就不列举了,比如util和httputil之类的。来看看每个文件的作用。
- app.py 是自己写的,内容就如 tornado 的 readme 文档里给的示例一样,定义路由规则和 handler,然后创建 application,发起 server 监听,服务器就算跑起来了。
- 紧接着就是 web.py。其中定义了 Application 和 RequestHandler 类,在 app.py 里直接就用到了。Application 是个单例,总揽全局路由,创建服务器负责监听,并把服务器传回来的请求进行转发(__call__)。RequestHandler 是个功能很丰富的类,基本上 web 开发需要的它都具备了,比如redirect,flush,close,header,cookie,render(模板),xsrf,etag等等
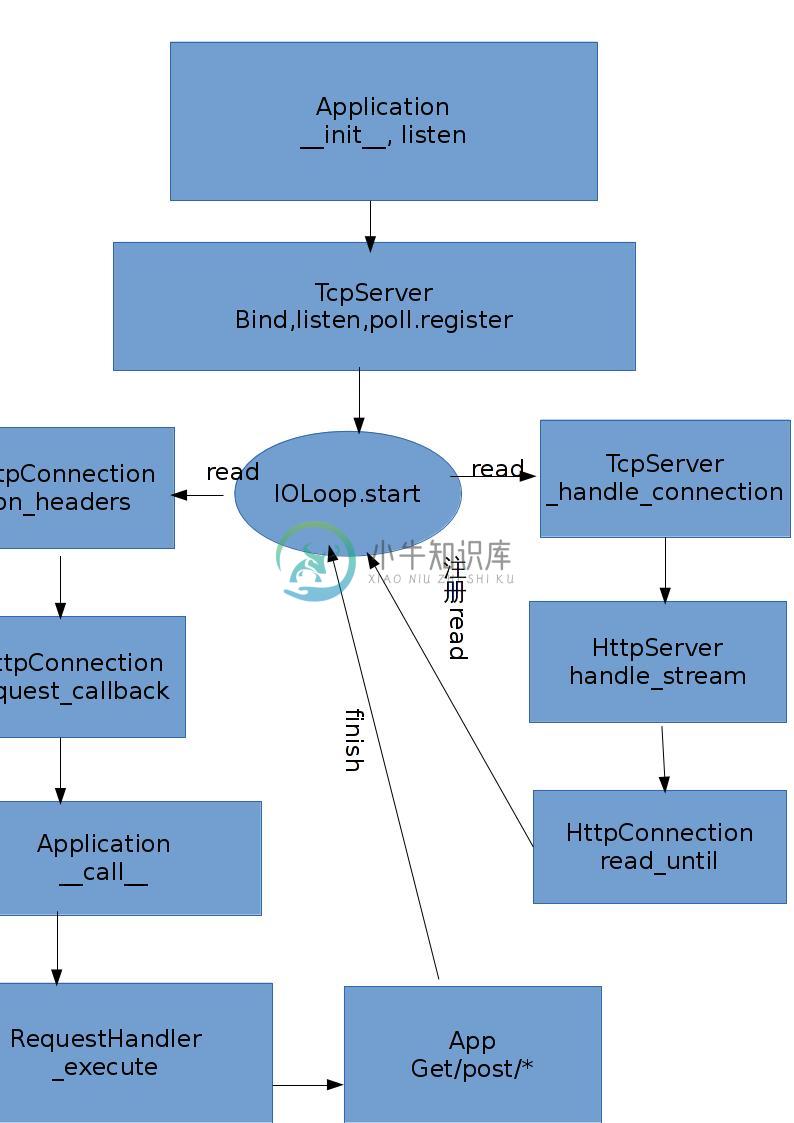
- 从 web 跟踪到 httpserver.py 和 tcpserver.py。这两个文件主要是实现 http 协议,解析 header 和 body, 生成request,回调给 appliaction,一个经典意义上的 http 服务器(written in python)。众所周知,这是个很考究性能的一块(IO),所以它和其它很多块都连接到了一起,比如 IOLoop,IOStream,HTTPConnection 等等。这里 HTTPConnection 是实现了 http 协议的部分,它关注 Connection 嘛,这是 http 才有的。至于监听端口,IO事件,读写缓冲区,建立连接之类都是在它的下层--tcp里需要考虑的,所以,tcpserver 才是和它们打交道的地方,到时候分析起来估计很麻烦
- 先说这个IOStream。顾名思义,就是负责IO的。说到IO,就得提缓冲区和IO事件。缓冲区的处理都在它自个儿类里,IO事件的异步处理就要靠 IOLoop 了。
- 然后是 IOLoop。如果你用过 select/poll/epoll/libevent 的话,对它的处理模型应该相当熟悉。简言之,就是一个大大的循环,循环里等待事件,然后处理事件。这是开发高性能服务器的常见模型,tornado 的异步能力就是在这个类里得到保证的
- 最后是 epoll.py。其实这个文件也没干啥,就是声明了一下服务器使用 epoll。选择 select/poll/epoll/kqueue 其中的一种作为事件分发模型,是在 tornado 里自动根据操作系统的类型而做的选择,所以这几种接口是一样的(当然效率不一样),出于简化,直接就epoll吧^_^
- PS。如果你是一个细节控,可能会注意到 tornado 里的回调 callback 函数都不是直接使用的,而是使用 stack_context.wrap 进行了封装。但据我观察,封装前后没多大差别(指逻辑流程),函数的参数也不变。但根据它代码里的注释,这个封装还是相当有用的:
Use this whenever saving a callback to be executed later in a different execution context (either in a different thread or asynchronously in the same thread).
所以,我猜,是使用了独有的context来保证在不同环境也能很好的执行。猜测而已,我也没细想,以后有时间再看好,最有用一个简单的流程来做结。