
VLE (Vision-Language Encoder) 是一种基于预训练文本和图像编码器的图像-文本多模态理解模型,可应用于如视觉问答、图像-文本检索等多模态判别任务。特别地,在对语言理解和推理能力有更强要求的视觉常识推理(VCR)任务中,VLE取得了公开模型中的最佳效果。
在线演示地址:https://huggingface.co/spaces/hfl/VQA_VLE_LLM
VLE模型采用双流结构,与METER模型结构类似,由两个单模态编码器(图像编码器和文本编码器)和一个跨模态融合模块构成。VLE与METER的结构上的差异在于:
- VLE使用DeBERTa-v3作为文本编码器,其性能优于METER中使用的RoBERTa-base。
- 在VLE-large中,跨模态融合模块的隐层维度增加至1024,以增加模型的容量。
- 在精调阶段,VLE引入了额外的token类型向量表示。
预训练
VLE使用图文对数据进行预训练。在预训练阶段,VLE采用了四个预训练任务:
- MLM (Masked Language Modeling):掩码预测任务。给定图文对,随机遮掩文本中的部分单词,训练模型还原遮掩的文本。
- ITM (Image-Text Matching):图文匹配预测任务。给定图文对,训练模型判断图像和文本是否匹配。
- MPC (Masked Patch-box Classification):遮掩Patch分类任务,给定图文对,并遮掩掉图片中包含具体对象的patch,训练模型预测被遮掩的对象种类。
- PBC (Patch-box classification):Patch分类任务。给定图文对,预测图片中的哪些patch与文本描述相关。
VLE在14M的英文图文对数据上进行了25000步的预训练,batch大小为2048。下图展示了VLE的模型结构和部分预训练任务(MLM、ITM和MPC)。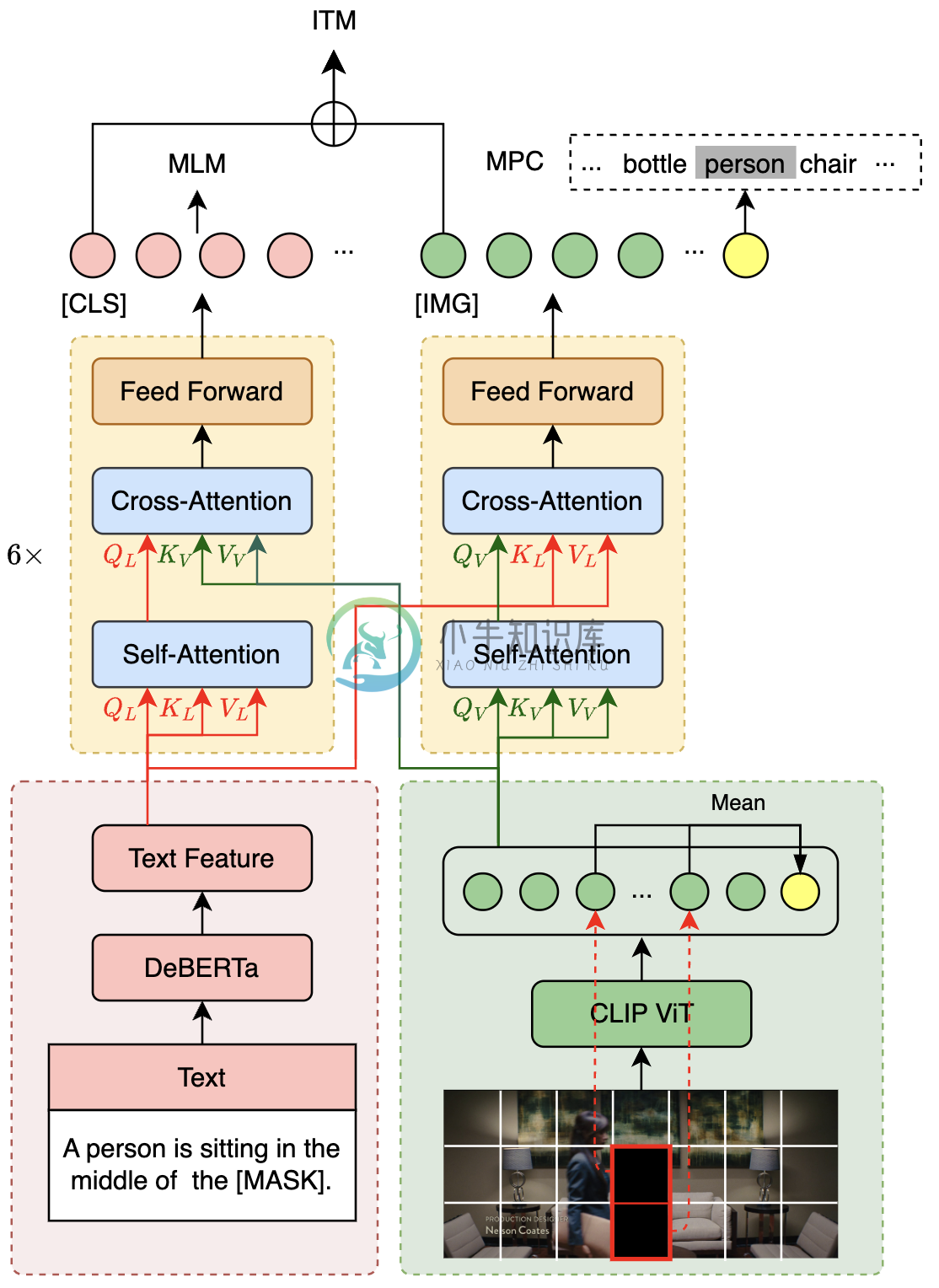
下游任务适配
视觉问答 (VQA)
- 遵循标准做法,使用VQA的训练集(training set)和验证集(validation set)训练模型,在test-dev集上进行验证。采用模型的融合层的pooler的输出进行分类任务的训练。
视觉常识推理 (VCR)
- 将VCR格式化为一个类似于RACE的选择题任务,并对于每张图像中的对象,将覆盖该对象的patch的表示的平均池化值添加到融合模块之前的图像特征序列中。还为图像和文本中的对象添加额外的token_type_ids,以注入不同模态之间的对齐信息,提升模型的对齐性能。
模型下载
本次发布了VLE-base和VLE-large两个版本的预训练模型,模型权重为PyTorch格式,可以选择手动从�� transformers模型库下载权重和配置文件,或者在代码中使用 from_pretrained(model_name) 以自动加载模型。详细方法参加模型使用。
预训练权重
| 模型 | 文本编码器 | 图像编码器 | 参数量* | MODEL_NAME | 链接 |
|---|---|---|---|---|---|
| VLE-base | DeBERTa-v3-base | CLIP-ViT-base-patch16 | 378M | hfl/vle-base | link |
| VLE-large | DeBERTa-v3-large | CLIP-ViT-large-patch14 | 930M | hfl/vle-large | link |
* : 仅计算encoder和emebddings的参数。特定任务的预测层的参数量未计入。
精调权重
| 模型 | 文本编码器 | 图像编码器 | MODEL_NAME | 链接 |
|---|---|---|---|---|
| VLE-base-for-VQA | DeBERTa-v3-base | CLIP-ViT-base-patch16 | hfl/vle-base-for-vqa | link |
| VLE-large-for-VQA | DeBERTa-v3-large | CLIP-ViT-large-patch14 | hfl/vle-large-for-vqa | link |
| VLE-base-for-VCR-q2a | DeBERTa-v3-base | CLIP-ViT-base-patch16 | hfl/vle-base-for-vcr-q2a | link |
| VLE-large-for-VCR-q2a | DeBERTa-v3-large | CLIP-ViT-large-patch14 | hfl/vle-large-for-vcr-q2a | link |
| VLE-base-for-VCR-qa2r | DeBERTa-v3-base | CLIP-ViT-base-patch16 | hfl/vle-base-for-vcr-qa2r | link |
| VLE-large-for-VCR-qa2r | DeBERTa-v3-large | CLIP-ViT-large-patch14 | hfl/vle-large-for-vcr-qa2r | link |
模型对比
在下表中比较了VLE、METER以及其他多模态模型的参数量、预训练数据和下游任务效果。其中VQA展示的的是test-dev集上的效果;VCR展示的是dev集上的效果。
| 模型 | VQA | VCR (QA2R) | VCR (Q2A) | 参数量 | 预训练数据量* |
|---|---|---|---|---|---|
| CoCa | 82.3 | - | - | 2.1 B | 未知 |
| BeiT-3 | 84.2 | - | - | 1.9 B | 21M(I-T) + 14M(I) + 160G(T) |
| OFA | 82.0 | - | - | 930M | 20M(I-T) + 39M(I) + 140G(T) |
| BLIP | 78.3 | - | - | 385M | ~130M(I-T) |
| METER-base | 77.7 (76.8†‡) | 79.8§ | 77.6§ | 345M | 9M(I-T) |
| METER-Huge | 80.3 | - | - | 878M | 20M(I-T) |
| VLE-base | 77.6‡ | 83.7§ | 79.9§ | 378M | 15M(I-T) |
| VLE-large | 79.3‡ | 87.5§ | 84.3§ | 930M | 15M(I-T) |
† : 复现效果
‡ : 精调参数: lr=7e-6, batch_size={256, 512}, num_epochs=10
§ : 精调参数: lr=1e-5, batch_size=128, num_epochs=5
* : I-T: 图文对. I: 图像. T: 文本.
观察上表可以发现:
- VLE的预训练更高效:与大小相近的模型相比,VLE使用了更少的预训练数据,并在视觉问答上取得了相当甚至更好的效果。
- VLE有更强的推理能力: 特别地,在对推理能力要求更高的视觉常识推理(VCR)任务上,VLE显著地超过了具有相似结构的METER。
-
ASR语言模型在线训练 分词 文本清洗 语言模型目前不支持英文,阿拉伯数字,标点符号以及特殊字符,所以需要将训练文本中英文剔除,阿拉伯数字转换成相应的中文表示,删除标点符号和特殊字符。 文本分词 一般先用结巴或清华分词器分词,再人工矫正,分词的原则是它需要具有独立的实体意义。比如,刘德华, 张学友,这些人名;还有一些地名,张家港,黑龙江等;专有名词,中国,迪士尼等.对于我们需要训练的文本,要保证分
-
在之前的描述中,我们通常把机器学习模型和训练算法当作黑箱子来处理。如果你实践过前几章的一些示例,你惊奇的发现你可以优化回归系统,改进数字图像的分类器,你甚至可以零基础搭建一个垃圾邮件的分类器,但是你却对它们内部的工作流程一无所知。事实上,许多场合你都不需要知道这些黑箱子的内部有什么,干了什么。 然而,如果你对其内部的工作流程有一定了解的话,当面对一个机器学习任务时候,这些理论可以帮助你快速的找到恰
-
在之前的描述中,我们通常把机器学习模型和训练算法当作黑箱子来处理。如果你实践过前几章的一些示例,你惊奇的发现你可以优化回归系统,改进数字图像的分类器,你甚至可以零基础搭建一个垃圾邮件的分类器,但是你却对它们内部的工作流程一无所知。事实上,许多场合你都不需要知道这些黑箱子的内部有什么,干了什么。 然而,如果你对其内部的工作流程有一定了解的话,当面对一个机器学习任务时候,这些理论可以帮助你快速的找到恰
-
我可以在AWS Sagemaker中通过评估模型来训练多个模型train.py脚本,以及如何从多个模型中获取多个指标? 任何链接、文档或视频都很有用。
-
我希望使用AWS Sagemaker工作流部署一个预训练的模型,用于实时行人和/或车辆检测,我特别想使用Sagemaker Neo编译模型并将其部署在边缘。我想从他们的模型动物园中使用OpenVino的预构建模型之一,但是当我下载模型时,它已经是他们自己的优化器的中间表示(IR)格式。 > 如果没有,是否有任何免费的预训练模型(使用任何流行的框架,如pytorch,tenorflow,ONXX等)
-
Polar Verity Sense 拥有三种训练模式:心率模式、记录模式和游泳模式。 请注意,在记录模式或游泳模式下使用传感器前,需要将传感器连接到您的 Polar Flow 账号。该操作已在设置期间完成。如果您没有按照设置 Verity Sense 中的说明完成设置,则只能在心率模式下使用传感器。 在心率模式下,您可以将传感器连接到兼容的设备或应用,在训练期间实时追踪您的心率。有关详细说明,请
-
光环板可以连接 mbuild 的 视觉模块 模块进行编程。 色块识别 1.视觉模块(1)切换到色块识别模式。 指定视觉模块切换到色块识别模式。 示例 按下光环板的按钮,视觉模块(1)切换到色块识别模式。 2. 视觉模块(1)开始学习色块(1)(直到按钮被按下) 指定视觉模块在制定操作执行后开始学习色块。 示例 按下光环板的按钮,视觉模块(1)开始学习色块(1)(直到按钮被按下)。 3. 视觉模块(
-
视觉模块能够识别条码和线条,也可以学习和识别颜色鲜艳的物体,实现诸如垃圾分类、智慧交通、物体追踪、智能巡线等功能。 连接主控板 通过不同的连线方式,可以将视觉模块作为一个 RJ25 电子模块或 mBuild 电子模块,连接到 mBot 或光环板,然后使用 mBot 或光环板控制视觉模块。 连接到 mBot 与 mBot 连接时,可以使用 3.7V 锂电池或 mBuild 电源模块连接到视觉模块,为