
Boilerpipe 是一个能从 HTML 中剔除广告和其他附加信息,提取出目标信息(如正文内容、发布时间)的 Java 库。其算法的基本思想是通过训练获得一个分类器来提取出我们需要的信息。
Boilerpipe 的包结构:
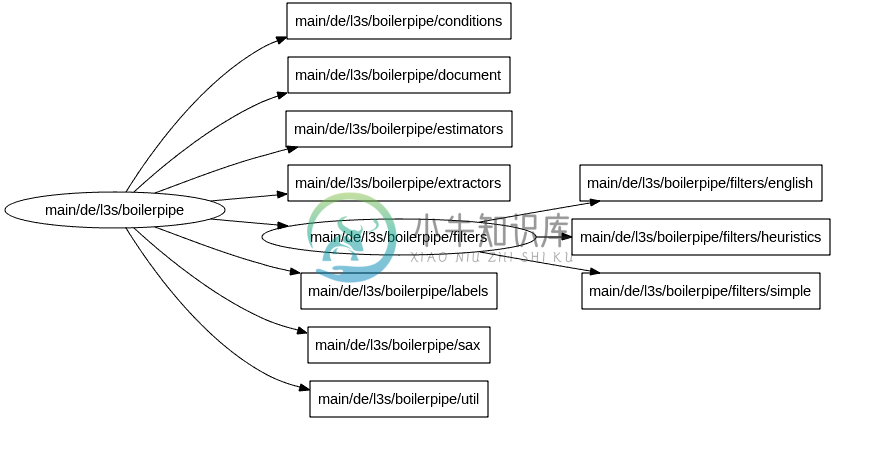
boilerpipe,根目录
document,文档包,定义了 boilerpipe 所处理文档数据类型,主要包括 TextDocument 和 TextBlock 。一个 TextDocument 即一个网页,由多个 TextBlock 构成。
lables,标签,每个 TextBlock 都有一个 lable 字段,表示该 TextBlock 的属性(如是不是正文)。
filters,过滤器,定义了多个过滤器,过滤器的作用即对 TextBlock 进行过滤,使用机器学习、统计、启发式方法等数据挖掘算法判断哪些 TextBlock 是所需要的(正文段),给 TextBlock 加上 lable ,去除无关的 TextBlock 。
sax,SAX 解析器,定义了从各种来源获取并解析网页的方法。
extractors,提取器,提取流程的入口。每个 extractor 都定义了自己的提取方法,通过调用不同的 filter 达到不同的处理效果。
conditions,条件判断,判断一个 TextBlock 是否满足特定的条件。
estimators,评估器,评估一个 extractor 对特定 document 的提取效果。
调用关系图示:
介绍内容摘自:CSDN
-
使用pip或者python setup install 安装jpype总是报错,几乎搜遍全网,使用了各种解决方案,均无效,遂放弃, 换思路使用Anaconda进行安装 首先安装Anaconda,Anaconda官网的介绍为: 设想一个数据科学家可以定期将人工智能和机器学习项目大规模部署到生产中的世界,快速向决策者提供见解。这对您的业务有何影响? Anaconda Enterprise支持您的组织,
-
运行boilerpipe 时报以下错误: Traceback (most recent call last): File "/Users/Adrian/anaconda3/lib/python3.6/site-packages/boilerpipe/extract/__init__.py", line 45, in __init__ self.data = unicode(self.d
-
开源Java模块boilerpipe(1.1.0), http://code.google.com/p/boilerpipe/ 使用例子, URL url = new URL("http://www.example.com/some-location/index.html "); // NOTE: Use ArticleExtractor unless DefaultExtractor gives
-
需求: 基于boilerpipe抽取页面的文本内容,基于url的openStream来获取页面的时候会碰到乱码,解决方式是基于jsoup来获取body的byte流 实现: jar依赖: <dependency> <groupId>com.syncthemall</groupId> <artifactId>boilerpipe</artifactId> <version>1.2.2</vers
-
安装boilerpipe的地址为:python-boilerpipe 得到以下错误: $ python setup.py install Traceback (most recent call last): File "setup.py", line 26, in <module> download_jars(datapath=DATAPATH) File "setup.py",
-
Tika使用各种解析器库从给定的解析器中提取内容。 它选择正确的解析器来提取给定的文档类型。 对于解析文档,通常使用Tika facade类的parseToString()方法。 下面显示的是解析过程中涉及的步骤,这些步骤由Tika ParsertoString()方法提取。 摘要解析过程 - 最初,当我们将文档传递给Tika时,它使用合适的类型检测机制并检测文档类型。 知道文档类型后,它会从其解
-
问题内容: 输入线在下面 你能帮我写一个Java正则表达式来提取 从上方输入线? 问题答案: 更加简洁:
-
我有一个位于Azure Data Lake Store上的文件,我正在编写一个apiendpoint以将该文件的内容作为字符串检索。我遇到的问题是,当我尝试读取流时,我得到一个空字符串。这是我正在使用的: 目前,返回文件的响应工作正常,我可以在PC上打开文件并读取其内容。使用StreamReader返回文件内容的响应返回空字符串。
-
问题内容: 我正在用Java开发一个应用程序,该应用程序可以从不同的网页获取文本信息并将其汇总为一页。例如,假设我在不同的网页(例如印度教,印度时报,政治家等)上都有新闻。该应用程序应该从这些页面的每个页面中提取要点,并将它们整合为一条新闻。该应用程序基于Web内容挖掘的概念。作为该领域的初学者,我不知道从哪里开始我浏览了一些研究论文,这些论文将消除噪声作为构建此应用程序的第一步。 因此,如果给我
-
问题内容: 我有一个rpm,我想把它像压缩包一样对待。我想将内容提取到目录中,以便检查内容。我熟悉已卸载软件包的查询命令。我不只是想要rpm内容列表。即 我想检查rpm中包含的几个文件的内容。 我不想安装rpm。 我也知道rpms在%post部分中进行其他修改的能力,以及如何检查这些内容。即 但是,在这种情况下,这与我无关。 问题答案: 您尝试过该命令吗?请参阅以下示例:
-
我希望提取除页眉和页脚之外的整个html正文内容,但我遇到了例外 org.xml.sax。SAXException:命名空间http://www.w3.org/1999/xhtml未声明 下面是我创建的代码,如上所述 我得到的例外是 虽然我知道根据TIKA-1215,我们不应该包装内容处理程序,但我看不出有任何替代方法来解决这个问题,因为简单的身体接触器没有帮助,我验证了很多类似的堆栈溢出案例,但
-
我一直有一个严重的问题与我的PDF文件。我想从我的PDF中提取所有的文本。提取后,我有所有的字节码。 我怎样才能从中提取文本呢?