
ColossalAI 是一个具有高效并行化技术的综合大规模模型训练系统。旨在无缝整合不同的并行化技术范式,包括数据并行、管道并行、多张量并行和序列并行。
Colossal-AI 的目标是支持人工智能社区以与他们正常编写模型相同的方式编写分布式模型。这使得他们可以专注于开发模型架构,并将分布式训练的问题从开发过程中分离出来。
ColossalAI 提供了一组并行训练组件。旨在支持用户编写分布式深度学习模型,就像编写单 GPU 模型一样。提供友好的工具,只需几行即可启动分布式培训。
import colossalai from colossalai.engine import Engine from colossalai.trainer import Trainer from colossalai.core import global_context as gpc model, train_dataloader, test_dataloader, criterion, optimizer, schedule, lr_scheduler = colossalai.initialize() engine = Engine( model=model, criterion=criterion, optimizer=optimizer, lr_scheduler=lr_scheduler, schedule=schedule ) trainer = Trainer(engine=engine, hooks_cfg=gpc.config.hooks, verbose=True) trainer.fit( train_dataloader=train_dataloader, test_dataloader=test_dataloader, max_epochs=gpc.config.num_epochs, display_progress=True, test_interval=5 )
展示样例
ViT

- 14倍批大小和5倍训练速度(张量并行=64)
GPT-3

- 释放 50% GPU 资源占用, 或 10.7% 加速
GPT-2
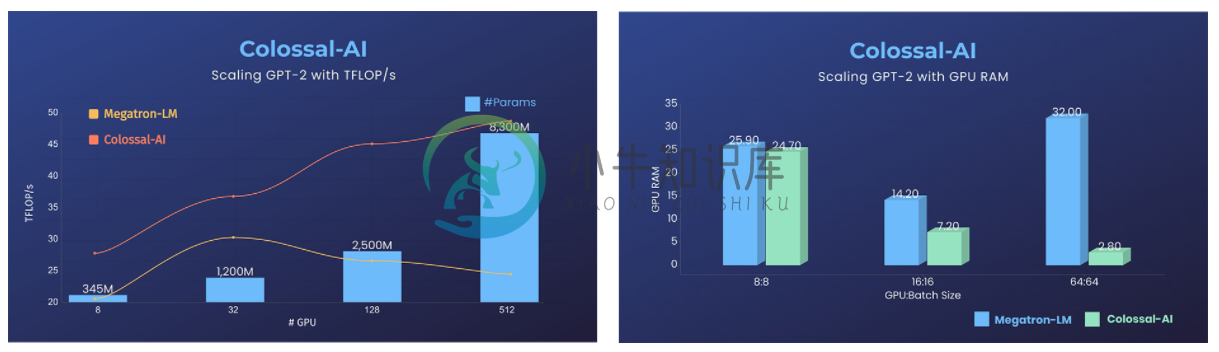
- 降低11倍GPU显存占用,或超线性扩展
BERT
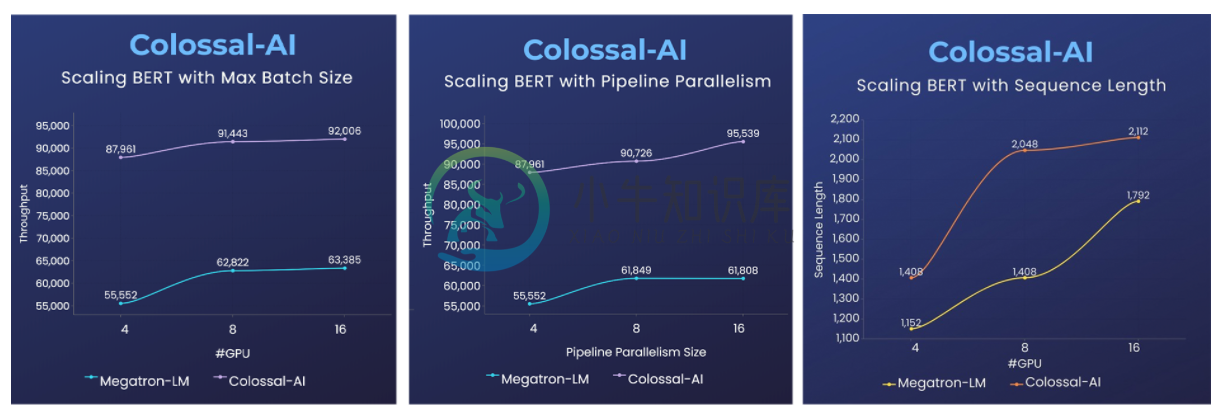
- 2倍训练速度,或1.5倍序列长度
-
Colossal-AI具有下面的优点: 加快训练速度 提高显存利用率 使用colossalai无法提高显存利用率 这是在测试的时候发现的,使用colossalai以BATCH_SIZE = 16384训练models.shufflenet_v2_x1_0会出现显存溢出的问题; 我们已经在hpcaitech/ColossalAI-Examples上提出了issue#139,目前还没有得到回复; 使用
-
GPU Programming介绍 openAI ColossalAI官方文档 ColossalAI+ldm简介:Diffusion Pretraining and Hardware Fine-Tuning Can Be Almost 7X Cheaper! Colossal-AI’s Open Source Solution Accelerates AIGC at a Low Cost 手部生成
-
我作为一个人工智能模型,无法对特定公司的业务表现进行直接评价。但是,根据公开的信息,Colossal AI 是由计算机科学家兼企业家 Andrej Karpathy 和 OpenAI 创始人 Greg Brockman 共同创立的公司,旨在推动人工智能的发展和普及。 Colossal AI 的主要业务是开发和销售 AI 工具和技术,如训练数据集、模型架构和算法等。据报道,该公司聚集了一批顶尖的人工
-
通过 NVIDIA GPU 加速平台,Colossal-AI 实现了通过高效多维并行、异构内存管理、大规模优化库、自适应任务调度等方式,更高效快速部署 AI 大模型训练与推理。 AI 大模型的高门槛成为研发一大难题 近年来,AI 模型已从 AlexNet、ResNet、AlphaGo 发展到 BERT、GPT、MoE…随着深度学习的兴起及大模型横扫各大性能榜单,AI 能力不断提升的一个显著特征是模
-
近日,受CSDN副总裁SoftwareTeacher老师的邀请,我们针对大家对于Colossal-AI所关心的问题进行了解答。 大规模并行AI训练系统Colossal-AI通过高效多维并行、大规模优化库、自适应任务调度、消除冗余内存等方式,旨在打造一个高效的分布式AI系统,作为深度学习框架的内核,帮助用户便捷实现最大化提升AI部署效率,同时最小化部署成本。 开源地址: https://github
-
AI-learning Q&A 2022年8月18日22:45:19 Q:在ipython中运行run试的时候,无法成功会出现如下错误提示。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fWBF7YLk-1661576171052)(C:\Users\光明斗士\AppData\Roaming\Typora\typora-user-images\image-2022
-
在之前的描述中,我们通常把机器学习模型和训练算法当作黑箱子来处理。如果你实践过前几章的一些示例,你惊奇的发现你可以优化回归系统,改进数字图像的分类器,你甚至可以零基础搭建一个垃圾邮件的分类器,但是你却对它们内部的工作流程一无所知。事实上,许多场合你都不需要知道这些黑箱子的内部有什么,干了什么。 然而,如果你对其内部的工作流程有一定了解的话,当面对一个机器学习任务时候,这些理论可以帮助你快速的找到恰
-
在之前的描述中,我们通常把机器学习模型和训练算法当作黑箱子来处理。如果你实践过前几章的一些示例,你惊奇的发现你可以优化回归系统,改进数字图像的分类器,你甚至可以零基础搭建一个垃圾邮件的分类器,但是你却对它们内部的工作流程一无所知。事实上,许多场合你都不需要知道这些黑箱子的内部有什么,干了什么。 然而,如果你对其内部的工作流程有一定了解的话,当面对一个机器学习任务时候,这些理论可以帮助你快速的找到恰
-
问题内容: 我想知道是否有可能保存经过部分训练的Keras模型并在再次加载模型后继续进行训练。 这样做的原因是,将来我将拥有更多的训练数据,并且我不想再次对整个模型进行训练。 我正在使用的功能是: 编辑1:添加了完全正常的示例 对于10个纪元后的第一个数据集,最后一个纪元的损失将为0.0748,精度为0.9863。 保存,删除和重新加载模型后,第二个数据集上训练的模型的损失和准确性分别为0.171
-
假设我有3个简单的SparkML模型,它们将使用相同的数据帧作为输入,但彼此完全独立(在运行序列和使用的数据列中)。 我想到的第一件事是,只需使用阶段数组中的3个模型创建一个管道数组,然后运行总体拟合/变换来获得完整的预测等等。 但是,我的理解是,因为我们将这些模型作为序列堆叠在单个管道中,Spark不一定会并行运行这些模型,即使它们彼此完全独立。 也就是说,有没有办法并行拟合/转换3个独立模型?
-
问题内容: 我有一个训练了40个时代的模型。我为每个纪元保留了检查点,并且还用保存了模型。培训代码为: 但是,当我加载模型并尝试再次对其进行训练时,它会像以前从未进行过训练一样从头开始。损失不是从上一次训练开始的。 使我感到困惑的是,当我加载模型并重新定义模型结构并使用时,效果很好。因此,我相信模型权重已加载: 但是,当我继续进行此训练时,损失与初始阶段一样高: 我在这里和这里搜索并找到了一些保存
-
大家已经提到了这个,这个,这个和这个,但是仍然发现很难建立一个自定义的名字查找器模型。。以下是代码: 我在尝试执行命令行时不断出现错误: 让我把论点1改为 然后我收到一个运行时错误,说你不能强制转换这个。这是我在线程“main”中强制转换 第二个问题是: 给出一个语法错误。不确定这里出了什么问题。如果有任何帮助,我将不胜感激,因为我已经尝试了上述链接上的所有代码片段。 祝好