
CatBoost 是由 Yandex 的研究人员和工程师开发的基于梯度提升决策树的机器学习方法,现已开源。CatBoost 在 Yandex 公司内广泛使用,用于排列任务、预测和提出建议。
CatBoost 是通用的,可应用于广泛的领域和各种各样的问题。

对比:
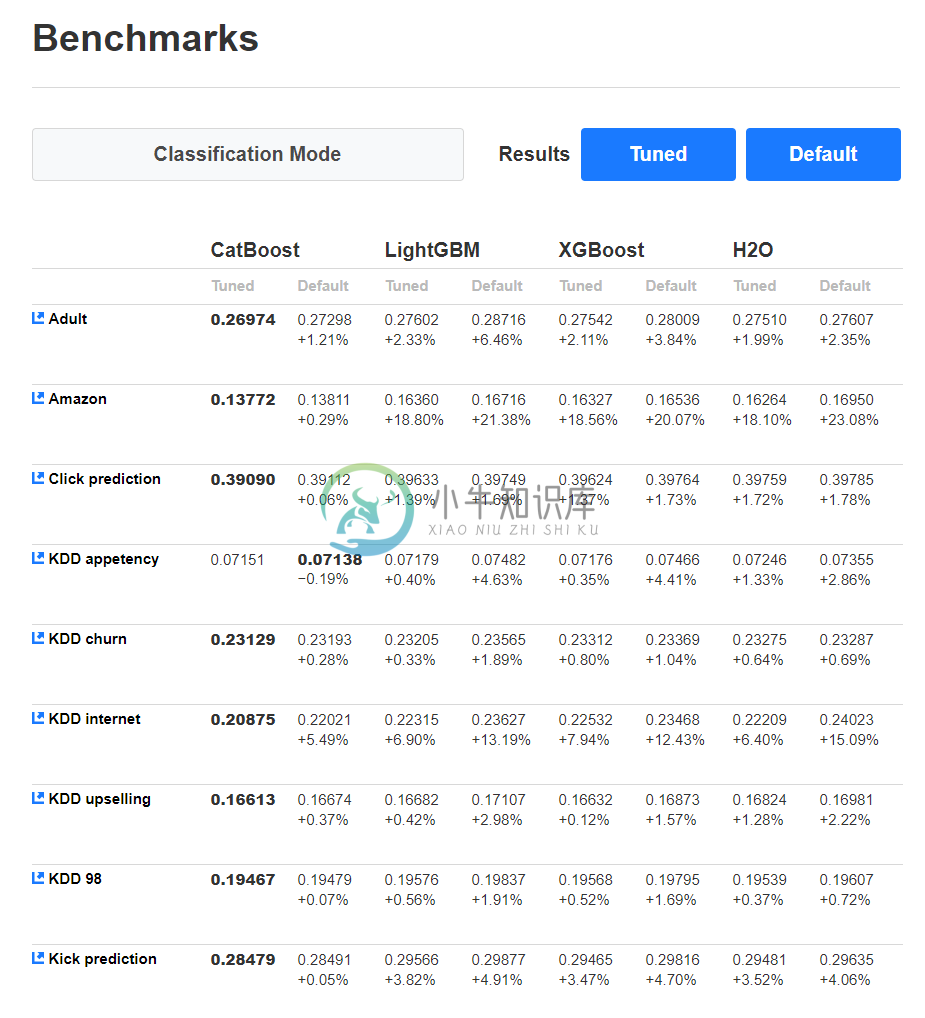
-
CatBoost是一种基于对称决策树(oblivious trees)为基学习器实现的参数较少、支持类别型变量和高准确性的GBDT框架,主要解决的痛点是高效合理地处理类别型特征,这一点从它的名字中可以看出来,CatBoost是由Categorical和Boosting组成。此外,CatBoost还解决了梯度偏差(Gradient Bias)以及预测偏移(Prediction shift)的问题,从
-
ML之catboost:catboost的CatBoostRegressor函数源代码简介、解读之详细攻略 目录 catboost的CatBoostRegressor函数源代码简介、解读 catboost的CatBoostRegressor函数源代码简介、解读 class CatBoostRegressor Found at: catboost.core class CatBoostRegress
-
GBDT也是集成学习Boosting家族的成员,但是却和传统的Adaboost有很大的不同。回顾下Adaboost,我们是利用前一轮迭代弱学习器的误差率来更新训练集的权重,这样一轮轮的迭代下去。GBDT也是迭代,使用了前向分布算法,但是弱学习器限定了只能使用CART回归树模型,同时迭代思路和Adaboost也有所不同。 在GBDT的迭代中,假设我们前一轮迭代得到的强学习器是$$f_{t-1}(x)
-
1 Boosting Boosting是一类将弱学习器提升为强学习器的算法。这类算法的工作机制类似:先从初始训练集中训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注。 然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器的数目达到事先指定的值T,最终将这T个基学习器进行加权结合。 Boost算法是在算法开始
-
本文向大家介绍Python机器学习之决策树算法,包括了Python机器学习之决策树算法的使用技巧和注意事项,需要的朋友参考一下 一、决策树原理 决策树是用样本的属性作为结点,用属性的取值作为分支的树结构。 决策树的根结点是所有样本中信息量最大的属性。树的中间结点是该结点为根的子树所包含的样本子集中信息量最大的属性。决策树的叶结点是样本的类别值。决策树是一种知识表示形式,它是对所有样本数据的高度概括
-
贝叶斯分类:贝叶斯分类是一类分类算法的总称,这类算法均已贝叶斯定理为基础,故统称为贝叶斯分类。 先验概率:根据以往经验和分析得到的概率。我们用 \small P(Y) 来代表在没有训练数据前假设\small Y拥有的初始概率。 后验概率:根据已经发生的事件来分析得到的概率。以 \small P(Y|X) 代表假设\small X 成立的情下观察到 \small Y数据的概率,因为它反映了在看到训练数据\small X后\small Y成立的置信度。
-
迭代与梯度下降求解 求导解法在复杂实际问题中很难计算。迭代法通过从一个初始估计出发寻找一系列近似解来解决优化问题。其基本形式如下
-
本文向大家介绍Python机器学习之决策树算法实例详解,包括了Python机器学习之决策树算法实例详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python机器学习之决策树算法。分享给大家供大家参考,具体如下: 决策树学习是应用最广泛的归纳推理算法之一,是一种逼近离散值目标函数的方法,在这种方法中学习到的函数被表示为一棵决策树。决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,
-
前面那些值函数的方法,当值函数最优时,可以获得最优策略。最优策略是状态 s 下,最大行为值函数对应的动作。当动作空间很大的时候,或者是动作为连续集的时候,基于值函数的方法便无法有效求解了。因为基于值函数的方法在策略改进时,需要针对每个状态行为对求取行为值函数,以便求解 arg\,\underset{a\in A}{max}\,Q(s,a)。这种情况下,把每一个状态行为对严格独立出来,求取某个状态下应该执行的行为是不切实际的。
-
在求期望时,需要对状态分布和动作分布进行积分。这就要求在状态空间和动作空间采集大量的样本,这样得到的均值才能近似期望。 而确定性策略的动作是确定的,所以在确定性策略梯度存在的情况下,对确定性策略梯度的求解不需要在动作空间进行采样积分。因此,相比于随机策略方法,确定性策略需要的样本数据要小,确定性策略方法的效率比随机策略的效率高很多,这也是确定性策略方法的主要优点。