
Weka软件决策树

安装Weka 3.8后,加载a。在Explorer中,我想用参数“use training set”构建一个决策树。
安装一切正常(64位Windows的自解压可执行文件,包括Oracle的64位Java VM 1.8)
文件加载良好,与之前使用excel保存时一样,以coma分隔。问题在于构建决策树本身:我进入分类选项卡,选择测试选项“使用训练集”,然后开始。
开始后,会出现一个特定的结果,根据我之前看到的一些图像,应该允许右键单击并选择“可视化树”。
这不会发生,如下图所示:
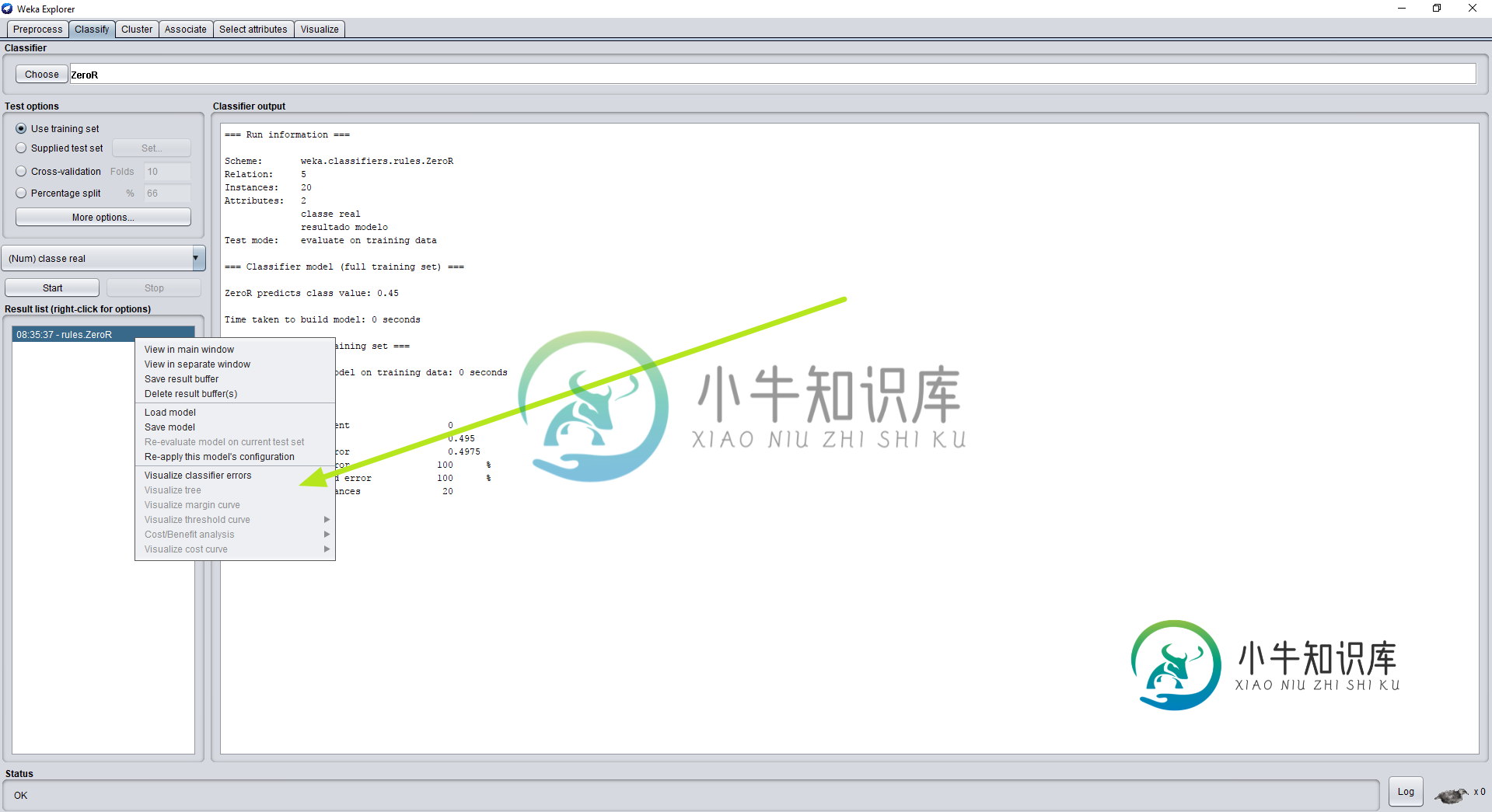
如何修复此问题以构建决策树?
共有1个答案

您已经运行了ZeroR分类器,请参阅http://chem-eng.utoronto.ca/~datamining/dmc/zeror.htm.ZeroR分类器不是分解树分类器,因此无法可视化。您需要训练一个实际的分解树分类器,J48就是其中之一。有关如何操作的指南,请参阅http://facweb.cs.depaul.edu/mobasher/classes/ect584/WEKA/classify.html。
-
决策树 概述 决策树(Decision Tree)算法是一种基本的分类与回归方法,是最经常使用的数据挖掘算法之一。我们这章节只讨论用于分类的决策树。 决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是 if-then 规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。 决策树学习通常包括 3 个步骤:特征选择、决策树的生成和决策树的修剪。 决策树 场景
-
决策树是一种常见的机器学习方法,它基于二元划分策略(类似于二叉树),如下图所示 一棵决策树包括一个根节点、若干个内部节点和若干个叶节点。叶节点对应决策的结果,而其他节点对应一个属性测试。决策树学习的目的就是构建一棵泛化能力强的决策树。决策树算法的优点包括 算法比较简单; 理论易于理解; 对噪声数据有很好的健壮性。 使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选
-
条件/决策构造在执行指令之前评估条件。如下图所示: Dart中的条件结构分类如下表中所示 - 编号 条件语句 描述 1 if语句 语句由一个布尔表达式后跟一个或多个语句组成。 2 if…else语句 后面跟一个可选的块。如果块测试的布尔表达式求值为,则执行块。 3 else…if语句 可用于测试多个条件。 4 switch…case语句 switch语句计算表达式,将表达式的值与子句匹配,并执行与
-
接下来就要讲决策树了,这是一类很简单但很灵活的算法。首先要考虑决策树所具有的非线性/基于区域(region-based)的本质,然后要定义和对比基于区域算则的损失函数,最后总结一下这类方法的具体优势和不足。讲完了这些基本内容之后,接下来再讲解通过决策树而实现的各种集成学习方法,这些技术很适合这些场景。 1 非线性(Non-linearity) 决策树是我们要讲到的第一种内在非线性的机器学习技术(i
-
和支持向量机一样, 决策树是一种多功能机器学习算法, 即可以执行分类任务也可以执行回归任务, 甚至包括多输出(multioutput)任务. 它是一种功能很强大的算法,可以对很复杂的数据集进行拟合。例如,在第二章中我们对加利福尼亚住房数据集使用决策树回归模型进行训练,就很好的拟合了数据集(实际上是过拟合)。 决策树也是随机森林的基本组成部分(见第 7 章),而随机森林是当今最强大的机器学习算法之一
-
{% raw %} 六、决策树 和支持向量机一样, 决策树是一种多功能机器学习算法, 即可以执行分类任务也可以执行回归任务, 甚至包括多输出(multioutput)任务. 它是一种功能很强大的算法,可以对很复杂的数据集进行拟合。例如,在第二章中我们对加利福尼亚住房数据集使用决策树回归模型进行训练,就很好的拟合了数据集(实际上是过拟合)。 决策树也是随机森林的基本组成部分(见第 7 章),而随机森