
标签决策树

我需要做一个决策树,并通过图形上的标签来表示数据(如两个插图所示)。我对决策树没有问题,不幸的是,点没有输入图形中。我尝试了代码中的几个变化。代码来自Scikit Learning网站在iris数据集上绘制决策树的决策面
下面有一个使用的数据示例(X、Y、C5)(来自Excel文件):
Path = "Documents/Apprentissage/Python/Script/ClustAllRepres12.xlsx"
Wordbook = xlrd.open_workbook(Path)
Sheet = Wordbook.sheet_by_index(0)
X=[]
Y=[]
C5=[]
for i in range(1, Sheet.nrows):
X.append(Sheet.cell_value(i, 0))
Y.append(Sheet.cell_value(i, 1))
C5.append(Sheet.cell_value(i, 8))
X
输出[]:[8.0、9.0、9.0、9.0、9.0、10.0、10.0、11.0、11.0、11.0、11.0、12.0、12.0、12.0、12.0、13.0、13.0、13.0、14.0、14.0、15.0、15.0、15.0、15.0、16.0、16.0、17.0、17.0、17.0、18.0 18.0、18.0、18.0、18.0、19.0、19.0、19.0、19.0、19.0、19.0、20.0、21.0、21.0、22.0]
type(X)
输出[]:列表
Y
输出[]:[45.0、17.0、18.0、24.0、25.0、27.0、36.0、38.0、39.0、24.0、37.0、40.0、24.0、31.0、35.0、36.0、37.0、39.0、32.0、33.0、35.0、43.0、27.0、31.0、35.0、42.0、42.0、28.0、32.0、35.0、43.0、51.0 52.0、17.0、19.0、53.0、49.0、51.0、53.0、58.0、16.0、58.0、59.0、50.0、52.0、54.0]
type(Y)
输出[]:列表
C5
出[]:[2.0, 4.0, 3.0, 3.0, 3.0, 4.0, 3.0, 3.0, 3.0, 3.0, 3.0, 3.0, 3.0, 3.0, 3.0, 3.0, 3.0, 3.0, 3.0, 1.0, 4.0, 1.0, 3.0, 1.0, 1.0, 1.0, 1.0, 3.0, 1.0, 3.0, 1.0, 5.0, 1.0, 3.0, 1.0, 1.0, 4.0, 4.0, 4.0, 1.0, 5.0, 1.0, 5.0, 2.0, 5.0, 5.0, 5.0, 5.0, 5.0, 5.0]
type(C5)
输出[]:列表
有来自Scikit学习网站的代码:
import pandas as pd
import numpy as np
import xlrd
import matplotlib.pyplot as plt
df_list = pd.DataFrame(
{'X': X,
'Y': Y,
})
df = df_list.iloc[:,0:2].values #transform to float type
import sklearn
from sklearn.tree import DecisionTreeClassifier, plot_tree
#parameters
n_classes = 5
plot_colors = "ryb"
plot_step = 0.02
for pairidx, pair in enumerate([[0, 1], [0, 2], [0, 3],[1, 2], [1, 3], [2, 3]]):
# We only take the two corresponding features
X = df #gives better result without [:, pair]
y = C5
#train
clf = DecisionTreeClassifier().fit(X, y)
#plot the decision boundary
plt.subplot(2, 3, pairidx +1)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),
np.arange(y_min, y_max, plot_step))
plt.tight_layout(h_pad=0.5, w_pad=0.5, pad=2.5)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.RdYlBu)
# Plot the training points
for i, color in zip(range(n_classes), plot_colors):
idx = np.where(y == i)
plt.scatter(X[idx, 0], X[idx, 1], c=color, label=C5[i],
cmap=plt.cm.RdYlBu, edgecolor='black', s=15)
plt.suptitle("Decision surface of a decision tree using paired features")
plt.legend(loc='lower right', borderpad=0, handletextpad=0)
plt.axis("tight")
plt.figure()
clf = DecisionTreeClassifier().fit(df_list, C5)
plot_tree(clf, filled=True)
plt.show()
这是我的图表:
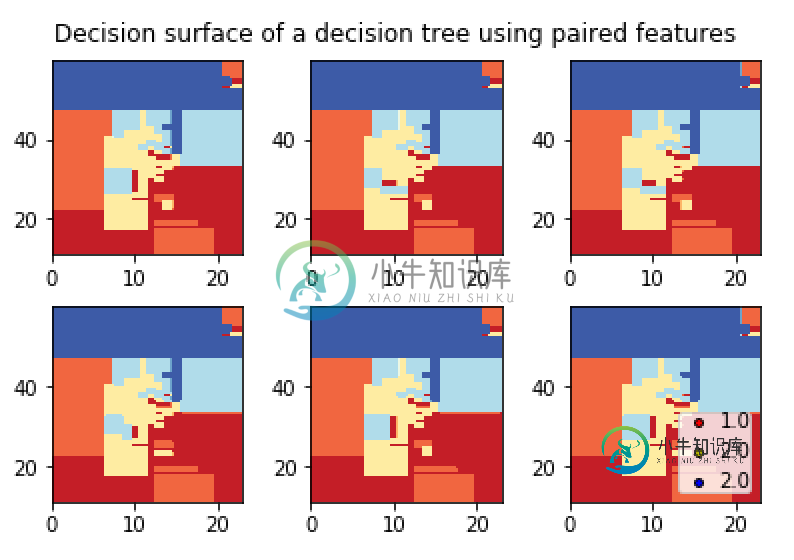
如你所见,这些点在图中没有表示出来。我举了一个等待结果的例子:
共有1个答案

idx=np。式中(y==i)
在这一行中,y是一个列表,用于返回等于i(变量)的列表索引,只需将其转换为列表以进行数组即可,一切正常
所以只需在绘制散点图之前添加这条线
**y = np.asarray(y)** # convert list to array since where will work for array only
# Plot the training points
for i, color in .....
-
决策树 概述 决策树(Decision Tree)算法是一种基本的分类与回归方法,是最经常使用的数据挖掘算法之一。我们这章节只讨论用于分类的决策树。 决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是 if-then 规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。 决策树学习通常包括 3 个步骤:特征选择、决策树的生成和决策树的修剪。 决策树 场景
-
决策树是一种常见的机器学习方法,它基于二元划分策略(类似于二叉树),如下图所示 一棵决策树包括一个根节点、若干个内部节点和若干个叶节点。叶节点对应决策的结果,而其他节点对应一个属性测试。决策树学习的目的就是构建一棵泛化能力强的决策树。决策树算法的优点包括 算法比较简单; 理论易于理解; 对噪声数据有很好的健壮性。 使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选
-
接下来就要讲决策树了,这是一类很简单但很灵活的算法。首先要考虑决策树所具有的非线性/基于区域(region-based)的本质,然后要定义和对比基于区域算则的损失函数,最后总结一下这类方法的具体优势和不足。讲完了这些基本内容之后,接下来再讲解通过决策树而实现的各种集成学习方法,这些技术很适合这些场景。 1 非线性(Non-linearity) 决策树是我们要讲到的第一种内在非线性的机器学习技术(i
-
和支持向量机一样, 决策树是一种多功能机器学习算法, 即可以执行分类任务也可以执行回归任务, 甚至包括多输出(multioutput)任务. 它是一种功能很强大的算法,可以对很复杂的数据集进行拟合。例如,在第二章中我们对加利福尼亚住房数据集使用决策树回归模型进行训练,就很好的拟合了数据集(实际上是过拟合)。 决策树也是随机森林的基本组成部分(见第 7 章),而随机森林是当今最强大的机器学习算法之一
-
{% raw %} 六、决策树 和支持向量机一样, 决策树是一种多功能机器学习算法, 即可以执行分类任务也可以执行回归任务, 甚至包括多输出(multioutput)任务. 它是一种功能很强大的算法,可以对很复杂的数据集进行拟合。例如,在第二章中我们对加利福尼亚住房数据集使用决策树回归模型进行训练,就很好的拟合了数据集(实际上是过拟合)。 决策树也是随机森林的基本组成部分(见第 7 章),而随机森
-
校验者: @文谊 @皮卡乒的皮卡乓 翻译者: @I Remember Decision Trees (DTs) 是一种用来 classification 和 regression 的无参监督学习方法。其目的是创建一种模型从数据特征中学习简单的决策规则来预测一个目标变量的值。 例如,在下面的图片中,决策树通过if-then-else的决策规则来学习数据从而估测数一个正弦图像。决策树越深入,决策规则就