
NanoDet 是一个超快速和轻量级的 anchor-free 物体检测模型。在移动设备上是实时的。

特性:
- 超级轻量级:模型文件只有 980KB(INT8)或 1.8MB(FP16)。
- 超级快:在移动 ARM CPU 上为 97fps(10.23ms)。
- 训练友好:比其他模型低得多的GPU内存成本。在GTX1060 6G上可以使用批量大小=80。
- 易于部署:提供带有各种后端的C++实现,以及基于ncnn推理框架的Android演示。
Benchmarks
| Model | Resolution | COCO mAP | Latency(ARM 4 Threads) | FLOPS | Params | Model Size |
|---|---|---|---|---|---|---|
| NanoDet-m | 320*320 | 20.6 | 10.23ms | 0.72G | 0.95M | 1.8MB(FP16) | 980KB(INT8) |
| NanoDet-m | 416*416 | 23.5 | 16.44ms | 1.2G | 0.95M | 1.8MB(FP16) | 980KB(INT8) |
| NanoDet-m-1.5x | 320*320 | 23.5 | 13.53ms | 1.44G | 2.08M | 3.9MB(FP16) | 2MB(INT8) |
| NanoDet-m-1.5x | 416*416 | 26.8 | 21.53ms | 2.42G | 2.08M | 3.9MB(FP16) | 2MB(INT8) |
| NanoDet-g | 416*416 | 22.9 | Not Designed For ARM | 4.2G | 3.81M | 7.7MB(FP16) | 3.6MB(INT8) |
| YoloV3-Tiny | 416*416 | 16.6 | 37.6ms | 5.62G | 8.86M | 33.7MB |
| YoloV4-Tiny | 416*416 | 21.7 | 32.81ms | 6.96G | 6.06M | 23.0MB |
查看更多:Model Zoo
NanoDet 是一种 FCOS 风格的 one-stage anchor-free 物体检测模型,它使用 ATSS 进行目标采样,使用 Generalized Focal Loss 进行分类和 box regression。
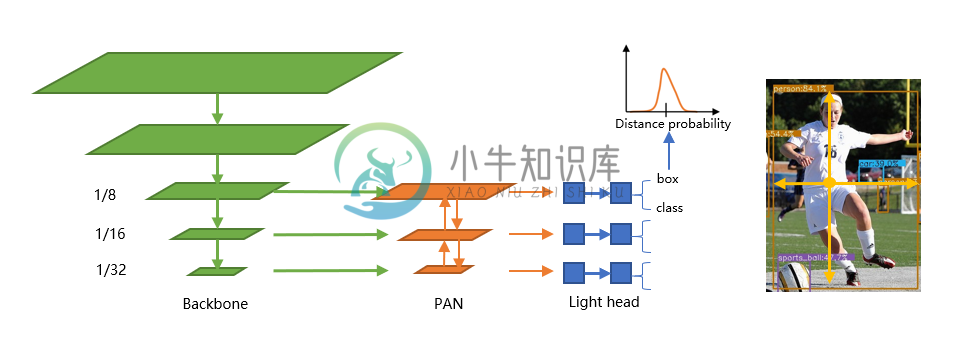
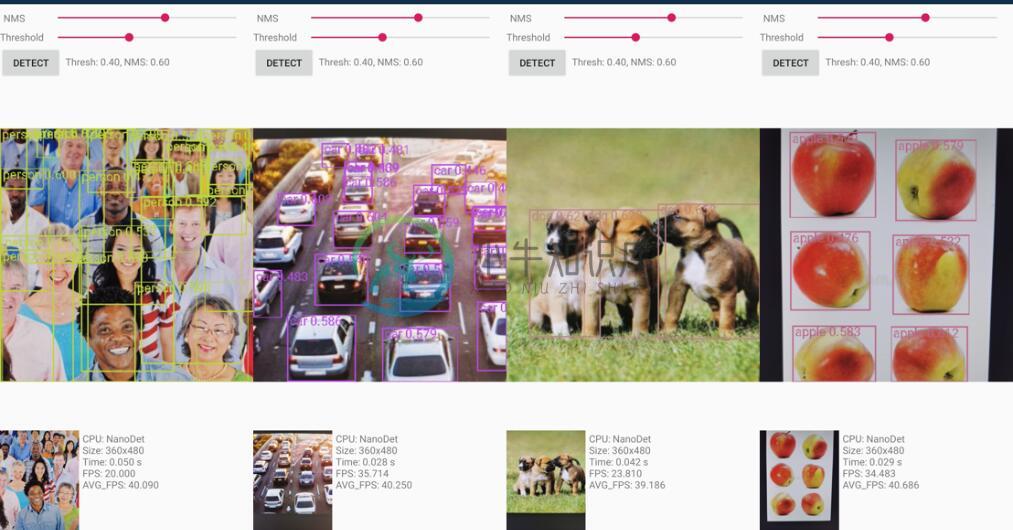
-
一、前言 出于某些需要,阅读一下anchor-free模型的代码,因为之前用过nanodet,对其印象深刻,所以重温一下代码。好记性不如烂笔头,多记录、多总结、多分享。 正如作者博客说的:NanoDet总体而言没有特别多的创新点,是一个纯工程化的项目,主要的工作就是将目前学术界的一些优秀论文,落地到移动端的轻量级模型上。 二、正文 1. 模型整体特点 模型之所以轻量,是因为作者用了 ① 轻量的ba
-
读取数据集 和 annotation 用的是COCO数据集 annotation如下,用的是instances_train2017.json
-
NanoDet是一个轻量化的目标检测算法,比yolo要快,github地址 本文结合FCOS paper解读NanoDet的ncnn代码 input size: (416, 416) 预处理: mean_vals = { 103.53f, 116.28f, 123.675f } norm_vals = { 0.017429f, 0.017507f, 0.017125f } 用均值和方差归一化,得到
-
引言 这篇文档会介绍如何用 darknet 训练一个 YOLOv2 目标检测模型,看完这篇文档会发现:模型训练和预测都非常简单,最花时间的精力的往往是训练集的数据预处理。 这里先简单介绍一下 目标分类 (Classification) 和 目标检测 (Detection) 的区别?什么是 YOLO?以及什么是 darknet? 下面这张图很清晰地说明了目标分类: 一张图片作为输入,然后模型就会告诉
-
@subpage tutorial_py_face_detection_cn 人脸识别 使用 haar-cascades
-
在“锚框”一节中,我们在实验中以输入图像的每个像素为中心生成多个锚框。这些锚框是对输入图像不同区域的采样。然而,如果以图像每个像素为中心都生成锚框,很容易生成过多锚框而造成计算量过大。举个例子,假设输入图像的高和宽分别为561像素和728像素,如果以每个像素为中心生成5个不同形状的锚框,那么一张图像上则需要标注并预测200多万个锚框($561 \times 728 \times 5$)。 减少锚框
-
在前面的一些章节中,我们介绍了诸多用于图像分类的模型。在图像分类任务里,我们假设图像里只有一个主体目标,并关注如何识别该目标的类别。然而,很多时候图像里有多个我们感兴趣的目标,我们不仅想知道它们的类别,还想得到它们在图像中的具体位置。在计算机视觉里,我们将这类任务称为目标检测(object detection)或物体检测。 目标检测在多个领域中被广泛使用。例如,在无人驾驶里,我们需要通过识别拍摄到
-
我正在尝试在Android上应用一个自定义的对象检测模型。为了应用该模型,我使用/lite/examples/object_detection下的tensorflow存储库示例。为此我也在使用我的个人手机(小米红米Note 8 pro,Android10)进行测试。该示例工作完美,能够识别不同的对象。但是,当我尝试导入自定义模型时,applycation会反复崩溃。为了运行我在build.grad
-
在目标检测领域并没有类似MNIST或Fashion-MNIST那样的小数据集。为了快速测试模型,我们合成了一个小的数据集。我们首先使用一个开源的皮卡丘3D模型生成了1000张不同角度和大小的皮卡丘图像。然后我们收集了一系列背景图像,并在每张图的随机位置放置一张随机的皮卡丘图像。我们使用MXNet提供的im2rec工具将图像转换成二进制的RecordIO格式 [1]。该格式既可以降低数据集在磁盘上的
-
问题内容: 我正在使用Selenium 2 Java API与网页进行交互。我的问题是:如何检测链接目标的内容类型? 基本上,这是背景:单击链接之前,我想确保响应是HTML文件。如果没有,我需要以其他方式处理它。因此,假设有一个PDF文件的下载链接。应用程序应直接读取该URL的内容,而不是在浏览器中打开它。 我们的目标是拥有一个能够自动知道当前位置是HTML,PDF,XML或其他类型的应用程序,以
-
问题内容: 我有一个根视图控制器,没有将其设置为故事板上的任何视图控制器的自定义类。相反,我所有的视图控制器都将此类子类化。 但是,当在视图控制器上按下tabbaritem时,我似乎正在做某事,该控件是rootviewcontroller的子类,即消息未打印。 问题答案: 您不希望视图控制器的基类是UITabBarDelegate。如果要这样做,则所有视图控制器子类都将是标签栏委托。我认为您想要做