
分支目标缓冲区检测到哪些分支预测失误?

我目前正在查看CPU管道中可以检测分支错误预测的各个部分。我发现这些是:
- 分支目标缓冲区(BPU CLEAR)
- 分支地址计算器(BA CLEAR)
- 跳转执行单元(不确定此处的信号名称??)
我知道2和3检测到什么,但我不知道BTB中检测到什么预测失误。BAC检测BTB错误地预测了非分支指令的分支,BTB未能检测到分支,或者BTB错误预测了x86 RET指令的目标地址。执行单元评估分支并确定它是否正确。
在分支目标缓冲区检测到什么类型的错误预测?这里到底检测到什么是错误预测?
我能找到的唯一线索是《英特尔开发人员手册》第三卷(底部的两个BPU CLEAR事件计数器):

BPU在错误地假设未执行分支后预测了执行的分支。
这似乎意味着预测不是“同步”完成的,而是“异步”完成的,因此“在错误地假设之后”??
更新:
Ross,这是CPU分支电路,来自原始英特尔专利(如何“阅读”?):
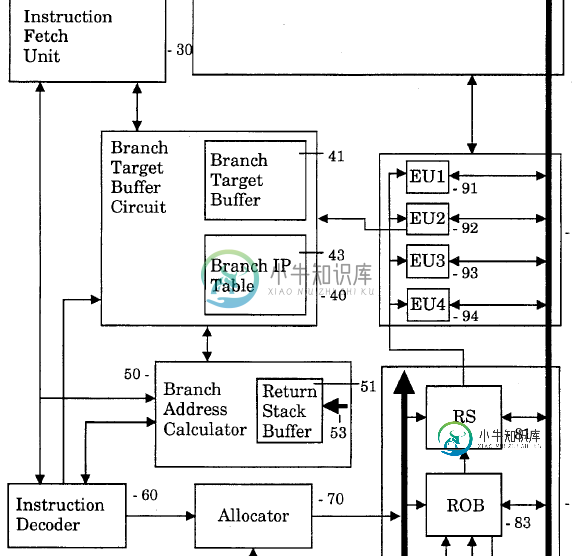
我没有在任何地方看到“分支预测单元”?有人读过这篇论文后会认为“BPU”是将BTB赛道、BTB高速公路、BAC和RSB归在一起的一种懒惰的方式,这合理吗??
因此,我的问题仍然存在,哪一个组成部分提出了BPU清晰的信号?
共有2个答案

事实BPU_CLEARS.EARLY描述显示,当BPU预测时,这个事件就会发生,纠正一个假设,暗示前端有3个阶段。假设、预测和计算。我目前的猜测是,一个早期的清除正在冲洗管道的阶段,这些阶段早于L1 BTB的预测是已知的阶段,当预测是“采取”而不是没有采取的时候。
BTB集包含4种方式,每16字节最多有4个分支(其中集合中的所有方式都使用相同的标签进行标记,指示特定的16字节对齐块)。每种方式都有一个偏移量,指示地址的4个LSB,因此是16字节内的字节位置。每个条目还具有推测位、有效位、pLRU位、推测本地BHR、真实本地BHR,并且每种方式共享集合BPT(PHT)作为第二级预测。这可以与GHR/推测GHR混合。
我认为BPU为uop缓存和指令缓存提供了64B的预测块(以前是32B,在P6上是16B)。对于传统路由,它需要提供64(或32/16)字节的预测块,该预测块是一组64位掩码,其标记预测的分支指令、预测方向以及哪个字节是分支目标。该信息将由L1 BTB提供,同时对64字节行的获取正在进行中,使得从其读出的完全没有使用位的16字节对齐(IFU一直是16B)的块将不会被指令预解码器获取(未使用是默认的,因为在预测块小于行大小的架构上,BPU可能仅提供行的16或32B的位掩码)。因此,BPU提供预测生成掩码、已用/未用掩码(将第一预测块中第一次执行分支之后和第二预测块中分支目标之前的字节标记为未用,其余的使用)、预测方向掩码;并且ILD提供分支指令掩码。预测块中第一个使用的字节是从uop高速缓存(DSP)到传统管道(MITE)的重新定位或切换后的分支目标或指令流的开始。预测块内的已用字节构成预测窗口。
这是一条P6管道。以此为例,早期清除是在第三个周期(13)进行预测(读取目标和条目类型,因此无条件分支目标以及条件分支目标及其预测)。使用16字节块集合中第一个预测的执行分支目标。此时,之前的两个管道阶段已经充满了从下一个连续16字节块中提取和开始查找的内容,这意味着如果有任何已采取的预测,则需要刷新这些内容(否则就不需要刷新,因为下一个顺序16字节块已经开始在之前的管道阶段中查找),从而留下2个周期间隔或气泡。缓存查找与BTB查找同时进行,因此必须刷新BTB和缓存并行2管道阶段,而第三阶段不需要从缓存或BTB刷新,因为IP位于已确认的路径上,并且是当前正在查找的下一个IP。事实上,在这种P6设计中,对于这种早期清除,只有一个周期的气泡,因为新的IP可以发送到第一级,在时钟的高端再次解码集合,而其他阶段正在刷新。
这种流水线比在开始查找下一个IP之前等待预测更有益。这意味着每隔一个周期进行一次查找。这将使每2个周期的预测吞吐量为16字节,因此8B/c。在P6流水线场景中,如果假设正确,吞吐量为每周期16字节,如果假设不正确,吞吐量为8B/c。显然更快。如果我们假设每9条指令中就有1条是每块4条指令的分支,那么吞吐量为每16B((1*0.666)2*0.333)=1.332个周期,而不是每2个周期16B。
如果这是真的,那么每个分支都会导致早期清除。然而,当我在KBL上使用事件时,情况并非如此。希望这个事件实际上是错误的,因为我的KBL不支持它,但它确实显示了一个随机的低数字,所以希望它在计算其他的东西。以下内容似乎也不支持这一点https://gist.github.com/mattgodbolt/4e2cbb1c9aa97e0c5478 https://github.com/mattgodbolt/agner/blob/master/tests/branch.py.考虑到900k指令和100k提前清除,如果使用我对提前清除的定义,然后查看他的代码,我看不出怎么会有奇数个提前清除。如果我们假设该CPU的窗口为32B,那么如果在该宏中的每条分支指令上使用4的对齐方式,则每8条指令就会清除一次,因为8将适合32B对齐的窗口。
我不确定为什么哈斯韦尔和常春藤桥对早期和晚期清除有这样的值,但这些事件(0xe8)从SnB开始消失,这恰好与BTB统一为单个结构的时间相吻合。看起来延迟清除计数器现在正在计算早期清除事件,因为它与 Arrandale CPU 上的早期清除数相同,而早期清除事件现在不计算任何计数。我也不确定为什么Nehalem有一个2周期的气泡用于早期清除,因为L1 Nehalem BTB的设计似乎与P6 BTB没有太大变化,两者都是512个条目,每组有4种方式。这可能是因为由于更高的时钟速度以及更长的L1i缓存延迟,它已被分解为更多阶段。
后期清除(< code > BPU _清除。晚)似乎发生在ILD。在上图中,缓存查找只需要2个周期。在最近的处理器中,显然需要4个周期。这允许插入另一个L2·BTB,并在其中进行查找。“MRU旁路”和“MRU冲突”可能只是意味着MRU BTB中存在失误,或者也可能意味着L2的预测与L1的不同,如果它使用不同的预测算法和历史文件的话。在我的不支持这两个事件的KBL上,我总是为< code > ILD _停止得到0。MRU而不是< code>BPU_CLEARS。晚。3周期气泡来自阶段5(也是ILD阶段)的BPU,它在阶段1的低边缘重定向管道,并冲洗阶段2、3和4(这与引用的4个周期的L1i延迟一致,因为L1i查找跨阶段1-4发生,用于命中ITLB命中)。一旦做出预测,BTB就用做出的预测来更新条目的推测性本地BHR位。
例如,当IQ将预测产生的掩码与预解码器产生的分支指令掩码进行比较时,会发生反向清零,然后对于某些指令类型,如相对跳转,它会检查符号位以执行静态分支预测。我想象静态预测一从预解码器进入IQ就发生,这样立即进入解码器的指令就包含静态预测。当分支指令被解码时,现在被预测为被采用的分支将导致< code > BAC clear _ FORCE _ IQ ,因为当BAC计算相对条件分支指令的绝对地址时,将没有要验证的目标,这需要在它被预测为被采用时进行验证。
解码器处的BAC还确保相对分支和直接分支在根据指令本身计算绝对地址并与之比较之后具有正确的分支目标预测,如果没有,则发出BACLEAR。对于相对跳转,如果没有进行预测,BAC中的静态预测使用跳转位移的符号位来静态预测采用/不采用,但是如果BTB不支持返回条目类型(它在P6上不支持并且不进行预测, 相反,BAC使用BPU的RSB机制,并且它是流水线中返回指令被确认的第一点),并且覆盖所有寄存器间接分支预测,如在P6上采取的(因为没有IBTB ),因为它使用了比没有采取的分支更多的分支的统计。 BAC计算来自相对目标的绝对目标并将其插入到uop中,并将IP增量插入到uop中,并将通过IP的落差(NLIP)插入到BPU的位中,该位可被标记到uop,或者更可能的是,位条目在相应的循环队列上工作,如果没有足够的位条目,该队列将停止,并且间接目标预测或已知目标被插入到uop 64位立即字段中。uop中的这些字段被分配器用于稍后分配到RS/ROB中。BAC还通知BTB任何需要从BTB解除分配其条目的虚假预测(非分支指令)。在解码器处,分支指令在逻辑的早期被检测到(当前缀被解码并且指令被检查以查看它是否能被解码器解码时),并且BAC与其余指令并行地被访问。BAC将已知或预测的目标插入到uop中被称为将auop转换成duop。预测被编码到uop操作码中。
BAC 可能会指示 BTB 针对检测到的分支指令的 IP 推测性地更新其 BTB。如果目标现在是已知的,并且没有对它进行任何预测(这意味着它不在缓存中) - 它仍然是推测性的,因为尽管分支目标是肯定的,但它仍然可能处于推测路径上,因此被标记为推测位 - 这将立即提供早期导向,特别是对于现在进入管道的无条件分支,但也用于条件, 有空白的历史,所以会预测下次不会采取,而不是等到退休)。
上面的IQ包含一个位掩码字段,用于IQ行中8个指令字节中的每个指令字节以及分支指令的目标的分支预测方向(BTBP)和分支预测/未预测(BTBH)(以区分BTBP中的哪些0未采用,而哪些0未进行预测),这意味着每条IQ行只能有一个分支,它会结束该行。此图未显示预编码器生成的分支指令掩码,该掩码显示了哪些指令实际上是分支,以便IQ知道哪些指令没有进行预测,它需要对其进行预测(哪些根本不是分支指令)。
IQ是一个连续的指令字节块,ILD填充8位位掩码,这些位掩码标识每个宏指令的第一个操作码字节(OpM)和指令结束字节(EBM ),因为它将舍入字节打包到IQ中。它可能还提供位来指示它是复杂指令还是简单指令(正如许多AMD专利上的“预解码位”所暗示的)。这些标记之间的间隙是后续指令的隐式前缀字节。我认为IQ是这样设计的,它在IDQ/ROB中发出的微操作很少会超过IQ,因此IQ中的头指针开始覆盖仍然标记在IDQ中等待分配的宏指令,当它这样做时,会有一个停顿,所以IDQ标记指回分配器访问的IQ。我认为ROB也使用这个uop标签。如果16字节* 40个条目,SnB上的IQ在最差情况下包含40个宏操作,在一般情况下包含320个宏操作,在最佳情况下包含640个宏操作。这些产生的微操作的数量会大得多,所以它很少会超过,当它超过时,我猜它会停止解码,直到更多的指令退休。尾指针包含ILD最近分配的标签,头指针包含等待退休的下一个宏指令指令,而读指针是解码器要使用的当前标签(向尾指针移动)。尽管如此,现在这变得很困难,因为路径中的一些微操作(如果不是大多数的话)来自SnB之后的微操作缓存。在微操作没有用IQ条目标记的情况下(并且IQ中的字段被直接插入微操作中),IQ可以被允许超过后端,并且这将被检测到,并且流水线将从开始重新定向。
当分配器将分支微操作的物理目的地(Pdst)分配到ROB中时,分配器将Pdst条目号提供给BPU。BPU将其插入到由BAC分配的正确的位条目中(该位条目可能在尚未被分配Pdst的有效位条目的循环队列的头部)。分配器还从uop中提取字段,并将数据分配到RS中。
RS包含一个指示指令是MSROM微操作还是常规微操作的字段,由分配器填充。分配器还将确认的绝对目标或预测的绝对目标插入到立即数据中,并作为源,重命名标志寄存器(或仅一个标志位),并且在间接分支的情况下,还有包含作为另一个源的地址的重命名寄存器。PRF方案中的Pdst将是ROB条目,作为Pdst,它将是退休宏RIP或微IP寄存器。JEU将目标或失败写入该寄存器(如果预测正确,可能不需要这样做)。
当预留站向位于整数执行单元中的跳转执行单元发送分支微操作时,预留站将相应分支微操作的Pdst条目通知BTB。作为响应,BTB访问BIT中分支指令的相应条目,并读取直通IP(NLIP),减去RS中的IP增量,然后解码为指向分支条目将被更新/分配的集合。
然后,将来自重命名标志寄存器源Pdst的结果与调度器中操作码中的预测进行比较,以确定是否采取分支,此外,如果分支是间接的,则将BIT中的预测目标与源Pdst中的地址进行比较(在调度和调度之前,该地址在RS中被计算并变得可用),现在可以知道是否做出了正确的预测以及目标是否正确。
JEU将异常代码传播到ROB并刷新管道(JEClear——它在分配阶段之前刷新整个管道,并暂停分配器),并在管道开始时适当地使用故障转移(在BIT中)/目标IP重定向下一个IP逻辑(如果是微分支预测失误,也包括微测序器;在整个MSROM程序中,指向管道起点的RIP将是相同的RIP)。投机性分录被解除分配,真实的BHR被复制到投机性BHR中。如果PRF方案中存在BOB,则BOB会为每个分支指令以及预测失误时的RAT状态拍摄快照。JEU将RAT状态回滚到该快照,分配器可以立即继续(这对于微分支预测失误特别有用,因为它离分配器更近,因此气泡不会被管道很好地隐藏),而不是暂停分配程序,并且必须等到退役时才知道退役RAT状态,并使用该状态恢复RAT,然后清除ROB(ROClear,它将取消分配程序的暂停)。对于BOB,分配器可以在过时uop继续执行的同时开始发出新指令,并且当分支准备退役时,ROClear仅清除失效预测失误和新uop之间的uop。如果是MSROM uop,因为它可能已经完成,管道的起点仍然需要再次重定向到MSROM uop,但这一次它将从重定向的microip开始(这是内联指令的情况(它可能能够在IQ外重播)。如果预测失误发生在MSROM异常中,那么它不需要重新引导管道,只需直接重定向它,因为它已经接管IDQ问题,直到过程结束——问题可能已经因内联问题而结束。
当uop退役时,响应ROB中分支异常向量的ROClear实际上发生在第二退役阶段RET2(实际上是典型退役管道的三个阶段中的第三个阶段)。当EOM uop(宏指令结束)标记失效时,宏指令仅失效,异常仅触发,宏指令RIP仅更新(使用新目标或在ROB中增加IP增量),即使非EOM指令写入它,它也不会立即写入RRF,这与其他寄存器不同,分支uop可能是解码器处理的典型分支宏指令中的最后一个uop。如果这是MSROM程序中的微分支,则不会更新BTB;它在退出时更新uIP,RIP直到过程结束才更新。
如果在 MSROM macroop 执行期间发生一般的非误判异常(即需要处理程序的异常),则一旦处理完毕,导致异常的 microip 将由处理程序恢复到 uIP 寄存器(如果调用时将其传递给处理程序),以及触发异常的宏指令的当前 RIP, 当异常处理结束时,指令获取在此 RIP uIP 处恢复:宏指令在 MSROM 中重新获取并重新尝试,MSROM 从向其发出的 uIP 开始。复杂非 MSROM 宏指令中先前的 uop 的 RRF 写入(或 PRF 方案上的停用 RAT 更新)可能发生在 EOM uop 停用之前的周期中,这意味着可以在常规复杂宏操作中的某个 uop 处重新启动,而不仅仅是 MSROM 宏操作,在这种情况下,指令流在 RIP 的 BPU 重新启动, 并且复数解码器在 PLA cuop 输出上配置了有效/无效位。用于配置复杂解码器有效位的常规复杂指令的uIP是0-3之间的值,我认为ROB在每个EOM处设置为0,并且每个微操作都递增,以便可以寻址非MSROM复杂指令,对于MSROM复杂指令,MSROM例程包含一个uop,告诉ROB该指令的uIP。然而,只有当 EOM uop 停用时,才会由 IP 增量更新的体系结构 RIP 寄存器仍然指向当前的宏操作,因为 EOM uop 未能停用),这只发生在异常而不是硬件中断的情况下,硬件中断无法中断 MSROM 过程或复杂的指令(软件中断类似,并在 EOM 处触发 -- 陷阱 MSROM 处理程序对软件陷阱处理程序的 RIP 执行宏跳跃一旦完成)。
BTB读取和标签比较发生在RET1中,同时分支单元写回结果,然后在下一个周期中,可能也在RET1期间(或者这可能在RET2中完成),比较集合中的标签,然后,如果有命中,则计算新的历史BHR;如果存在未命中,则需要在该IP上为该目标分配一个条目。只有当微操作按顺序退出(在RET2中)时,结果才能放入实际历史中,并且分支预测算法用于在需要更新时更新模式表。如果分支机构需要分配,则利用替换政策来决定分配分支机构的方式。如果有命中,那么对于所有直接和相对分支,目标将已经是正确的,所以在没有IBTB的情况下,不必进行比较。推测位现在从条目中移除(如果存在的话)。最后,在下一个周期,BTB写控制逻辑将分支写入BTB高速缓存。BTB查找的第一部分可能能够贯穿RET1进行,然后可以停止BTB写流水线,直到RET2,此时等待写入BTB的ROB条目的级退出,否则,查找可以被解耦,并且第一部分完成并将数据写入例如位,并且在RET2处,与退出的条目相对应的条目仅被写回到BTB(这将意味着再次解码该组,再次比较标签,然后写入该条目,所以可能不会)
如果P6有uop缓存,则管道将类似于:
-
< li>1H:选择IP < li>1L: BTB集解码高速缓存集解码(物理/虚拟索引)ITLB查找uop高速缓存集解码 < li>2H:缓存读取BTB读取uop缓存读取 < li>2L:缓存标签比较BTB标签比较uop缓存标签比较;如果uop缓存命中,则暂停,直到uop缓存可以发出,然后时钟门控传统解码管道 < li>3H:预测,如果采取,冲洗3H,2L,2H,1L < li >如果采用3L,则使用新IP开始1L,以解码新集合,并继续使用分支指令驻留到4L的当前16字节块
至于uop高速缓存,因为它已经过了BAC阶段,所以永远不会有伪分支或者对无条件分支的不正确预测或者对非间接分支的不正确目标。微操作高速缓存将使用来自BPU的已用/未用掩码来发出从这些字节开始的指令的微操作,并将使用预测方向掩码来将宏分支微操作改变为预测不执行/预测执行的宏分支微操作(T/NT预测被插入到微操作本身中)。如果它被预测为被采用,则它停止发出该64B对齐块(再次被用作32B,以前是16B)的微操作,并等待流水线中紧接在它后面的下一个窗口。微操作高速缓存将知道哪些微操作是分支,并且可能静态预测不采取所有非预测,或者可能具有更高级的静态预测。来自IBTB的间接目标预测被插入到uop立即字段中,然后如果该分支也被预测为被采用,它将等待下一个BPU预测块。我想uop缓存会创建位条目并更新BTB中的预测,以确保uop缓存和MITE(传统解码)UOP以正确的顺序更新历史。

这是个好问题!我认为它造成的混乱是由于英特尔奇怪的命名方案,这种方案经常使学术界的标准术语超载。我会试着回答你的问题,同时澄清我在评论中看到的混乱。
首先我同意在标准计算机科学术语中,分支目标缓冲区与分支预测器不是同义词。然而,在英特尔术语中,分支目标缓冲区(BTB)[大写]是特定的,它既包含预测器,也包含分支目标缓冲缓存(BTBC),后者只是分支指令及其在执行结果上的目标的表。大多数人将BTBC理解为分支目标缓冲区[小写]。那么什么是分支地址计算器(BAC)?如果我们有BTB,为什么需要它?
因此,您知道现代处理器被分成多个阶段的流水线。无论这是一个简单的流水线处理器还是无序的超声明处理器,第一阶段通常是先获取然后解码。在获取阶段,我们所拥有的只是程序计数器(PC)中包含的当前指令的地址。我们使用PC从内存中加载字节并将其发送到解码阶段。在大多数情况下,我们增加PC以加载后续指令,但在其他情况下我们处理控制流指令,它可以完全修改PC的内容。
BTB的目的是猜测PC中的地址是否指向分支指令,如果是这样,PC中的下一个地址应该是什么?这很好,我们可以对条件分支使用预测器,对下一个地址使用BTBC。如果预测是正确的,那就太好了!如果预测是错误的,那该怎么办?如果 BTB 是我们唯一拥有的单元,那么我们将不得不等到分支到达管道的问题/执行阶段。我们必须刷新管道并重新开始。但并非每一种情况都需要这么晚才得到解决。这就是分支地址计算器 (BAC) 的用武之地。
BTB用于管道的提取阶段,而BAC驻留在解码阶段。一旦我们获取的指令被解码,我们实际上有很多有用的信息。我们知道的第一条新信息是:“我得到的指令实际上是一个分支吗?”在获取阶段我们不知道,BTB只能猜测,但在解码阶段我们肯定知道。当指令实际上不是分支时,BTB可能预测分支;在这种情况下,BAC将停止提取单元,修复BTB,并正确重新启动提取。
像< code >无条件相对和< code >调用这样的分支呢?这些可以在解码阶段进行验证。BAC将检查BTB,查看BTBC中是否有条目,并将预测器设置为始终预测被采用。对于< code >条件分支,BAC无法确认它们是否被采用/未被采用,但它至少可以验证预测的地址,并在地址预测错误的情况下纠正BTB。有时BTB根本不会识别/预测分支。BAC需要纠正这一点,并向BTB提供有关该指令的新信息。因为BAC没有自己的条件预测器,所以它使用一个简单的机制(采用向后分支,不采用向前分支)。
有人需要确认我对这些硬件计数器的理解,但我相信它们的含义如下:
巴克利尔。当获取中的 BTB 执行了错误操作并且解码中的 BAC 可以修复它时,CLEAR 将递增。BPU_CLEARS。当 fetch 决定(错误地)加载下一条指令时,EARLY 会递增,然后 BTB 预测它应该从获取的路径实际加载。这是因为 BTB 需要多个周期,而 fetch 会利用该时间推测性地加载连续的指令块。这可能是由于英特尔使用了两个BTB,一个快速,另一个较慢但更准确。需要更多的周期才能获得更好的预测。
这解释了为什么在BTB中检测错误预测的惩罚是2/3个周期,而在BAC中检测错误预测是8个周期。
-
我的问题是它们如何在现代CPU架构中共存和协同工作?
-
如果语句更多地依赖于分支预测,而v表查找更多地依赖分支目标预测,那么
-
分支目标预测(BTP)与分支预测(BP)不同。我知道BTP会找到分支将跳转到的位置,而BP只是决定可能采取哪个分支。 BTP依赖BP吗,如果BTP不使用BP来预测哪个分支被采用,它怎么可能知道分支的目标呢? 我不明白为什么会有这么大的差异?一旦分支被预测为被占用,找到目标并不像读取指令中的地址一样简单吗?
-
编辑:我的困惑出现了,因为通过预测哪个分支,你肯定也在有效地进行目标预测?? 这个问题与我关于这个主题的第一个问题有内在联系: 分支预测与分支目标预测 无限循环 语句 或语句 语句的“then”子句结尾(跳过子句) 非虚函数调用 从函数返回 虚函数调用 函数指针调用 语句(如果编译为跳转表) 语句 语句(如果编译成一系列语句) 循环条件测试 和运算符 三元运算符 null 如果我有以下代码: (B
-
我的代码经常调用具有多个(不可预测的)分支的函数。当我分析时,我发现这是一个小瓶颈,大部分CPU时间用于条件JMP。 考虑以下两个函数,其中原始函数有多个显式分支。 这是一个新函数,我试图在其中删除导致瓶颈的分支。 然而,当我分析新代码时,性能只提高了大约20%,而且调用本身(对mem_funcs数组中的一个func)花费了很长时间。 第二个变量仅仅是一个更隐含的条件吗,因为CPU仍然无法预测将要
-
我正在编写一些音频代码,其中基本上所有内容都是一个小循环。据我所知,分支预测失败是一个足够大的性能问题,我很难保持代码分支的自由。但是只有这么远的时间才能带我,这让我想知道不同类型的分支。 在 c 中,固定目标的条件分支: 并且(如果我正确理解这个问题),无条件分支到变量目标: 是否存在性能差异?在我看来,如果这两种方法中的一种明显快于另一种,编译器只需将代码转换为匹配即可。 对于那些分支预测非常