
PaddleClas是飞桨图像分类套件,它是飞桨为工业界和学术界所准备的一个图像分类任务的工具集,助力使用者训练出更好的视觉模型和应用落地。
## CPU版本安装命令
pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle
## GPU版本安装命令
pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
丰富的模型库
基于ImageNet1k分类数据集,PaddleClas提供ResNet、ResNet_vd、Res2Net、HRNet、MobileNetV3等23种系列的分类网络结构的简单介绍、论文指标复现配置,以及在复现过程中的训练技巧。与此同时,也提供了对应的117个图像分类预训练模型,并且基于TensorRT评估了服务器端模型的GPU预测时间,以及在骁龙855(SD855)上评估了移动端模型的CPU预测时间和存储大小。
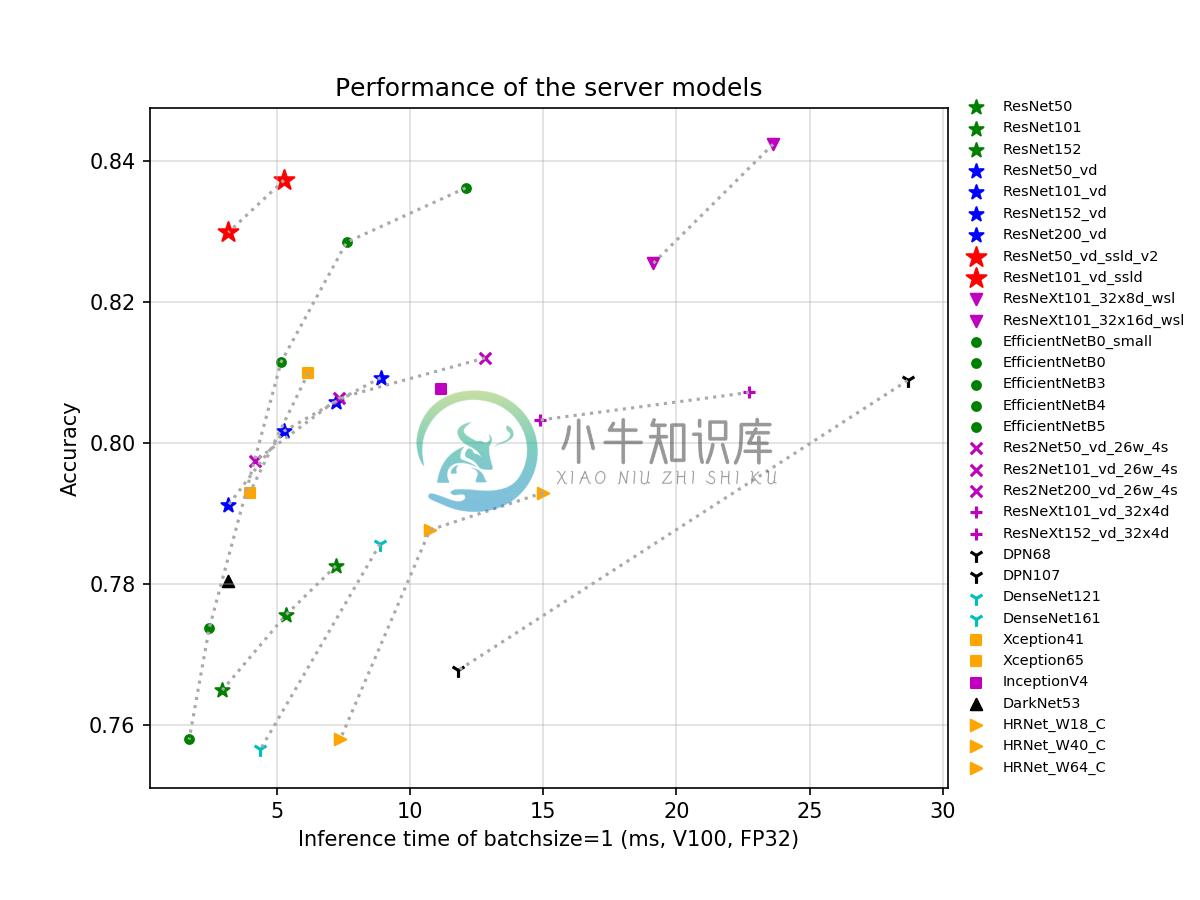
上图对比了一些最新的面向服务器端应用场景的模型,在使用V100,FP32和TensorRT,batch size为1时的预测时间及其准确率,图中准确率83.0%的ResNet50_vd_ssld_v2和83.7%的ResNet101_vd_ssld,是采用PaddleClas提供的SSLD知识蒸馏方案训练的模型,其中v2表示在训练时添加了AutoAugment数据增广策略。图中相同颜色和符号的点代表同一系列不同规模的模型。不同模型的简介、FLOPS、Parameters以及详细的GPU预测时间(包括不同batchsize的T4卡预测速度)请参考文档教程中的模型库章节。
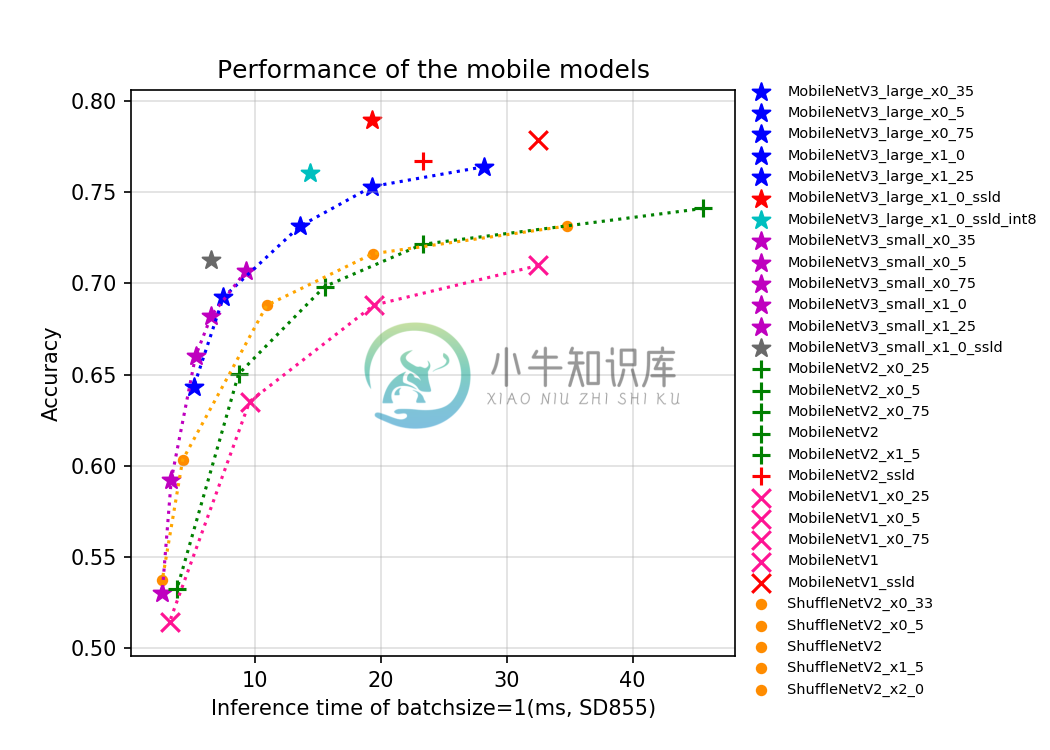
上图对比了一些最新的面向移动端应用场景的模型,在骁龙855(SD855)上预测一张图像的时间和其准确率,包括MobileNetV1系列、MobileNetV2系列、MobileNetV3系列和ShuffleNetV2系列。图中准确率79%的MV3_large_x1_0_ssld(M是MobileNet的简称),71.3%的MV3_small_x1_0_ssld、76.74%的MV2_ssld和77.89%的MV1_ssld,是采用PaddleClas提供的SSLD蒸馏方法训练的模型。MV3_large_x1_0_ssld_int8是进一步进行INT8量化的模型。不同模型的简介、FLOPS、Parameters和模型存储大小请参考文档教程中的模型库章节。
- TODO
- EfficientLite、GhostNet、RegNet、ResNeSt的论文指标复现和性能评估
高阶优化支持
除了提供丰富的分类网络结构和预训练模型,PaddleClas也支持了一系列有助于图像分类任务效果和效率提升的算法或工具。
SSLD知识蒸馏
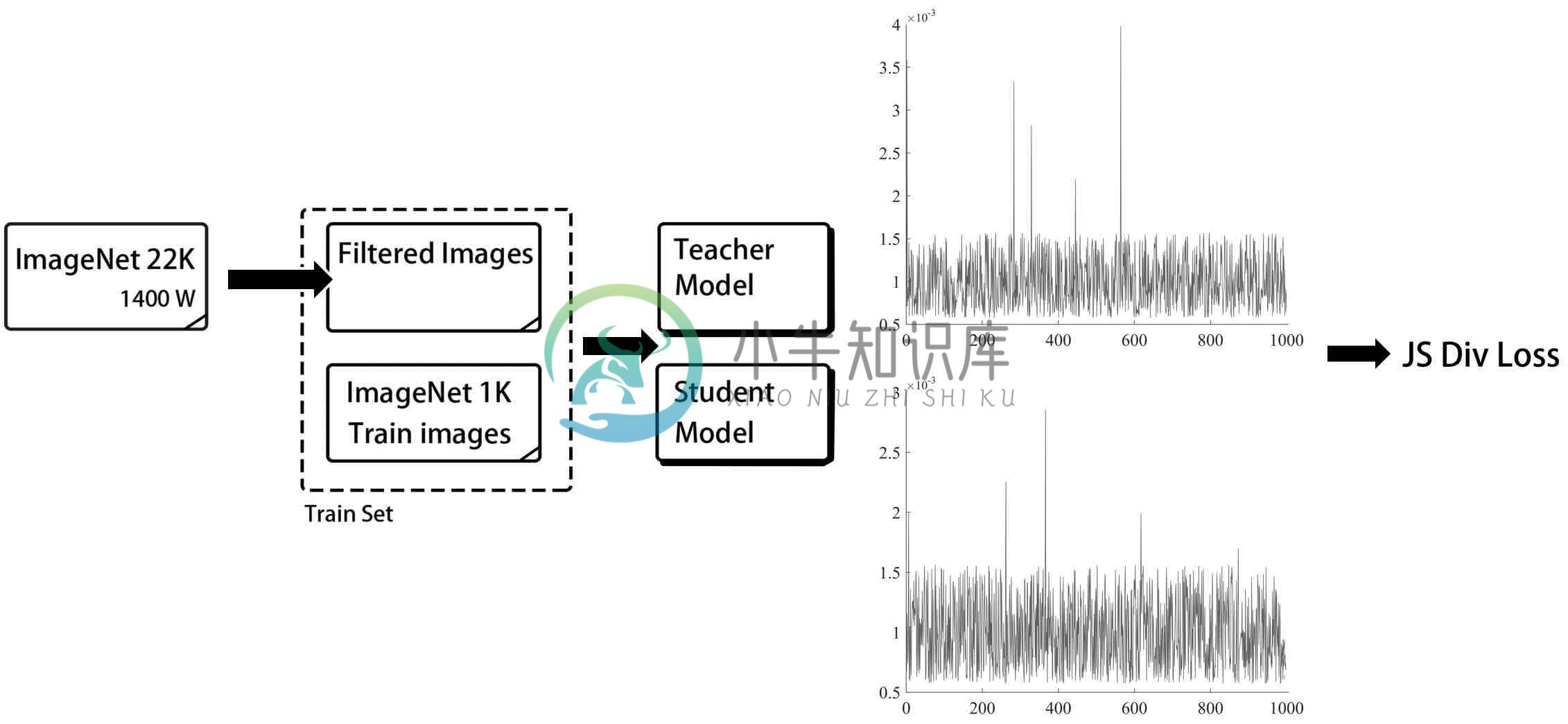
知识蒸馏是指使用教师模型(teacher model)去指导学生模型(student model)学习特定任务,保证小模型在参数量不变的情况下,得到比较大的效果提升,甚至获得与大模型相似的精度指标。PaddleClas提供了一种简单的半监督标签知识蒸馏方案(SSLD,Simple Semi-supervised Label Distillation),使用该方案,模型效果普遍提升3%以上,一些蒸馏模型提升效果如下图所示:

以在ImageNet1K蒸馏模型为例,SSLD知识蒸馏方案框架图如下,该方案的核心关键点包括教师模型的选择、loss计算方式、迭代轮数、无标签数据的使用、以及ImageNet1k蒸馏finetune,每部分的详细介绍以及实验介绍请参考文档教程中的知识蒸馏章节。
数据增广
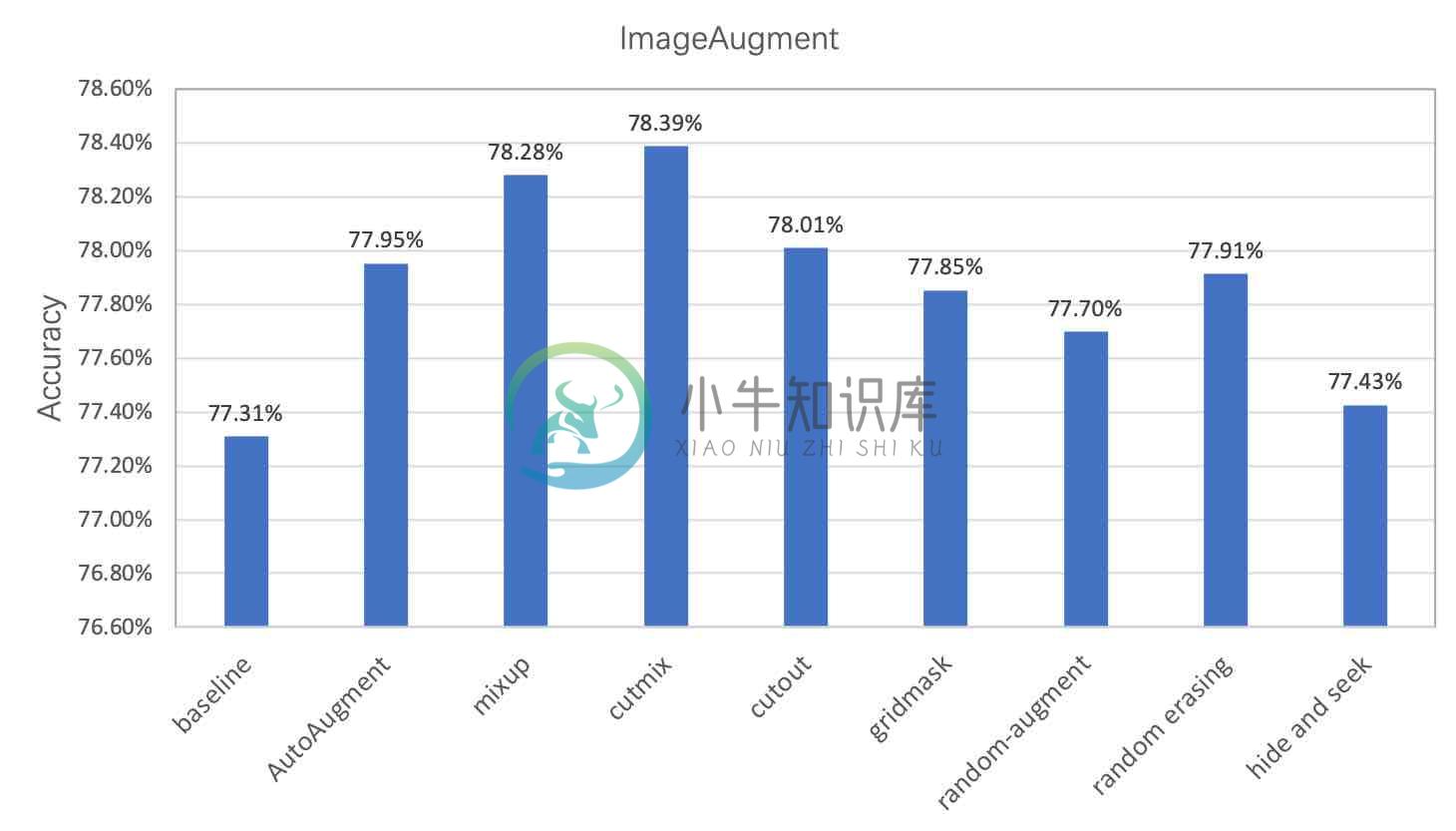
在图像分类任务中,图像数据的增广是一种常用的正则化方法,可以有效提升图像分类的效果,尤其对于数据量不足或者模型网络较大的场景。常用的数据增广可以分为3类,图像变换类、图像裁剪类和图像混叠类,如下图所示。图像变换类是指对全图进行一些变换,例如AutoAugment,RandAugment。图像裁剪类是指对图像以一定的方式遮挡部分区域的变换,例如CutOut,RandErasing,HideAndSeek,GridMask。图像混叠类是指多张图进行混叠一张新图的变换,例如Mixup,Cutmix。

PaddleClas提供了上述8种数据增广算法的复现和在统一实验环境下的效果评估。下图展示了不同数据增广方式在ResNet50上的表现, 与标准变换相比,采用数据增广,识别准确率最高可以提升1%。每种数据增广方法的详细介绍、对比的实验环境请参考文档教程中的数据增广章节。
-
0 前言 以下针对最近使用PaddleClas和PaddleServing在华为云GPU服务器上训练和部署一个车辆类型识别模型过程进行记录,以供日后自己参考和其他有需要的朋友一些帮助,接触这方面东西时间较短,如有问题欢迎批评指正。 如何在华为云服务器上搭建GPU版本的PaddlePaddle环境请参考以下文章: https://blog.csdn.net/loutengyuan/article/d
-
前言 简要记录paddleclass入门教程,便于以后使用 一、解压数据集 !unzip -q data/data68810/螺栓质量检测-训练集.zip -d ~/work/data 二、划分训练集和测试集 在研究过程中发现可用jikuai来代替一系列繁琐的工程代码 !pip install jikuai -q # 想把数据集列表放在哪里,就在哪个目录下执行下面的命令。这里我们生成数据集列表文
-
【PaddleClas】常用命令 1.生成数据集 需要修改 build_product.yaml python python/build_gallery.py -c configs/build_product.yaml -o IndexProcess.data_file="D:\Paddle\PaddleClas\out\recognition_demo_data_v1.0\gallery_sg\
-
paddleclas是paddlepaddle官方提出的用于图像分类的开源库,paddledetection是其提出用于目标检测的开源库。 在图像分类中的很多模型都可以作为backbone参与目标检测模型中,然而在paddledetection中支持的backbone仅有: blazenet、cspresnet、esnet、hrnet、lite_hrnet、mobileone、senet、conv
-
前言 最近公司需要对图片中的不同的货车品牌和车系进行识别,通过PaddleClas进行模型训练后得到一个品牌识别模型和一个车系识别模型,现在对两个模型部署到一台华为云的GPU服务器上,要对多个模型同时进行部署,只能采取PaddleServing中的 Pipeline 服务或者C++ serving服务进行部署,由于C++ serving需要编译源码,比较麻烦,所以下面采用Pipeline 方式对多
-
PaddleClas PaddleDetection使用总结 前言:关于环境搭建,我是在本地windows系统上,有3060GPU显卡,驱动和cuda版本都是适配显卡的。cuda版本是11.2。我装了conda 4.10.3,Python3.8.8 , 直接在base环境下pip install Paddlepaddle。 一 PaddleDetection-2.5.0 (我理解的是用于检测) r
-
class Reader(Dataset): ... class CTCLoss(paddle.nn.Layer): 来回报错: ValueError: (InvalidArgument) The type of data we are trying to retrieve (int32) does not match the type of data (int64) currently cont
-
我正在做一个突破克隆,在球与桨的碰撞中遇到了一些小麻烦。我用一个矩形表示球和桨,当它们相交时,表示球速度的Y向量为负数(如下所示)。这一切都很好。问题是当球拍向右移动时,我希望它将球稍微向右移动(与正常反射相反),我希望在相反方向发生相同的情况,即球拍向左移动。我不知道该怎么做,我已经找遍了。任何帮助都将不胜感激。谢谢 编辑:基本上我想根据球拍移动的方向稍微改变球从球拍上反弹的角度。如果桨叶不移动
-
我使用theme而不是layout来显示初始屏幕,但我不知道为不同的屏幕密度设置什么样的分辨率图像,因为标记的width和height属性可用API>22。 风格
-
本文向大家介绍ibm-watson-cognitive 分类图像,包括了ibm-watson-cognitive 分类图像的使用技巧和注意事项,需要的朋友参考一下 示例 先决条件 首先,您必须安装watson-developer-cloudSDK。 分类图片网址 我们将使用维基百科上的美国队长形象。
-
我正在使用飞碟从XHTML创建PNG图像文件。然后,我使用另一个工具将这些与一堆其他文本n图像一起收集到PDF中。 虽然我可以将PDF导出处理转换为iText,但这将是一项相当大的任务。。。。 我的问题是,当导出到PNG图像文件时,一些XHTML内容需要分页。我只需要在图像文件之间进行一个简单的“剪辑样式”分割就可以了。 下面是我用来将整个内容呈现到单个文件中的内容,效果很好。 然而,我的一些内容
-
我试图用python编码一个水果图像分类器,尝试分类7个水果。我有train_set的15077张图片和validation_set的4204张图片。我编译了10个时代的代码,结果如下: 在15077个样本上进行训练,在4204个样本上进行验证,历元1/10 15077/15077[=============================================]-264s 17ms/步