
hindex 是华为公司开发的纯 Java 编写的 HBase 二级索引,兼容 Apache HBase 0.94.8。
当前的特性如下:
多个表索引
多个列索引
基于部分列值的索引
使用索引扫描等于和范围条件
批量加载数据来索引表(索引完成批量加载)
工作原理
HBase 二级索引是 100% 服务端实现的。
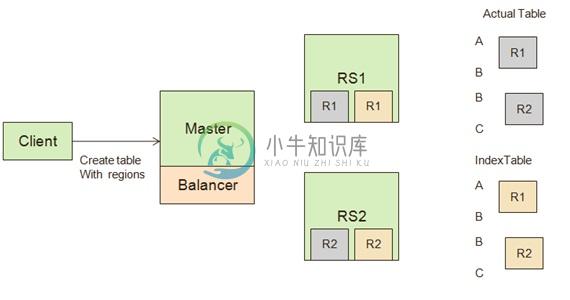
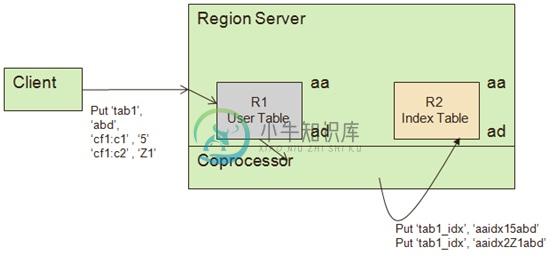
Put 操作
E.g.:
Table –> tab1 column family –> cf
Index –> idx1, cf1:c1 and idx2, cf1:c2
Index table –> tab1_idx (user table name with suffix “_idx” )
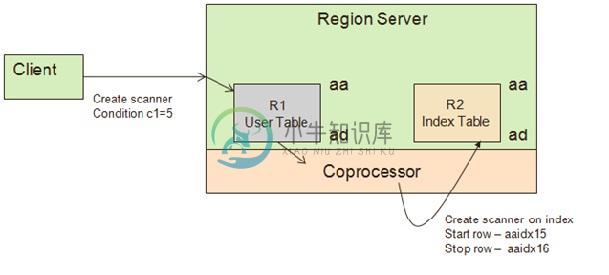
扫描操作
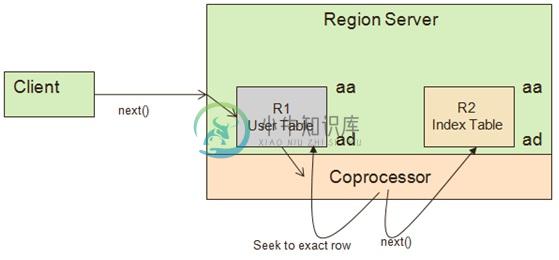
使用
IndexedHTableDescriptor htd = new IndexedHTableDescriptor(usertableName); IndexSpecification iSpec = new IndexSpecification(indexName); HColumnDescriptor hcd = new HColumnDescriptor(columnFamily); iSpec.addIndexColumn(hcd, indexColumnQualifier, ValueType.String, 10); htd.addFamily(hcd); htd.addIndex(iSpec); admin.createTable(htd);
未来会实现的功能:
动态添加和删除索引
集成 HBase Shell 的二级索引管理
优化范围扫描
HBCK 工具支持二级索引表
WAL 优化二级索引条目
使得扫描评估情报可导入导出
-
Given an array of citations (each citation is a non-negative integer) of a researcher, write a function to compute the researcher's h-index. According to the definition of h-index on Wikipedia: "A sci
-
给定一位研究者论文被引用次数的数组(被引用次数是非负整数)。编写一个方法,计算出研究者的 h 指数。 h 指数的定义: “一位有 h 指数的学者,代表他(她)的 N 篇论文中至多有 h 篇论文,分别被引用了至少 h 次,其余的 N - h 篇论文每篇被引用次数不多于 h 次。” 示例: 输入: citations = [3,0,6,1,5] 输出: 3 解释: 给定数组表示研究者总共有 5篇论文
-
华为在HBTC 2012上由其高级技术经理Anoop Sam John透露了其二级索引方案,这在业界引起极大的反响,甚至 有人认为,如果华为早点公布这个方案,hbase的某些问题早就解决了。其核心思想是保证索引表和主表在同一个 region server上。 更新:目前该方案华为已经开源,详见:https://github.com/Huawei-Hadoop/hindex 下面来对其方案做一个分析
-
H指数(h-index)是一种比较主流的科研评价方法,可用于评估研究人员的学术产出数量与学术产出水平。某人的h指数是指在其发表的N篇论文中,有h篇论文分别被引用了至少h次,其余N-h篇的引用次数均不超过h次。例如,张三发表了10篇论文,其中有5篇论文被引用次数大于等于5次,而没有6篇论文的引用次数大于等于6次,那么张三的H指数即为5。 第一种方法:实现简单,但是列表较大的话,效率较低。 ''' 输
-
之前写了一篇关于计算影响因数h-index的文章,上面提出了一种 O(n* log n) 复杂度的算法,今天的文章提出一种O(n)复杂度的方法。原始文章见这里。 问题,存在一个列表,该表内有n个数大于等于n,求n的最大值。 例如 【3,10,5,1,7】答案为3 【1,100,1000,20】答案为3 最近做了一些双向队列的算法,对列表处理有了新的感悟。通过双向列表可以
-
H-Index Total Accepted: 2684 Total Submissions: 11955 Given an array of citations (each citation is a non-negative integer) of a researcher, write a function to compute the researcher's h-index. Accor
-
Given an array of citations (each citation is a non-negative integer) of a researcher, write a function to compute the researcher's h-index. According to the definition of h-index on Wikipedia: "A sci
-
题目描述比较长,直接上链接了: https://leetcode.com/problems/h-index/ 个人认为LeetCode上的题目描述并不是很清楚,详情请查看题目中的维基百科链接。 H-Index的核心计算方法如下: 1、将某作者的所有文章的引用频次按照从大到小的位置排列 2、从前到后,
-
H-Index 原题 Given an array of citations (each citation is a non-negative integer) of a researcher, write a function to compute the researcher's h-index. According to the definition of h-index on Wiki
-
现在有这样一个问题, 求解 h-index. h-index 是一种衡量一个人论文水平的参数, 其定义为 h篇文章引用超过h. 该参数越大表明一个人的学术水平越高, 但不同行业差别巨大. 一般看来生物领域偏高。 下面考虑下面一个算法问题, 已知一个列表 citel, 记录着每篇论文的引用数, 无先后顺序. 例如 [3, 10, 5, 1, 7]. 输出为该列表的h-index : 3 (最大3篇
-
问题描述: Given an array of citations (each citation is a non-negative integer) of a researcher, write a function to compute the researcher's h-index. According to the definition of h-index on Wikipedia:
-
翻译 给定一个研究者的引用数(每个引用都是非负数)的数组,写一个函数用于计算研究者的h索引。 根据维基百科对于h-index的定义:“一个科学家有索引h,如果他或他的N篇论文至少存在h个相互引用,而且其他的N-h篇论文相互引用次数不高于h。 例如,给定citations = [3, 0, 6, 1, 5],这意味着研究者总共有5篇论文,而且每一篇论文分别收到3、0、6、1、5次相互引用。 因为研究
-
Given an array of citations (each citation is a non-negative integer) of a researcher, write a function to compute the researcher’s h-index. According to the definition of h-index on Wikipedia: “A sci
-
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 题目地址: https://leetcode.com/problems/h-index/description/ 题目描述: Given an array of citations (each citation is a non-negative integer) of a resear
-
H-Index II Total Accepted: 24331 Total Submissions: 74459 Difficulty: Medium Follow up for H-Index: What if the citations array is sorted in ascending order? Could you optimize your algorithm? Hint:
-
原题链接:274. H-Index 【思路-Java】T=O(nlogn)|M=O(1) 论文里的 h 因子判定,题目的意思可能有点晦涩。h 因子是评判学术成就的一种重要方法,h 因子越高越好,h 因子兼顾研究学术人员的学术产出数量与学术产出质量。假设一个研究者的 h 因子为 10,则表明该研究者被引用次数大于等于 10 的文章数量也应大于等于 10。 明白了 h 因子意思,我们看题目给定实例 c
-
The h-index of an author is the largest h where he has at least h papers with citations not less than h. h-index 指数类似于打游戏时的称号等级,只是这里的这个等级的评判有两个方面:1.发布的论文数量h1。 2.这h1份论文的的总引用次数h2。要求h2 >= h1。 Bobo has pu
-
Follow up for H-Index: What if the citations array is sorted in ascending order? Could you optimize your algorithm? Hint: Expected runtime complexity is in O(log n) and the input is sorted. 解题思路 二分法。
-
问题描述: Given an array of citations (each citation is a non-negative integer) of a researcher, write a function to compute the researcher’s h-index. According to the definition of h-index on Wikipedia:
-
直播流媒体协议中,HLS和RTMP协议是两大主流协议。而众所周知的原因,RTMP在许多年前就已经停止拓展和更新,因此标准一直无法支持HEVC的编码格式。目前国内的CDN还有金山云等已经对RTMP进行了标准扩展,播放器上ijkplayer也扩展了该修改。 具体FFmpeg的修改代码如下: From e40fcb1113cb1c93c48b8ef74b8aec6437f23d84 Mo
-
SDS 的二级索引支持局部二级索引与及全局二级索引,目前这两种索引都是强一致的索引 局部二级索引 使用局部二级索引必须要定义实体组键,由一个到多个表属性组成, 索引分为Lazy,Eager和Immutable三种类别 Lazy索引 -写入时同时写入索引记录,但是不会立马删除已无效的索引记录,需要等到读取时,读到无效的索引记录再删除,写效率高而读效率较低,所以此类型索引适合写多读少的场景,不支持投影
-
问题: 主键为复合哈希范围键的DynamoDB表是唯一的。这是否也延伸到二级指数? 示例: 我有一个带有post_id主键和comment_id范围键的comments DynamoDB表。此外,还有一个带有date-user_id范围键的本地辅助索引。 每个条目都是用户在发布时留下的评论。二级索引的目的是统计在特定的一天,有多少唯一的用户在一个帖子上留下了评论。 条目1:post_id:1 co
-
我希望使用DynamoDB表来请求我在查询中创建的二级索引。 从现在开始,对于我正在做的一个二级索引: 我会像这样构建我的KeyConditionExpression: 我读了一遍又一遍这份文件,但我不知道怎么做: https://docs.aws.amazon.com/fr_fr/amazondynamodb/latest/gettingstartedguide/GettingStarted.P
-
我的主键是一个名为“ID”的字段 我在表中的字段“group_number”上添加了一个辅助索引 我通过二级索引进行查询,如下所示: 然而;我得到错误“ValidationException:query condition missed key schema Element:ID” DynamoDB只允许查询主键吗?我的印象是您使用“getitem”作为主键,因为如果您使用一个主键,只有一个记录可
-
我正在研究一种寻找阳极父级的方法。我从根部开始,然后沿着叶子往下走,只要它们不是空的,不是孩子的节点。 下面是我的代码,它有点乱,因为我试着测试它看看哪里出了问题。
-
我仍然对本地二级索引的使用感到困惑。当需要LSI与GSI时,请给我具体的用例。 例如,“GenreAlbumTitle”索引应该是GSI还是LSI?https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/HowItWorks.CoreComponents.html#HowItWorks.CoreComponents.Prim
-
我是AWS DynamoDB和nosql的新手,我对表创建有问题。 我试图创建一个名为的表,具有以下属性: 用户ID(HASH) OSType(范围) MSISDN IMSI 设备ID 我不仅需要通过查询表,还需要通过以下字段查询表: MSISDN 我的逻辑如下: 通过字段查询表 在阅读了有关LSI/GSI的手册后,我很难理解如何创建表和定义这些索引。 这是我尝试使用PHP AWS SDK创建表的
-
我正在DynamoDB中创建一个表和GSI,使用以下参数,如文档所示: 是表的主键,我使用作为GSI的主键。(为了简洁起见,我删除了一些不必要的配置参数) 我正在使用以下命令查询此表: 但我一直在犯错误: "一个或多个参数值无效:条件参数类型与模式类型不匹配" 在文档中,它指定主可以是或,并且您可以在字段中设置。我正在以的形式发送,不确定这里缺少了什么。 问题是在我创建表的方式上,还是在我查询表的