
Twitter开源了数据实时分析平台Heron。
Twitter使用Storm实时分析海量数据已经有好几年了,并在2011年将其开源。该项目稍后开始在Apache基金会孵化,并在2015年秋天成为顶级项目。Storm以季度为发布周期,并且向着人们期望的稳定版前进。但一直以来,Twitter都在致力于开发替代方案Heron,因为Storm无法满足他们的实时处理需求。
Twitter现在已经用Heron完全替换了Storm。前者现在每天处理“数10TB的数据,生成数10亿输出元组”,在一个标准的单词计数测试中,“吞吐量提升了6到14倍,元组延迟降低到了原来的五到十分之一”,硬件减少了2/3。
当被问到Twitter是否会开源Heron时,Ramasamy说“在短时间内不会,但长期来看可能。”
然而就在2016年5月25日,Twitter正式宣布Heron开源。Twitter工程经理Karthik Ramasamy在博客上宣布了这一消息。
Heron的基本原理和方法:
实时流系统是在大规模数据分析的基础上实现系统性的分析。另外,它还需要:每分钟处理数十亿事件的能力、有秒级延迟,和行为可预见;在故障时保证数据的准确性,在达到流量峰值时是弹性的,并且易于调试和在共享的基础设施上实现简单部署。
为了满足这些需求,Twitter讨论出了几种方案,包括:扩展Storm、使用其他的开源系统、开发一个全新的平台。因为有几个需求是要求改变Storm的核心架构,所以对它进行扩展需要一个很长的开发周期。其他的开源流处理框架并不能完美满足Twitter对于规模、吞吐量和延迟的需求。而且,这些系统也不能兼容Storm API——适应一个新的API需要重写几个topologies和修改高级的abstractions,这会导致一个很长的迁移过程。所以,Twitter决定建立一个新的系统来满足以上提到需求和兼容Storm API。
Heron的特色:
Twitter开发Heron,主要的目标是增加性能预测、提高开发者的生产力和易于管理。
图1:Heron架构
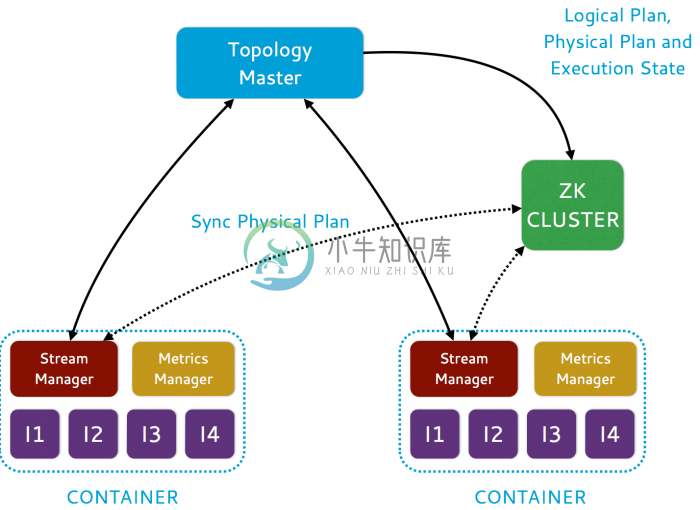
图2:拓扑架构
对于Heron的整体架构请看图1和图2。用户使用Storm API来构建和提交topologies来实现一个调度。调度运行的每一个topology作为一个job,有几个容器组成,其中一个容器运行主topology,负责管理topology。每个剩余的容器运行一个流管理器,负责数据路由——一个权值管理器,用来搜集和报告各种权值和多个Heron实例(运行user-defined spout/bolt代码)进程。这些容器是基于集群中的节点的资源可用性来实现分配和调度。对于topology元数据,例如物理计划和执行细节,都是保管在Zookeeper中。
Heron的功能:
Off the shelf scheduler:通过抽象出调度组件,我们可轻易地在一个共享的基础设施上部署,可以是多种的调度框架,比如Mesos、YARN或者一个定制的环境。
Handling spikes and congestion:Heron 具有一个背压机制,即在执行时的一个topology中动态地调整数据流,从而不影响数据的准确性。这在流量峰值和管道堵塞时非常有用。
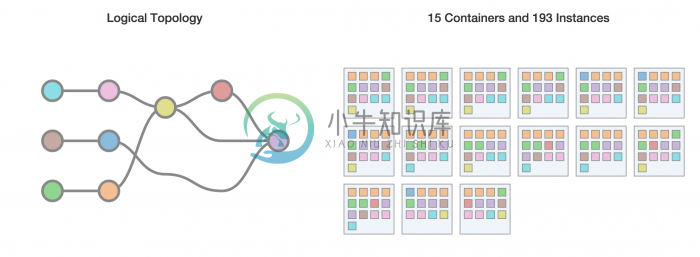
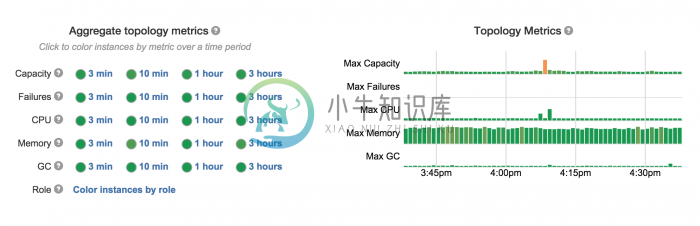
图3:Heron UI,显示逻辑计划、物理计划和拓扑状态
Easy debugging:每个任务是进程级隔离的,从而很容易理解行为、性能和文件配置。此外,Heron topologies复杂的UI如图3所示,可快速和有效地排除故障问题。
Compatibility with Storm:Heron提供了完全兼容Storm的特性,所我们无需再为新系统投资太多的时间和资源。另外,不要更改代码就可在Heron中运行现有的Storm topologies,实现轻松地迁移。
Scalability and latency:Heron能够处理大规模的topologies,且满足高吞吐量和低延迟的要求。此外,该系统可以处理大量的topologies。
Heron性能
比较Heron和Storm,样本流是150,000个单词,如下图所示:
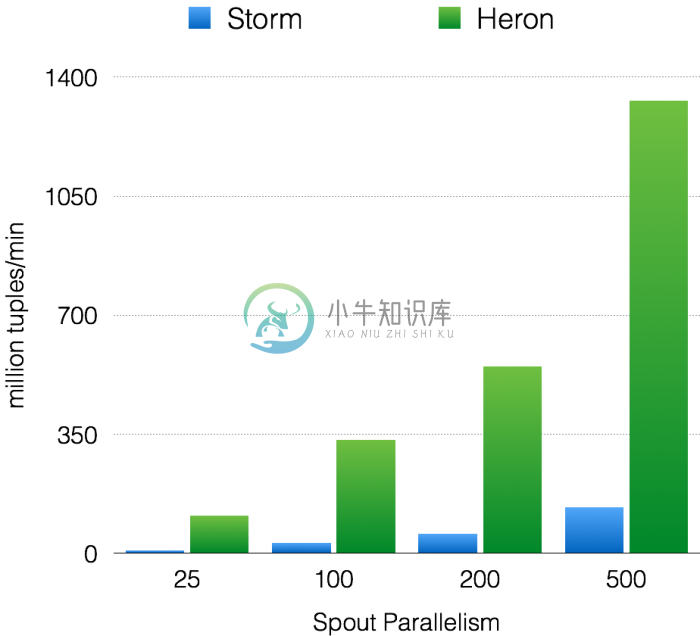
图4. Throughput with acks enabled
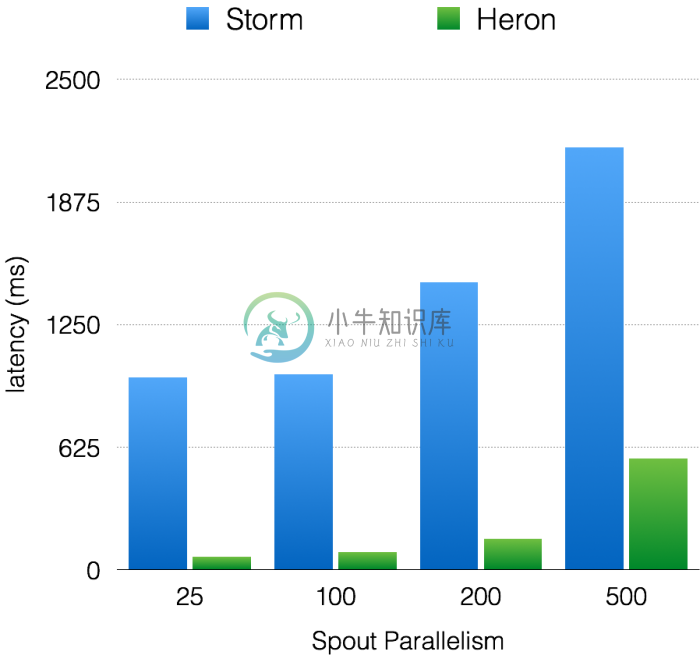
图5. Latency with acks enabled
如图4所示,Heron和Storm的吞吐量呈现线性增长的趋势。然而,在所有的实验中,Heron吞吐量比Storm高10–14倍。同样在端至端延迟方面,如图5所示,两者都在增加,可Heron延迟比Storm低5–15倍。
除此之外,Twitter已经运行topologies的规模大概是数百台的机器,其中许多实现了每秒产生数百万次事件的资源处理,完全没有问题。有了Heron,众多topologies的每秒集群数据可达到亚秒级延迟。在这些案例中,Heron实现目标的资源消耗能够比Storm更低。
Heron at Twitter
在Twitter,Heron作为主要的流媒体系统,运行数以百万计的开发和生产topologies。由于Heron可高效使用资源,在迁移Twitter所有的topologies后,整体硬件减少了3倍,导致Twitter的基础设置效率有了显著的提升。
了解更多:https://blog.twitter.com/2015/flying-faster-with-twitter-heron
-
Heron是Twitter为了更好的进行实时计算的项目,主要是为了替换和改善Storm的不足而设计。详细的基础介绍和设计目标优势等,可以搜索Google或者查看官方文档(http://twitter.github.io/heron/)。 这里对Heron的使用做出一些介绍,在了解基础上,动手实践总是更好理解。这一部分只提及heron的安装依赖环境。 一、Heron使用依赖的环境: 1.
-
巴比伦算法 求根号可以说是刚需了,最简单的就是计算 2 \sqrt2 2 ,小时候做数学题我们是背下来了,就是等于 1.414 1.414 1.414,但是三位小数是肯定精度不够的,需要再精确怎么办?哉4000年前,巴比伦人发明了一种求 2 \sqrt2 2 的算法: 2 = 1 + 24 60 + 51 6 0 2 + 10 6 0 3 \sqrt2=1+\frac{24}{60}+\f
-
社招,录取,一共三轮面试。 一面:自我介绍,问简历相关项目,出题:有5000万条车险顾客数据,已知其中的500万的用户有宠物,如何对其他4500万用户精准推荐宠物险。 二面:自我介绍,提问他们更换模型时,生效有延迟怎么处理。 三面:自我介绍,知道哪些机器学习算法,决策树原理,协方差作用。 HR谈薪:薪资构成:12个月加年终奖。三个月试用期,试用期间工资八折,年终奖发放看考核分数所处区间系数。 拒绝
-
一面(约50分钟) 1、自我介绍 2、详细说明工作经历做了什么,有什么成果即工作业绩 3、SQL用的最多的函数有哪些 4、窗口函数rank()、dense_rank()、row_number()的区别 4、两道SQL口述题目 一个表三列分别是:id,顾客的问题,对问题的回答 a)获得顾客问的最多的10个问题 b)获得每个顾客问的最多的10个问题 5、讲述ABtest的过程 6、怎么分析ABtest
-
一面 电话call 10min 应该是hr来面的技术面 应该是照着问题念的 她们也不是很懂 印象中有一些统计学问题,p值,假设检验等。 机器学习问题等等 二面 10-15min 视频面 挖简历为主 三个面试官一起 二面后应该是泡池子了,过了好久好久,突然打电话约我三面 三面 30min 电话call hr面 恕我直言,我觉得hr是面下来最专业的了 问对保险行业的理解 为什么来产险 你认为数据在保险
-
平安产险数据类笔试0901场 总共30道选择+2道问答题,总时长45分钟。 30道选择包括:经济学/SQL(不是常见的向题,会涉及到注入漏斗之类的)/概率论与数理统计/金融数学(年金、利率 剩余本金)/会计/机器学习 2道问答题都有点像是逻辑推理,比如给你几个条件,让你推断抽出的是哪三张牌 总体来说范围很广,难度我觉得不算小 #平安# #平安产险# #数据分析# #笔试# #24校招内推#
-
实时分析用户在微信小程序中的每一个互动行为,了解用户行为轨迹,结合用户设置的微信属性全面分析用户价值,结合场景的统计分析,提升小程序的使用效率,通过数据驱动用户的增长。
-
功能介绍 获取本APP定制分析中实时分析报告的数据,本报告是定制分析,支持维度和指标的自由组合,请详细阅读本文档说明了解使用详情。 接口 https://openapi.baidu.com/rest/2.0/mtj/svc/app/getDataByKey 请求参数 此处仅列本接口特有参数,公共参数请参考报告级API说明 获取表格数据 参数名 参数类型 是否必须 描述 method string