
Leaf
美团点评分布式ID生成系统背景
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。如在美团点评的金融、支付、餐饮、酒店、猫眼电影等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求;特别一点的如订单、骑手、优惠券也都需要有唯一ID做标识。此时一个能够生成全局唯一ID的系统是非常必要的。概括下来,那业务系统对ID号的要求有哪些呢?
-
全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
-
趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
-
单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
-
信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
上述123对应三类不同的场景,3和4需求还是互斥的,无法使用同一个方案满足。
同时除了对ID号码自身的要求,业务还对ID号生成系统的可用性要求极高,想象一下,如果ID生成系统瘫痪,整个美团点评支付、优惠券发券、骑手派单等关键动作都无法执行,这就会带来一场灾难。
由此总结下一个ID生成系统应该做到如下几点:
-
平均延迟和TP999延迟都要尽可能低;
-
可用性5个9;
-
高QPS。
常见方法介绍
UUID
UUID(Universally Unique Identifier)的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的36个字符,示例:550e8400-e29b-41d4-a716-446655440000,到目前为止业界一共有5种方式生成UUID,详情见IETF发布的UUID规范 A Universally Unique IDentifier (UUID) URN Namespace。
优点:
-
性能非常高:本地生成,没有网络消耗。
缺点:
-
不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
-
信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
-
ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用:
① MySQL官方有明确的建议主键要尽量越短越好[4],36个字符长度的UUID不符合要求。
All indexes other than the clustered index are known as secondary indexes. In InnoDB, each record in a secondary index contains the primary key columns for the row, as well as the columns specified for the secondary index. InnoDB uses this primary key value to search for the row in the clustered index. If the primary key is long, the secondary indexes use more space, so it is advantageous to have a short primary key.
② 对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能。
类snowflake方案
这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示如下图(图片来自网络)所示:
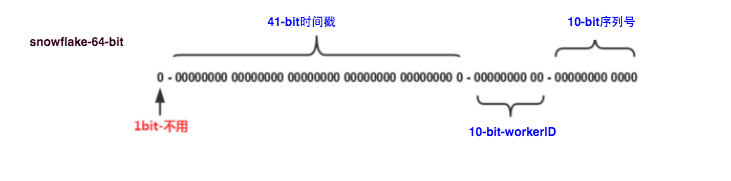
41-bit的时间可以表示(1L<<41)/(1000L*3600*24*365)=69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
这种方式的优缺点是:
优点:
-
毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
-
不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
-
可以根据自身业务特性分配bit位,非常灵活。
缺点:
-
强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
应用举例Mongdb objectID
MongoDB官方文档 ObjectID可以算作是和snowflake类似方法,通过“时间+机器码+pid+inc”共12个字节,通过4+3+2+3的方式最终标识成一个24长度的十六进制字符。
数据库生成
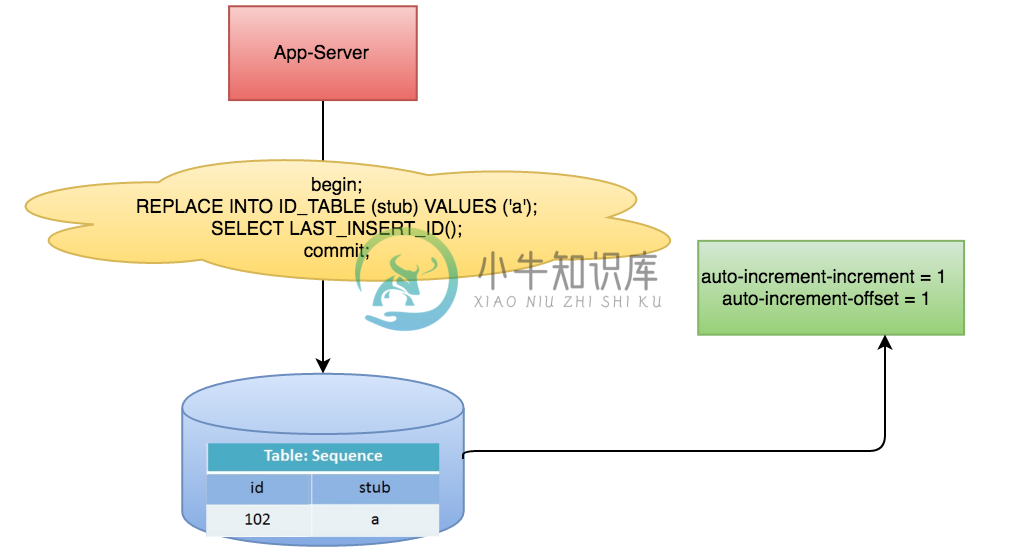
以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增,每次业务使用下列SQL读写MySQL得到ID号。
begin;REPLACE INTO Tickets64 (stub) VALUES ('a');SELECT LAST_INSERT_ID();commit;
这种方案的优缺点如下:
优点:
-
非常简单,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
-
ID号单调自增,可以实现一些对ID有特殊要求的业务。
缺点:
-
强依赖DB,当DB异常时整个系统不可用,属于致命问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。
-
ID发号性能瓶颈限制在单台MySQL的读写性能。
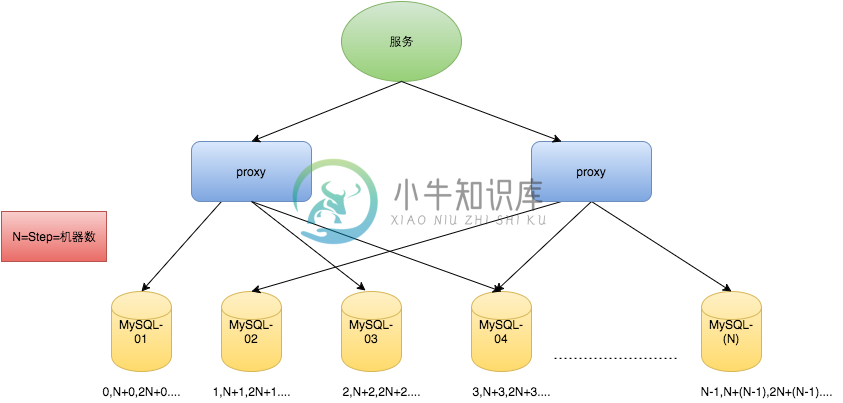
对于MySQL性能问题,可用如下方案解决:在分布式系统中我们可以多部署几台机器,每台机器设置不同的初始值,且步长和机器数相等。比如有两台机器。设置步长step为2,TicketServer1的初始值为1(1,3,5,7,9,11...)、TicketServer2的初始值为2(2,4,6,8,10...)。这是Flickr团队在2010年撰文介绍的一种主键生成策略(Ticket Servers: Distributed Unique Primary Keys on the Cheap )。如下所示,为了实现上述方案分别设置两台机器对应的参数,TicketServer1从1开始发号,TicketServer2从2开始发号,两台机器每次发号之后都递增2。
TicketServer1: auto-increment-increment = 2 auto-increment-offset = 1 TicketServer2: auto-increment-increment = 2 auto-increment-offset = 2
假设我们要部署N台机器,步长需设置为N,每台的初始值依次为0,1,2...N-1那么整个架构就变成了如下图所示:
这种架构貌似能够满足性能的需求,但有以下几个缺点:
-
系统水平扩展比较困难,比如定义好了步长和机器台数之后,如果要添加机器该怎么做?假设现在只有一台机器发号是1,2,3,4,5(步长是1),这个时候需要扩容机器一台。可以这样做:把第二台机器的初始值设置得比第一台超过很多,比如14(假设在扩容时间之内第一台不可能发到14),同时设置步长为2,那么这台机器下发的号码都是14以后的偶数。然后摘掉第一台,把ID值保留为奇数,比如7,然后修改第一台的步长为2。让它符合我们定义的号段标准,对于这个例子来说就是让第一台以后只能产生奇数。扩容方案看起来复杂吗?貌似还好,现在想象一下如果我们线上有100台机器,这个时候要扩容该怎么做?简直是噩梦。所以系统水平扩展方案复杂难以实现。
-
ID没有了单调递增的特性,只能趋势递增,这个缺点对于一般业务需求不是很重要,可以容忍。
-
数据库压力还是很大,每次获取ID都得读写一次数据库,只能靠堆机器来提高性能。
Leaf方案实现
Leaf这个名字是来自德国哲学家、数学家莱布尼茨的一句话:
There are no two identical leaves in the world
"世界上没有两片相同的树叶"
综合对比上述几种方案,每种方案都不完全符合我们的要求。所以Leaf分别在上述第二种和第三种方案上做了相应的优化,实现了Leaf-segment和Leaf-snowflake方案。
Leaf-segment数据库方案
第一种Leaf-segment方案,在使用数据库的方案上,做了如下改变:
-
原方案每次获取ID都得读写一次数据库,造成数据库压力大。改为利用proxy server批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。
-
各个业务不同的发号需求用biz_tag字段来区分,每个biz-tag的ID获取相互隔离,互不影响。如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对biz_tag分库分表就行。
数据库表设计如下:
+-------------+--------------+------+-----+-------------------+-----------------------------+| Field | Type | Null | Key | Default | Extra | +-------------+--------------+------+-----+-------------------+-----------------------------+| biz_tag | varchar(128) | NO | PRI | | | | max_id | bigint(20) | NO | | 1 | | | step | int(11) | NO | | NULL | | | desc | varchar(256) | YES | | NULL | | | update_time | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP | +-------------+--------------+------+-----+-------------------+-----------------------------+
重要字段说明:biz_tag用来区分业务,max_id表示该biz_tag目前所被分配的ID号段的最大值,step表示每次分配的号段长度。原来获取ID每次都需要写数据库,现在只需要把step设置得足够大,比如1000。那么只有当1000个号被消耗完了之后才会去重新读写一次数据库。读写数据库的频率从1减小到了1/step,大致架构如下图所示:
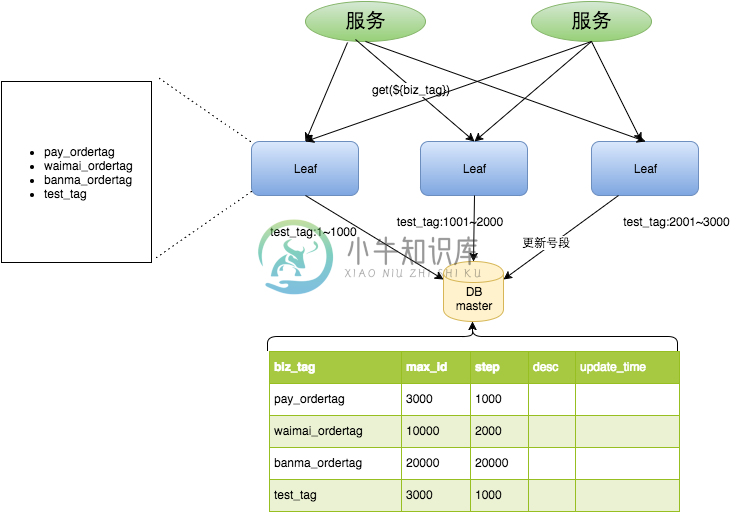
test_tag在第一台Leaf机器上是1~1000的号段,当这个号段用完时,会去加载另一个长度为step=1000的号段,假设另外两台号段都没有更新,这个时候第一台机器新加载的号段就应该是3001~4000。同时数据库对应的biz_tag这条数据的max_id会从3000被更新成4000,更新号段的SQL语句如下:
BeginUPDATE table SET max_id=max_id+step WHERE biz_tag=xxxSELECT tag, max_id, step FROM table WHERE biz_tag=xxxCommit
这种模式有以下优缺点:
优点:
-
Leaf服务可以很方便的线性扩展,性能完全能够支撑大多数业务场景。
-
ID号码是趋势递增的8byte的64位数字,满足上述数据库存储的主键要求。
-
容灾性高:Leaf服务内部有号段缓存,即使DB宕机,短时间内Leaf仍能正常对外提供服务。
-
可以自定义max_id的大小,非常方便业务从原有的ID方式上迁移过来。
缺点:
-
ID号码不够随机,能够泄露发号数量的信息,不太安全。
-
TP999数据波动大,当号段使用完之后还是会hang在更新数据库的I/O上,tg999数据会出现偶尔的尖刺。
-
DB宕机会造成整个系统不可用。
双buffer优化
对于第二个缺点,Leaf-segment做了一些优化,简单的说就是:
Leaf 取号段的时机是在号段消耗完的时候进行的,也就意味着号段临界点的ID下发时间取决于下一次从DB取回号段的时间,并且在这期间进来的请求也会因为DB号段没有取回来,导致线程阻塞。如果请求DB的网络和DB的性能稳定,这种情况对系统的影响是不大的,但是假如取DB的时候网络发生抖动,或者DB发生慢查询就会导致整个系统的响应时间变慢。
为此,我们希望DB取号段的过程能够做到无阻塞,不需要在DB取号段的时候阻塞请求线程,即当号段消费到某个点时就异步的把下一个号段加载到内存中。而不需要等到号段用尽的时候才去更新号段。这样做就可以很大程度上的降低系统的TP999指标。详细实现如下图所示:
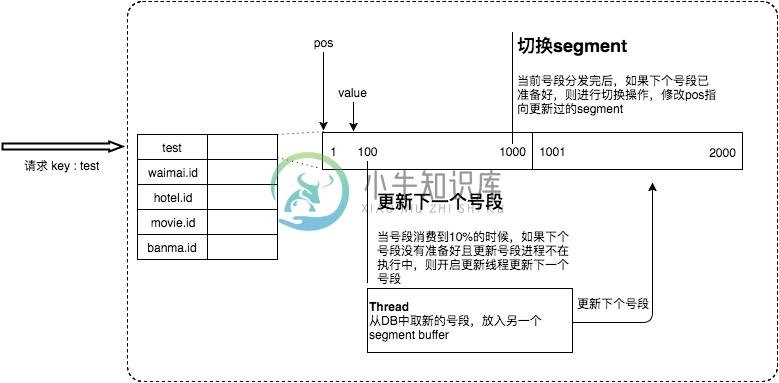
采用双buffer的方式,Leaf服务内部有两个号段缓存区segment。当前号段已下发10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前segment接着下发,循环往复。
-
每个biz-tag都有消费速度监控,通常推荐segment长度设置为服务高峰期发号QPS的600倍(10分钟),这样即使DB宕机,Leaf仍能持续发号10-20分钟不受影响。
-
每次请求来临时都会判断下个号段的状态,从而更新此号段,所以偶尔的网络抖动不会影响下个号段的更新。
Leaf高可用容灾
对于第三点“DB可用性”问题,我们目前采用一主两从的方式,同时分机房部署,Master和Slave之间采用半同步方式[5]同步数据。同时使用公司Atlas数据库中间件(已开源,改名为DBProxy)做主从切换。当然这种方案在一些情况会退化成异步模式,甚至在非常极端情况下仍然会造成数据不一致的情况,但是出现的概率非常小。如果你的系统要保证100%的数据强一致,可以选择使用“类Paxos算法”实现的强一致MySQL方案,如MySQL 5.7前段时间刚刚GA的MySQL Group Replication。但是运维成本和精力都会相应的增加,根据实际情况选型即可。
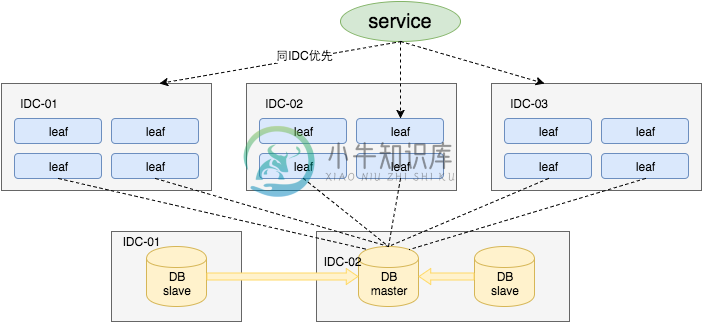
同时Leaf服务分IDC部署,内部的服务化框架是“MTthrift RPC”。服务调用的时候,根据负载均衡算法会优先调用同机房的Leaf服务。在该IDC内Leaf服务不可用的时候才会选择其他机房的Leaf服务。同时服务治理平台OCTO还提供了针对服务的过载保护、一键截流、动态流量分配等对服务的保护措施。
Leaf-snowflake方案
Leaf-segment方案可以生成趋势递增的ID,同时ID号是可计算的,不适用于订单ID生成场景,比如竞对在两天中午12点分别下单,通过订单id号相减就能大致计算出公司一天的订单量,这个是不能忍受的。面对这一问题,我们提供了 Leaf-snowflake方案。
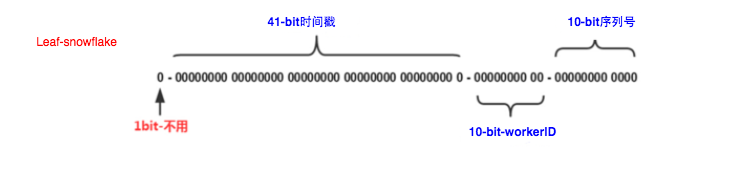
Leaf-snowflake方案完全沿用snowflake方案的bit位设计,即是“1+41+10+12”的方式组装ID号。对于workerID的分配,当服务集群数量较小的情况下,完全可以手动配置。Leaf服务规模较大,动手配置成本太高。所以使用Zookeeper持久顺序节点的特性自动对snowflake节点配置wokerID。Leaf-snowflake是按照下面几个步骤启动的:
-
启动Leaf-snowflake服务,连接Zookeeper,在leaf_forever父节点下检查自己是否已经注册过(是否有该顺序子节点)。
-
如果有注册过直接取回自己的workerID(zk顺序节点生成的int类型ID号),启动服务。
-
如果没有注册过,就在该父节点下面创建一个持久顺序节点,创建成功后取回顺序号当做自己的workerID号,启动服务。
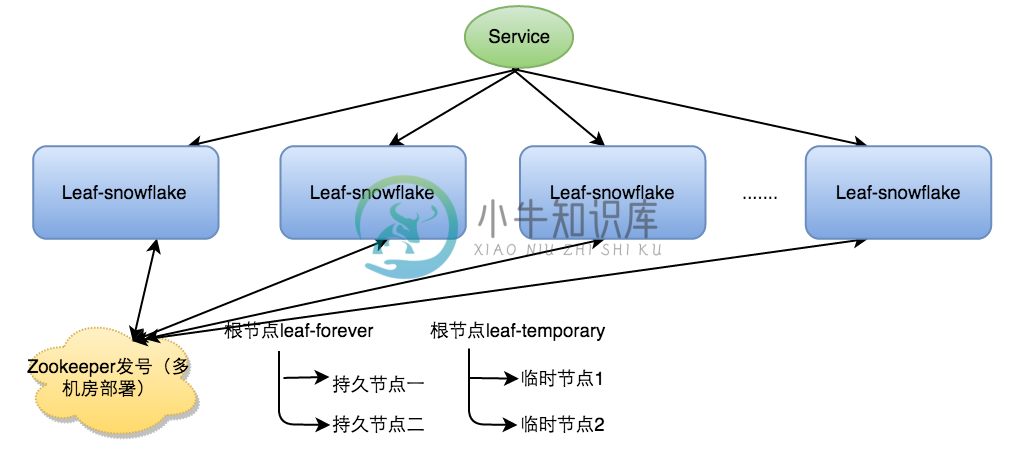
弱依赖ZooKeeper
除了每次会去ZK拿数据以外,也会在本机文件系统上缓存一个workerID文件。当ZooKeeper出现问题,恰好机器出现问题需要重启时,能保证服务能够正常启动。这样做到了对三方组件的弱依赖。一定程度上提高了SLA
解决时钟问题
因为这种方案依赖时间,如果机器的时钟发生了回拨,那么就会有可能生成重复的ID号,需要解决时钟回退的问题。
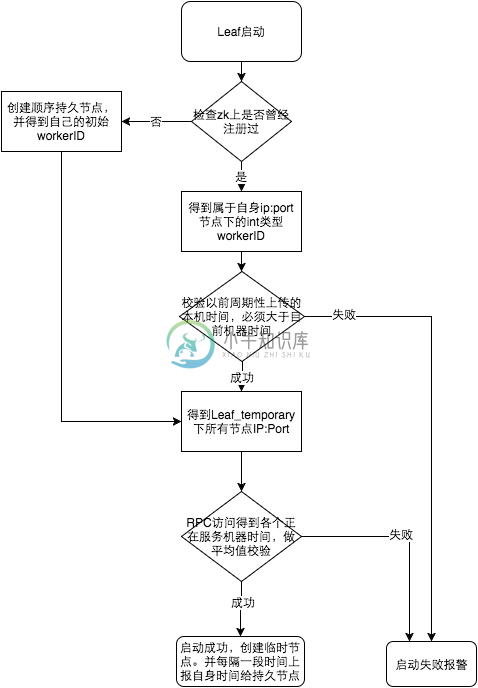
参见上图整个启动流程图,服务启动时首先检查自己是否写过ZooKeeper leaf_forever节点:
-
若写过,则用自身系统时间与leaf_forever/${self}节点记录时间做比较,若小于leaf_forever/${self}时间则认为机器时间发生了大步长回拨,服务启动失败并报警。
-
若未写过,证明是新服务节点,直接创建持久节点leaf_forever/${self}并写入自身系统时间,接下来综合对比其余Leaf节点的系统时间来判断自身系统时间是否准确,具体做法是取leaf_temporary下的所有临时节点(所有运行中的Leaf-snowflake节点)的服务IP:Port,然后通过RPC请求得到所有节点的系统时间,计算sum(time)/nodeSize。
-
若abs( 系统时间-sum(time)/nodeSize ) < 阈值,认为当前系统时间准确,正常启动服务,同时写临时节点leaf_temporary/${self} 维持租约。
-
否则认为本机系统时间发生大步长偏移,启动失败并报警。
-
每隔一段时间(3s)上报自身系统时间写入leaf_forever/${self}。
由于强依赖时钟,对时间的要求比较敏感,在机器工作时NTP同步也会造成秒级别的回退,建议可以直接关闭NTP同步。要么在时钟回拨的时候直接不提供服务直接返回ERROR_CODE,等时钟追上即可。或者做一层重试,然后上报报警系统,更或者是发现有时钟回拨之后自动摘除本身节点并报警,如下:
//发生了回拨,此刻时间小于上次发号时间 if (timestamp < lastTimestamp) { long offset = lastTimestamp - timestamp; if (offset <= 5) { try { //时间偏差大小小于5ms,则等待两倍时间
wait(offset << 1);//wait
timestamp = timeGen(); if (timestamp < lastTimestamp) { //还是小于,抛异常并上报
throwClockBackwardsEx(timestamp);
}
} catch (InterruptedException e) {
throw e;
}
} else { //throw
throwClockBackwardsEx(timestamp);
}
} //分配ID
从上线情况来看,在2017年闰秒出现那一次出现过部分机器回拨,由于Leaf-snowflake的策略保证,成功避免了对业务造成的影响。
Leaf现状
Leaf在美团点评公司内部服务包含金融、支付交易、餐饮、外卖、酒店旅游、猫眼电影等众多业务线。目前Leaf的性能在4C8G的机器上QPS能压测到近5w/s,TP999 1ms,已经能够满足大部分的业务的需求。每天提供亿数量级的调用量,作为公司内部公共的基础技术设施,必须保证高SLA和高性能的服务,我们目前还仅仅达到了及格线,还有很多提高的空间。
作者简介
照东,美团点评基础架构团队成员,主要参与美团大型分布式链路跟踪系统Mtrace和美团点评分布式ID生成系统Leaf的开发工作。曾就职于阿里巴巴,2016年7月加入美团。
最后做一个招聘广告:如果你对大规模分布式环境下的服务治理、分布式会话链追踪等系统感兴趣,诚挚欢迎投递简历至:zhangjinlu#meituan.com。
参考资料
-
施瓦茨. 高性能MySQL[M]. 电子工业出版社, 2010:162-171.
-
Leaf的模块机制 一个Leaf开发的游戏服务器由多个模块组成,模块有一下特点: 1、每个模块运行在一个单独的goroutine中 2、模块间通过一套轻量的RPC机制通讯(leaf/charpc) 游戏服务器在启动时进行模块的注册,例如: leaf.Run( game.Module, gate.Module, login.Module, ) 这里按顺序注册了game、gate、login三
-
Leaflet 第一章 概述 Leaflet是一个为建设交互性好适用于移动设备地图的领先开源JavaScript库。代码大小仅仅33KB,它具有开发在线地图的大部分功能。Leaflet设计坚持简便、高性能和可用性好的思想,能够在所有主流的桌面和移动平台高效的运作。支持插件扩展,拥有漂亮、易用的API文档和一个简单的、可读的源代码。 官方网址http://leafletjs.c
-
一、Snowflake生成ID的模式 snowflake算法对于ID的位数是上图这样分配的: 1位的符号位+41位时间戳+10位workID+12位序列号 加起来一共是64个二进制位,正好与Java中的long类型的位数一样。 美团的Leaf框架对于snowflake算法进行了一些位数调整,位数分配是这样: 最大41位时间差+10位的workID+12位序列化 虽然看美团对Leaf的介绍文章里面说
-
Leaf 服务器的设计 Leaf专注于游戏服务器,因此与一些Web服务器开发的设计和考虑有所不同。在一些游戏服务器中,采用的是分布式架构,即服务器整体被划分为不同的模块,各个模块承担不同的功能,而模块之间通过TCP进行交互。这样的架构能够保证服务器能够在多台机器上部署,单点故障不至于让服务整体崩溃。但是这种服务器有其自身的开发难度,而且有时候做好模块划分并不容易。Leaf是一体式的框架,连最外围的
-
目录 创建地图(map) 添加图层(tileLayer) 创建标记(marker) 图标(icon/divIcon) 弹框(bindPopup) options选项 方法 工具提示(bindTooltip) options选项 窗格(pane) 常用方法 创建地图(map) let map= L.map('map', { minZoom: 4, maxZoom: 17, zoom: 1
-
概览 本文跟一下leaf的雪花模式的算法 关注点: workerid生成 时间回拨问题解决 leaf是美团开源的分布式id 项目 源码分析 首先从server的Controller出发,看一下雪花算法生成的方法 @RequestMapping(value = "/api/snowflake/get/{key}") public String getSnowflakeId(@PathVariable
-
leaf框架源码分析 近来阅读leaf框架的代码,有些感悟,特来记录一番。既是一个总结,又是对后来阅读者的一个启发。 个人看代码的一个习惯,喜欢有上下文,因此会各个代码文件之间相互乱窜。但多看几次也就能对框架要做什么和我们要做什么有一个清晰的了解了。 阅读本文之前,还是建议先看看作者写的Wiki,其中有关于框架整体的一个介绍和使用。至于项目地址,去github上搜索便是。 如何使用Leaf 首先需
-
在pytorch的tensor类中,有个is_leaf的属性,姑且把它作为叶子节点. is_leaf 为False的时候,则不是叶子节点, is_leaf为True的时候为叶子节点(或者叶张量) 所以问题来了: leaf的作用是什么?为什么要加 leaf? 我们都知道tensor中的 requires_grad()属性,当requires_grad()为True时我们将会记录tensor的运算过程
-
主要内容:1.UUID,2.数据库自增Id,3.基于数据库集群模式,4.基于数据库的号段模式,5.Redis,6.Snowflake,7.百度(uid-generator),8.Leaf,9.TinyId生成方式: 1.UUID 2.数据库自增ID 3.数据库多主模式 4.号段模式 5.Redis 6.雪花算法(SnowFlake) 7.滴滴出品(TinyID) 8.百度 (Uidgenerator) 9.美团(Leaf) 1.UUID UUID的生成简单到只有一行代码,输出结果 c2b8c2b
-
有时我们需要能够生成类似MySQL自增ID这样不断增大,同时又不会重复的id。以支持业务中的高并发场景。比较典型的,电商促销时,短时间内会有大量的订单涌入到系统,比如每秒10w+。明星出轨时,会有大量热情的粉丝发微博以表心意,同样会在短时间内产生大量的消息。 在插入数据库之前,我们需要给这些消息、订单先打上一个ID,然后再插入到我们的数据库。对这个id的要求是希望其中能带有一些时间信息,这样即使我
-
如何自定义生成固定长度的字符串ID,8-12个字符 格式:业务标记_xxxxxxxxxx 如:user_Nuxq23s24dxa1ScSx 要求:1ms生成100W个 或有什么现成的库可以使用,麻烦老大们贴下代码
-
一面 1、自我介绍 2、是通过什么手段来筛选潜力商家的?(深挖简历) 3、你的BD成功入驻率是多少?(数据能力) 4、介绍一下从BD到日常运营的整个流程?(深挖简历) 5、对于不同商家是如何分层运营的?(头部、腰部、尾部) 6、是通过什么来提升商家入驻的意愿的?(运营侧+产品侧) 7、介绍一下你印象最深的一个项目活动(执行+结果) 8、这个活动中给到你的指标是什么,如何达成?(个人能力) 9、在这
-
一面 3.27 第一回遇到提前五分钟进来的面试官。。。 面试官介绍部门 问我知不知道 kkv? 列存储怎么做?列存和行存的区别,使用场景? 介绍了实习的工作 leveldb 读哪一层sst最耗时,为什么? 如果前台不停的读,后台在做compaction ,会发生什么? CMU 15445 问了分片buffer pool 的实现? 怎么实现 buffer pool 的无锁化? 如果现在 mmap 的
-
一面 【经历相关】 首先先问了你的经历,不仅要讲实习,还要讲你的学校经历/社团经历。 ·同时会问在这个过程中你遇到了什么问题,然后怎么解决的? ·对交互设计师的理解,交互设计师最重要的能力是什么? ·和用户运营、用户研究比起来交互设计师区别在哪? 感觉这道题我没有好好思考过,说了一大通,感觉面试官以听废话的感觉在听,没说到点子上 ·你的未来职业发展规划是什么?(三年) 【专业相关】 接
-
8.9 50min 自我介绍 讲一个简历上的项目 项目模型怎么选择的 为什么 数据怎么增强的 了解大模型吗 使用的大模型优点和缺点 了解nlp模型吗 一个概率题 抛骰子直到抛到6为止 求期望 一道编程 nums target 返回加起来等于target的下标集合 问时空复杂度 场景题:怎么判断大模型生成的内容是否对社会有害 面试官小姐姐好温柔 大一之后没做过概率题了完全不会写 编程写出来了但是复杂
-
主要内容:(1)方案一:独立数据库自增id,(2)方案二:uuid,(3)方案三:获取系统当前时间,(4)方案四:snowflake算法的思想分析,(5)snowflake算法的代码实现,(6)snowflake算法一个小小的改进思路上一篇文章,我们聊了一下分库分表相关的一些基础知识,具体可以参见:《用真实业务场景告诉你,高并发下如何设计数据库架构?》。 这篇文章,我们就接着分库分表的知识,来具体聊一下全局唯一id如何生成。 在分库分表之后你必然要面对的一个问题,就是id咋生成? 因为要是一个表