
爬虫简介:
WebCollector 是一个无须配置、便于二次开发的 Java 爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop 是 WebCollector 的 Hadoop 版本,支持分布式爬取。
目前WebCollector-Python项目已在Github上开源,欢迎各位前来贡献代码:https://github.com/CrawlScript/WebCollector-Python
爬虫内核:
WebCollector 致力于维护一个稳定、可扩的爬虫内核,便于开发者进行灵活的二次开发。内核具有很强的扩展性,用户可以在内核基础上开发自己想要的爬虫。源码中集成了 Jsoup,可进行精准的网页解析。2.x 版本中集成了 selenium,可以处理 JavaScript 生成的数据。
Maven:

最新Maven地址请参考文档:https://github.com/CrawlScript/WebCollector/blob/master/README.md
文档地址:
https://github.com/CrawlScript/WebCollector/blob/master/README.md
内核构架图:
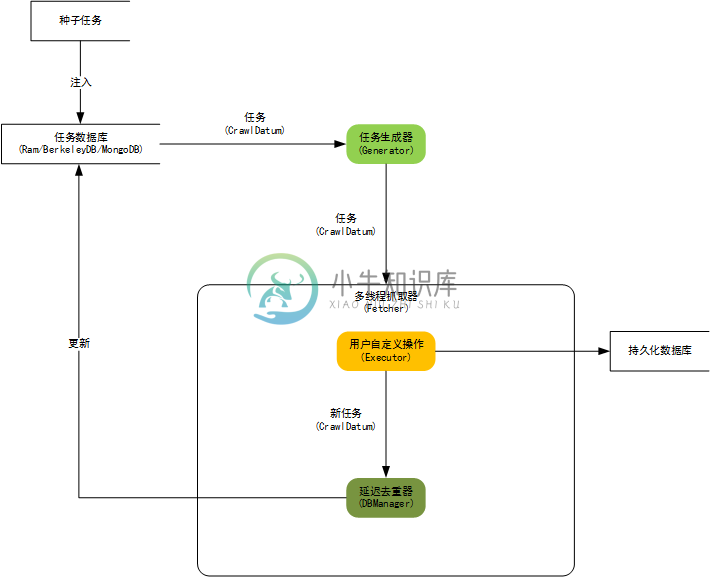
WebCollector 2.x 版本特性:
-
自定义遍历策略,可完成更为复杂的遍历业务,例如分页、AJAX
-
可以为每个 URL 设置附加信息(MetaData),利用附加信息可以完成很多复杂业务,例如深度获取、锚文本获取、引用页面获取、POST 参数传递、增量更新等。
-
使用插件机制,用户可定制自己的Http请求、过滤器、执行器等插件。
-
内置一套基于内存的插件(RamCrawler),不依赖文件系统或数据库,适合一次性爬取,例如实时爬取搜索引擎。
-
内置一套基于 Berkeley DB(BreadthCrawler)的插件:适合处理长期和大量级的任务,并具有断点爬取功能,不会因为宕机、关闭导致数据丢失。
-
集成 selenium,可以对 JavaScript 生成信息进行抽取
-
可轻松自定义 http 请求,并内置多代理随机切换功能。 可通过定义 http 请求实现模拟登录。
-
使用 slf4j 作为日志门面,可对接多种日志
-
使用类似Hadoop的Configuration机制,可为每个爬虫定制配置信息。
WebCollector 2.x 官网和镜像:
WebCollector 2.x教程:
WebCollector配置
WebCollector入门
WebCollector特色功能
- 【推荐】WebCollector教程——MetaData
- 【推荐】WebCollector教程——MatchUrl和MatchType
- WebCollector 教程——去重辅助插件 NextFilter
- WebCollector教程——断点爬取
- WebCollector教程——网页正文自动提取
WebCollector持久化
WebCollector高级爬虫定制
- WebCollector 2.72自定义Http请求插件(定制User-Agent和Cookie等请求头)
- WebCollector 2.72处理301/302重定向、404 Not Found等Http状态
- WebCollector 2.72使用阿布云代理
WebCollector处理Javascript
WebCollector示例
- WebCollector教程——爬取CSDN博客
- WebCollector教程——爬取搜索引擎
- WebCollector教程——爬取新浪微博
- WebCollector教程——爬取微信公众号
- WebCollector教程——图片爬取
- WebCollector教程——获取当前抓取深度
网页正文提取:
网页正文提取项目 ContentExtractor 已并入 WebCollector 维护。
WebCollector 的正文抽取 API 都被封装为 ContentExtractor 类的静态方法。可以抽取结构化新闻,也可以只抽取网页的正文(或正文所在 Element)。
正文抽取效果指标 :
-
比赛数据集 CleanEval P=93.79% R=86.02% F=86.72%
-
常见新闻网站数据集 P=97.87% R=94.26% F=95.33%
-
算法无视语种,适用于各种语种的网页
标题抽取和日期抽取使用简单启发式算法,并没有像正文抽取算法一样在标准数据集上测试,算法仍在更新中。
-
官网地址:https://github.com/CrawlScript/WebCollector 。这是java版本,如果想要体验Python版本的话请移步 https://github.com/CrawlScript/WebCollector-Python 其它介绍文章 https://www.freesion.com/article/255392486/ https://blog.csdn.n
-
package junit.test; import java.io.File; import java.io.FileWriter; import java.io.IOException; import java.io.StringReader; import cn.edu.hfut.dmic.webcollector.crawler.DeepCrawler; import cn.edu.hfu
-
https://github.com/CrawlScript/WebCollector java爬虫,下面代码基于webCollector,可以爬取加载js后的数据,部分网站做了防护后也是抓取不到数据的。 pom: <dependency> <groupId>cn.edu.hfut.dmic.webcollector</groupId> <artif
-
本教程演示了WebCollector 2.20的新特性。 下载 WebCollector最新jar包可在WebCollector github主页下载。 MetaData: MetaData是每个爬取任务的附加信息,灵活应用MetaData可以大大简化爬虫的设计。 例如Post请求往往需要包含参数,而传统爬虫单纯使用URL来保存参数的方法不适合复杂的POST请求。 一些爬取任务希望获取遍历树的深度
-
package com.wjd.baidukey.crawler; import java.io.ByteArrayInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.net.URLEncoder; import java.sql.Connection; import java.
-
WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核),它提供精简的的API,只需少量代码即可实现一个功能强大的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本,支持分布式爬取。 目前WebCollector在Github上维护:https://github.com/CrawlScript/WebCollector 1.WebColl
-
WebCollector-Python WebCollector-Python 是一个无须配置、便于二次开发的 Python 爬虫框架(内核),它提供精简的的 API,只需少量代码即可实现一个功能强大的爬虫。 WebCollector Java版本 WebCollector Java版相比WebCollector-Python具有更高的效率: https://github.com/CrawlScr
-
Java开源爬虫框架WebCollector教程——在Eclipse项目中配置使用WebCollector爬虫 by briefcopy· Published 2016年4月25日 · Updated 2016年12月11日 在Eclipse项目中使用WebCollector爬虫非常简单,不需要任何其他的配置,只需要导入相关的jar包即可。 Netbeans、Intellij也是非常优秀的IDE,
-
WebCollector 爬虫解析 WebCollection 爬虫核心类 cn.edu.hfut.dmic.webcollector.crawler.Crawler protected int status; //运行状态 public final static int RUNNING = 1;// 运行状态 运行中 public final static int STOP
-
网站为中国政招标网 流程为定时任务触发service层 查询需要查询的网站关键词,爬虫根据关键字爬取当天的数据 条件符合的放入list中结束后返回并保存 package gov.zb.data.webcollector.tender; import gov.zb.data.entity.monitor.Monitor; import gov.zb.data.enums.GeneralEnums;
-
爬虫爬取时,需要约束爬取的范围。基本所有的爬虫都是通过正则表达式来完成这个约束。 最简单的,正则: http://www.xinhuanet.com/.*代表"http://www.xinhuanet.com/"后加任意个任意字符(可以是0个)。 通过这个正则可以约束爬虫的爬取范围,但是这个正则并不是表示爬取新华网所有的网页。新华网并不是只有www.xinhuanet.com这一个域名,还有很多子
-
本文向大家介绍基于C#实现网络爬虫 C#抓取网页Html源码,包括了基于C#实现网络爬虫 C#抓取网页Html源码的使用技巧和注意事项,需要的朋友参考一下 最近刚完成一个简单的网络爬虫,开始的时候很迷茫,不知道如何入手,后来发现了很多的资料,不过真正能达到我需要,有用的资料--代码很难找。所以我想发这篇文章让一些要做这个功能的朋友少走一些弯路。 首先是抓取Html源码,并选择<ul class="
-
urllib介绍: 在Python2版本中,有urllib和urlib2两个库可以用来实现request的发送。 而在Python3中,已经不存在urllib2这个库了,统一为urllib。 Python3 urllib库官方链接:https://docs.python.org/3/library/urllib.html urllib中包括了四个模块,包括: urllib.request:可以用来
-
本文向大家介绍基于C#实现网页爬虫,包括了基于C#实现网页爬虫的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了基于C#实现网页爬虫的详细代码,供大家参考,具体内容如下 HTTP请求工具类: 功能: 1、获取网页html 2、下载网络图片 多线程爬取网页代码: 截图: 以上就是本文的全部内容,希望对大家的学习有所帮助。
-
主要内容:认识爬虫,爬虫分类,爬虫应用,爬虫是一把双刃剑,为什么用Python做爬虫,编写爬虫的流程网络爬虫又称网络蜘蛛、网络机器人,它是一种按照一定的规则自动浏览、检索网页信息的程序或者脚本。网络爬虫能够自动请求网页,并将所需要的数据抓取下来。通过对抓取的数据进行处理,从而提取出有价值的信息。 认识爬虫 我们所熟悉的一系列搜索引擎都是大型的网络爬虫,比如百度、搜狗、360浏览器、谷歌搜索等等。每个搜索引擎都拥有自己的爬虫程序,比如 360 浏览器的爬虫称作 360Spider,搜狗的爬虫叫做
-
案例:爬取百度新闻首页的新闻标题信息 url地址:http://news.baidu.com/ 具体实现步骤: 导入urlib库和re正则 使用urllib.request.Request()创建request请求对象 使用urllib.request.urlopen执行信息爬取,并返回Response对象 使用read()读取信息,使用decode()执行解码 使用re正则解析结果 遍历输出结果
-
5.1 网络爬虫概述: 网络爬虫(Web Spider)又称网络蜘蛛、网络机器人,是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。 网络爬虫按照系统结构和实现技术,大致可分为一下集中类型: 通用网络爬虫:就是尽可能大的网络覆盖率,如 搜索引擎(百度、雅虎和谷歌等…)。 聚焦网络爬虫:有目标性,选择性地访问万维网来爬取信息。 增量式网络爬虫:只爬取新产生的或者已经更新的页面信息。特点:耗费