
使用TensorFlow实现SVM

较基础的SVM,后续会加上多分类以及高斯核,供大家参考。
Talk is cheap, show me the code
import tensorflow as tf from sklearn.base import BaseEstimator, ClassifierMixin import numpy as np class TFSVM(BaseEstimator, ClassifierMixin): def __init__(self, C = 1, kernel = 'linear', learning_rate = 0.01, training_epoch = 1000, display_step = 50, batch_size = 50, random_state = 42): #参数列表 self.svmC = C self.kernel = kernel self.learning_rate = learning_rate self.training_epoch = training_epoch self.display_step = display_step self.random_state = random_state self.batch_size = batch_size def reset_seed(self): #重置随机数 tf.set_random_seed(self.random_state) np.random.seed(self.random_state) def random_batch(self, X, y): #调用随机子集,实现mini-batch gradient descent indices = np.random.randint(1, X.shape[0], self.batch_size) X_batch = X[indices] y_batch = y[indices] return X_batch, y_batch def _build_graph(self, X_train, y_train): #创建计算图 self.reset_seed() n_instances, n_inputs = X_train.shape X = tf.placeholder(tf.float32, [None, n_inputs], name = 'X') y = tf.placeholder(tf.float32, [None, 1], name = 'y') with tf.name_scope('trainable_variables'): #决策边界的两个变量 W = tf.Variable(tf.truncated_normal(shape = [n_inputs, 1], stddev = 0.1), name = 'weights') b = tf.Variable(tf.truncated_normal([1]), name = 'bias') with tf.name_scope('training'): #算法核心 y_raw = tf.add(tf.matmul(X, W), b) l2_norm = tf.reduce_sum(tf.square(W)) hinge_loss = tf.reduce_mean(tf.maximum(tf.zeros(self.batch_size, 1), tf.subtract(1., tf.multiply(y_raw, y)))) svm_loss = tf.add(hinge_loss, tf.multiply(self.svmC, l2_norm)) training_op = tf.train.AdamOptimizer(learning_rate = self.learning_rate).minimize(svm_loss) with tf.name_scope('eval'): #正确率和预测 prediction_class = tf.sign(y_raw) correct_prediction = tf.equal(y, prediction_class) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) init = tf.global_variables_initializer() self._X = X; self._y = y self._loss = svm_loss; self._training_op = training_op self._accuracy = accuracy; self.init = init self._prediction_class = prediction_class self._W = W; self._b = b def _get_model_params(self): #获取模型的参数,以便存储 with self._graph.as_default(): gvars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES) return {gvar.op.name: value for gvar, value in zip(gvars, self._session.run(gvars))} def _restore_model_params(self, model_params): #保存模型的参数 gvar_names = list(model_params.keys()) assign_ops = {gvar_name: self._graph.get_operation_by_name(gvar_name + '/Assign') for gvar_name in gvar_names} init_values = {gvar_name: assign_op.inputs[1] for gvar_name, assign_op in assign_ops.items()} feed_dict = {init_values[gvar_name]: model_params[gvar_name] for gvar_name in gvar_names} self._session.run(assign_ops, feed_dict = feed_dict) def fit(self, X, y, X_val = None, y_val = None): #fit函数,注意要输入验证集 n_batches = X.shape[0] // self.batch_size self._graph = tf.Graph() with self._graph.as_default(): self._build_graph(X, y) best_loss = np.infty best_accuracy = 0 best_params = None checks_without_progress = 0 max_checks_without_progress = 20 self._session = tf.Session(graph = self._graph) with self._session.as_default() as sess: self.init.run() for epoch in range(self.training_epoch): for batch_index in range(n_batches): X_batch, y_batch = self.random_batch(X, y) sess.run(self._training_op, feed_dict = {self._X:X_batch, self._y:y_batch}) loss_val, accuracy_val = sess.run([self._loss, self._accuracy], feed_dict = {self._X: X_val, self._y: y_val}) accuracy_train = self._accuracy.eval(feed_dict = {self._X: X_batch, self._y: y_batch}) if loss_val < best_loss: best_loss = loss_val best_params = self._get_model_params() checks_without_progress = 0 else: checks_without_progress += 1 if checks_without_progress > max_checks_without_progress: break if accuracy_val > best_accuracy: best_accuracy = accuracy_val #best_params = self._get_model_params() if epoch % self.display_step == 0: print('Epoch: {}\tValidaiton loss: {:.6f}\tValidation Accuracy: {:.4f}\tTraining Accuracy: {:.4f}' .format(epoch, loss_val, accuracy_val, accuracy_train)) print('Best Accuracy: {:.4f}\tBest Loss: {:.6f}'.format(best_accuracy, best_loss)) if best_params: self._restore_model_params(best_params) self._intercept = best_params['trainable_variables/weights'] self._bias = best_params['trainable_variables/bias'] return self def predict(self, X): with self._session.as_default() as sess: return self._prediction_class.eval(feed_dict = {self._X: X}) def _intercept(self): return self._intercept def _bias(self): return self._bias
实际运行效果如下(以Iris数据集为样本):
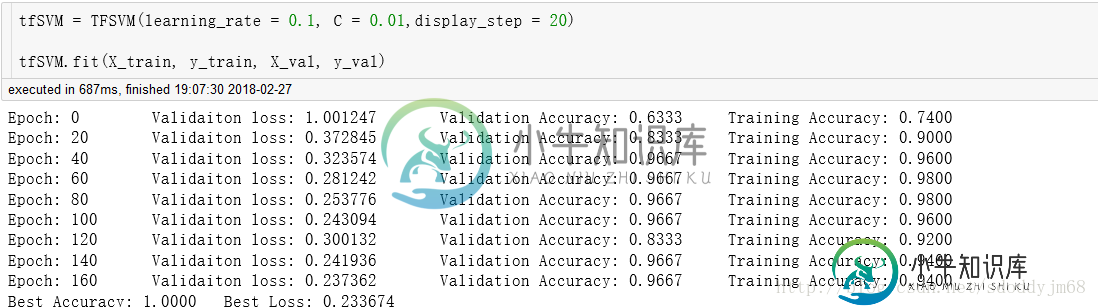
画出决策边界来看看:
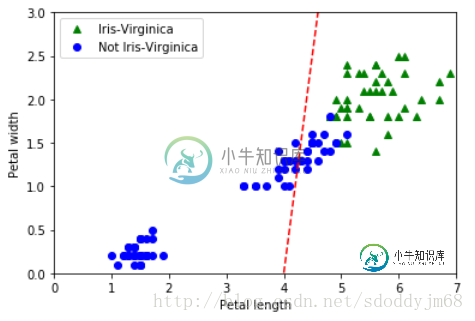
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
在本章中,将了解如何使用TensorFlow来实现XOR。在开始使用TensorFlow中的XOR之前,来看一下XOR表值。这将有助于我们了解加密和解密过程。 A B A XOR B 0 0 0 0 1 1 1 0 1 1 1 0 XOR密码加密方法基本上用于加密难以用强力方法破解的数据,即通过生成与适当密钥匹配的随机加密密钥。 使用XOR Cipher实现的概念是定义XOR加密密钥,然后使用此密
-
本文向大家介绍TensorFlow实现Batch Normalization,包括了TensorFlow实现Batch Normalization的使用技巧和注意事项,需要的朋友参考一下 一、BN(Batch Normalization)算法 1. 对数据进行归一化处理的重要性 神经网络学习过程的本质就是学习数据分布,在训练数据与测试数据分布不同情况下,模型的泛化能力就大大降低;另一方面,若训练过
-
我在Ubuntu 16.04上。我有:Python 2.7.12,Python 3.5.2,Tenorflow 1.2.0-rc1,原型3.3.0。 我想按照这个教程。 但我认为我的问题可以用这个测试更简洁地证明。py: 我无法实例化回归器。我得到(最后完全回溯): google.protobuf.text_format。ParseError: 48:12:消息类型"tenstorflow.Att
-
本文向大家介绍tensorflow实现softma识别MNIST,包括了tensorflow实现softma识别MNIST的使用技巧和注意事项,需要的朋友参考一下 识别MNIST已经成了深度学习的hello world,所以每次例程基本都会用到这个数据集,这个数据集在tensorflow内部用着很好的封装,因此可以方便地使用。 这次我们用tensorflow搭建一个softmax多分类器,和之前搭
-
本文向大家介绍使用Tensorflow实现可视化中间层和卷积层,包括了使用Tensorflow实现可视化中间层和卷积层的使用技巧和注意事项,需要的朋友参考一下 为了查看网络训练的效果或者便于调参、更改结构等,我们常常将训练网络过程中的loss、accurcy等参数。 除此之外,有时我们也想要查看训练好的网络中间层输出和卷积核上面表达了什么内容,这可以帮助我们思考CNN的内在机制、调整网络结构或者把
-
本文向大家介绍详解tensorflow实现迁移学习实例,包括了详解tensorflow实现迁移学习实例的使用技巧和注意事项,需要的朋友参考一下 本文主要是总结利用tensorflow实现迁移学习的基本步骤。 所谓迁移学习,就是将上一个问题上训练好的模型通过简单的调整使其适用于一个新的问题。比如说,我们可以保留训练好的Inception-v3模型中所有的参数,只替换最后一层全连接层。在最后一层全连接