
Linux运维从初级进阶为高级知识点总结

运维工程师在前期是一个很苦逼的工作,在这期间可能干着修电脑、掐网线、搬机器的活,显得没地位!时间也很碎片化,各种零碎的琐事围绕着你,很难体现个人价值,渐渐的对行业很迷茫,觉得没什么发展前途。
这些枯燥无味工作的确会使人匮乏,从技术层面讲这些其实都是基本功,对后期的运维工作会无形中带来一定的帮助,因为我也是这么过来的,能深刻体会到。所以在这个时期一定要保持积极向上的心态,持续的学习。在未来的某一天,相信会回报给你的!
好了,进入正题,根据我多年的运维工作经验,给大家分享下高级运维工程师学习路线。
初级
1、Linux基础
刚开始阶段需要熟悉Linux/Windows操作系统安装,目录结构、启动流程等。
2、系统管理
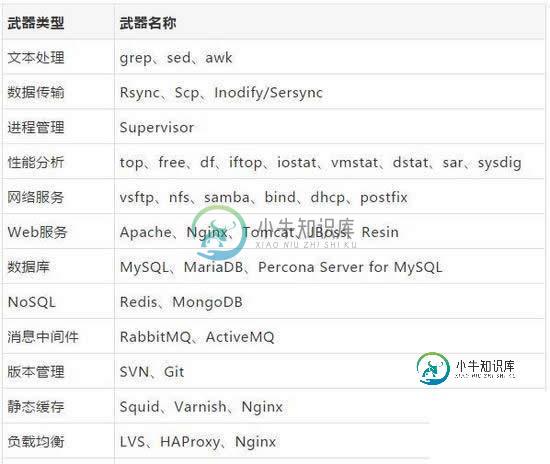
主要学习Linux系统,生产环境中基本都在字符界面完成工作,所以要掌握常用的几十个基本管理命令,包括用户管理、磁盘分区、软件包管理、文件权限、文本处理、进程管理、性能分析工具等。
3、网络基础
OSI和TCP/IP模型一定要熟悉。基本的交换机、路由器概念及实现原理要知道。
4、Shell脚本编程基础
掌握Shell基本语法结构,能编写简单的脚本即可。
中级
1、网络服务
最常用的网络服务一定得会部署,比如vsftp、nfs、samba、bind、dhcp等。
代码版本管理系统少不了,可以学习下主流的SVN和GIT,能部署和简单使用就可以了。
经常在服务器之间传输数据,所以要会使用:rsync和scp。
数据同步:inotify/sersync。
重复性完成一些工作,可写成脚本定时去运行,所以得会配置Linux下的定时任务服务crond。
2、Web服务
每个公司基本都会有网站,能让网站跑起来,就需要搭建Web服务平台了。
如果是用PHP语言开发的,通常搭建LAMP、LNMP网站平台,这是一个技术名词组合的拼写,分开讲就是得会部署Apache、Nginx、MySQL和PHP。
如果是JAVA语言开发的,通常使用Tomcat运行项目,为了提高访问速度,可以使用Nginx反向代理Tomcat,Nginx处理静态页面,Tomcat处理动态页面,实现动静分离。
不是会部署这么简单,还要知道HTTP协议工作原理、简单的性能调优。
3、数据库
数据库选择MySQL,它是世界上使用最为广泛的开源数据库。学它准没错!也要会一些简单的SQL语句、用户管理、常用存储引擎、数据库备份与恢复。
想要深入点,必须会主从复制、性能优化、主流集群方案:MHA、MGR等。NoSQL这么流行当然也少不了,学下Redis、MongoDB这两个就好了。
4、安全
安全很重要,不要等到系统被入侵了,再做安全策略,此时已晚!所以,当一台服务器上线后应马上做安全访问控制策略,比如使用iptables限制只允许信任源IP访问,关闭一些无用的服务和端口等。
一些常见的攻击类型一定得知道啊,否则怎么对症下药呢!比如CC、DDOS、ARP等。
5、监控系统
监控必不可少,是及时发现问题和追溯问题的救命稻草。可以选择学习主流的Zabbix开源监控系统,功能丰富,能满足基本的监控需求。监控点包括基本服务器资源、接口状态、服务性能、PV/UV、日志等方面。
也可以弄个仪表盘展示几个实时关键的数据,比如Grafana,会非常炫酷。
6、Shell脚本编程进阶
Shell脚本是Linux自动完成工作的利器,必须得熟练编写,所以得进一步学习函数、数组、信号、发邮件等。
文本处理三剑客(grep、sed、awk)得玩6啊,Linux下文本处理就指望它们了。
7、Python开发基础
Shell脚本只能完成一些基本的任务,想要完成更复杂些的任务,比如调用API、多进程等。就需要学高级语言了。
Python是运维领域使用最多的语言,简单易用,学它准没错!此阶段掌握基础就可以了,例如基本语法结构、文件对象操作、函数、迭代对象、异常处理、发邮件、数据库编程等。
高级
1、Web静态缓存
用户老喊着访问网站慢,看看服务器资源还很富裕啊!网站访问慢也许不是服务器资源饱和导致的,影响因素很多,例如网络、转发层数等。
对于网络,存在南北通信问题,之间访问会慢,这个可以使用CDN解决,同时缓存静态页面,尽可能将请求拦截在最上层响应,减少后端请求和响应时间。
如果不用CDN,也可以使用Squid、Varnish、Nginx这样的缓存服务实现静态页面缓存,放到流量入口处。
2、集群
单台服务器终究资源有限,抵抗高访问量肯定是无法支撑的,解决此问题最关键的技术就是采用负载均衡器,水平扩展多台Web服务器,同时对外提供服务,这样就成倍扩展性能了。负载均衡器主流开源技术有LVS、HAProxy和Nginx。一定要熟悉一两个!
Web服务器性能瓶颈解决了,数据库更为关键,还是采用集群,就拿学的MySQL来说,可以一主多从架构,在此基础上读写分离,主负责写,多从负责读,从库可水平扩展,前面再来个四层负载均衡器,承载千万级PV,妥妥的!
高可用软件也得会,避免单点的利器,主流的有Keepalived、Heartbeat等。
网站图片咋这么多呢!NFS共享存储支撑不过了,处理很慢,好弄!上分布式文件系统,并行处理任务,无单点,高可靠,高性能等特性,主流的有FastDFS、MFS、HDFS、Ceph、GFS等。初期的话我建议学习下FastDFS,能满足中小规模需求。
3、虚拟化
硬件服务器资源利用率很低,甚是浪费!可以把空闲多的服务器虚拟化,弄成很多个的虚拟机,每个虚拟机就是一个完整的操作系统。可以很大程度提高资源利用率。建议学习开源的KVM+OpenStack云平台。
虚拟机作为基础平台还可以,但应用业务弹性伸缩也太重量了吧!启动好几分钟,文件又这么大,快速扩展太费劲了!
好说,上容器,容器主要特点就是快速部署和环境隔离。一个服务封装到镜像中,分分钟钟可创建几百个容器。
主流的容器技术非Docker莫属了。
当然,生产环境单机Docker大多数情况下是无法满足业务需求的,可以部署Kubernetes、Swarm集群化管理容器,形成一个大的资源池,集中管理,为基础架构提供有力的支撑。
4、自动化
反反复复重复的工作,不但提高不了效率,价值也得不到体现。
一切运维工作标准化,例如环境版本、目录结构、操作系统等统一。在标准化基础上才能更方面的自动化,点点鼠标或者敲几个命令即可完成一项复杂的工作任务,爽哉爽哉!
因此,所有的操作尽可能自动化,减少人为失误,提高工作效率。
主流服务器集中管理工具:Ansible、Saltstack
这两个选择任意一个就行。
持续集成工具:Jenkins
5、Python开发进阶
可以再深入学习下Python开发,掌握面向对象编程。
最好也掌学习一个Web框架开发网站,例如Django、Flask,主要是开发运维管理系统,将一些复杂的流程写到平台中,再集成集中管理工具,可打造一个属于运维自己的管理平台。
6、日志分析系统
日志也很重要,定期的分析,可发现潜在隐患,提炼出有价值的东西。
开源的一套日志系统:ELK
学会部署使用,给开发提供日志查看需求。
7、性能优化
只会部署是远远不够的,性能优化能最大化提升服务承载量。
这块也是比较难的,也是高薪的关键点之一,为了钱也得下点功夫学习啊!
可以从硬件层、操作系统层、软件层和架构层维度展开思考。
意识
1、坚持
学习是一个很漫长的过程,是我们每个人需要用一生去坚持的事业。
贵在坚持,难在坚持,成在坚持!
2、目标
没有目标的不叫工作,没有量化的不叫目标。
每到一个阶段,制定一个目标。
比如:先定一个能达到的小目标,挣它一个亿!
3、分享
学会分享,技术的价值在于能有效地将知识传递到外界,让更多的人知道它。
只要人人都拿出一点东西来,想想会变成什么样?
方向对了,就不怕路远了!
十项Linux常识
1、GNU和GPL
GNU计划(又称革奴计划),是由Richard Stallman(理查德·斯托曼)在1983年9月27日公开发起的自由软件集体协作计划。它的目标是创建一套完全自由的操作系统。GNU也称为自由软件工程项目。
GPL是GNU的通用公共许可证(GNU General Public License,GPL),即“反版权”概念,是GNU协议之一,目的是保护GNU软件可以自由的使用、复制、研究、修改和发布。同时要求软件必须以源代码的形式发布。
GNU系统与Linux内核结合构成一个完整的操作系统:一个基于Linux的GNU系统,该操作系统在通常情况下称为“GNU/Linux”,或简称Linux。
2、Linux发行版
一个典型的Linux发行版包括:Linux内核,一些GNU程序库和工具,命令行shell,图形界面的X Window系统和相应的桌面环境,如KDE或GNOME,并包含数千种从办公套件,编译器,文本编辑器到科学工具的应用软件。
主流的发行版:
Red Hat Enterprise Linux、CentOS、SUSE、Ubuntu、Debian、Fedora、Gentoo
3、Unix和Linux
Linux是基于Unix的,属于Unix类,Uinx操作系统支持多用户、多任务、多线程和支持多种CPU架构的操作系统。Linux继承了Unix以网络为核心的设计思想,是一个性能稳定的多用户网络操作系统。
4、Swap分区
Swap分区,即交换区,系统在物理内存不够时,与Swap进行交换。即当系统的物理内存不够用时,把硬盘中一部分空间释放出来,以供当前运行的程序使用。当那些程序要运行时,再从Swap分区中恢复保存的数据到内存中。那些被释放内存空间的程序一般是很长时间没有什么操作的程序。
Swap空间一般应大于或等于物理内存的大小,同时最小不应小于64M,最大应该是物理内存的两倍。
5、GRUB的概念
GNU GRUB(GRand Unified Bootloader简称“GRUB”)是一个来自GNU项目的多操作系统启动引导管理程序。
GRUB是一个支持多种操作系统的启动引导管理器,在一台有多个操作系统的计算机中,可以通过GRUB在计算机启动时选择用户希望运行的操作系统。同时GRUB可以引导Linux系统分区上的不同内核,也可用于向内核传递启动参数,如进入单用户模式。
6、Buffer和Cache
Cache(缓存)位于CPU与内存之间的临时存储器,缓存容量比内存小的多但交换速度比内存要快得多。Cache通过缓存文件数据块,解决CPU运算速度与内存读写速度不匹配的矛盾,提高CPU和内存之间的数据交换速度。Cache缓存越大,CPU处理速度越快。
Buffer(缓冲)高速缓冲存储器,通过缓存磁盘(I/O设备)数据块,加快对磁盘上数据的访问,减少I/O,提高内存和硬盘(或其他I/O设备)之间的数据交换速度。Buffer是即将要被写入磁盘的,而Cache是被从磁盘中读出来的。
7、TCP三次握手
(1)请求端发送SYN(SYN=A)数据包,等待响应端确认
(2)响应端接收SYN,并返回SYN(A+1)和自己的ACK(K)包给请求端
(3)请求端接收到响应端的SYN+ACK包,再次向响应端发送确认包ACK(K+1)
请求端和响应端建立TCP连接,完成三次握手,开始进行数据传输。
8、linux系统目录结构
Linux文件系统采用带链接的树形目录结构,即只有一个根目录(通常用“/”表示),其中含有下级子目录或文件的信息;子目录中又可含有更下级的子目录或者文件的信息。
/:第一层次结构的根,整个文件系统层次结构的根目录。即文件系统的入口,最高一级目录。
/boot:包含Linux内核及系统引导程序所需的文件,例如kernel、initrd;grub系统引导管理器也在这个目录下。
/bin:基本系统所需要的命令,功能和"/usr/bin"类似,这个目录下的文件都是可执行的.普通用户也是可以执行的。
/sbin:基本的系统维护命令,只能由超级用户使用。
/etc:所有的系统配置文件。
/dev:设备文件存储目录.像终端、磁盘、光驱等。
/var:存放经常变动的数据,像日志、邮件等。
/home:普通用户的目录默认存储目录。
/opt:第三方软件的存放目录,比如用户html" target="_blank">自定义软件包和编译的软件包就安装到这个目录中。
/lib:库文件和内核模块存放目录,包含系统程序所需要的所有共享库文件。
9、硬链接和软链接
硬链接(Hard Link):硬链接是使用同一个索引节点(inode号)的链接, 即可以允许多个文件名指向同一个文件索引节点(硬链接不支持目录链接,不能跨分区链接),删除一个硬链接,不会影响该索引节点的源文件以及其下的多个硬链接。
ln source new-link
软连接(符号链接,Symbolic Link):符号链接是以路径的形式创建的链接,类似于windows的快捷方式链接,符号链接允许创建多个文件名链接到同一个源文件,删除源文件,其下的所有软连接将不可用。(软连接支持目录,支持跨分区、跨文件系统)
ln -s source new-link
10、RAID技术
磁盘阵列(Redundant Arrays of independent Disks,RAID),廉价冗余(独立)磁盘阵列。
RAID是一种把多块独立的物理硬盘按不同的方式组合起来形成一个硬盘组(逻辑硬盘),提供比单个硬盘更高的存储性能和数据备份技术。RAID技术,可以实现把多个磁盘组合在一起作为一个逻辑卷提供磁盘跨越功能;可以把数据分成多个数据块(Block)并行写入/读出多个磁盘以提高访问磁盘的速度;可以通过镜像或校验操作提供容错能力。具体的功能以不同的RAID组合实现。
在用户看来,RAID组成的磁盘组就像是一个硬盘,可以对它进行分区、格式化等操作。RAID的存储速度比单个硬盘高很多,并且可以提供自动数据备份,提供良好的容错能力。
RAID级别,不同的RAID组合方式分为不同的RAID级别:
RAID 0:称为Stripping条带存储技术,所有磁盘完全地并行读,并行写,是组建磁盘阵列最简单的一种形式,只需要2块以上的硬盘即可,成本低,可以提供整个磁盘的性能和吞吐量,但RAID 0没有提供数据冗余和错误修复功能,因此单块硬盘的损坏会导致所有的数据丢失。(RAID 0只是单纯地提高磁盘容量和性能,没有为数据提供可靠性保证,适用于对数据安全性要求不高的环境)
RAID 1:镜像存储,通过把两块磁盘中的一块磁盘的数据镜像到另一块磁盘上, 实现数据冗余,在两块磁盘上产生互为备份的数据,其容量仅等于一块磁盘的容量。当数据在写入一块磁盘时,会在另一块闲置的磁盘上生产镜像,在不影响性能情况下最大限度的保证系统的可靠性和可修复性;当原始数据繁忙时,可直接从镜像拷贝中读取数据(从两块硬盘中较快的一块中读出),提高读取性能。相反的,RAID 1的写入速度较缓慢。RAID 1一般支持“热交换”,即阵列中硬盘的移除或替换可以在系统运行状态下进行,无须中断退出系统。RAID 1是磁盘阵列中硬盘单位成本最高的,但它提供了很高的数据安全性、可靠性和可用性,当一块硬盘失效时,系统可以自动切换到镜像磁盘上读写,而不需要重组失效的数据。
RAID 0+1:也被称为RAID 10,实际是将RAID 0和RAID 1结合的形式,在连续地以位或字节为单位分割数据并且并行读/写多个磁盘的同时,为每一块磁盘做镜像进行冗余。通过RAID 0+1的组合形式,数据除分布在多个盘上外,每个盘都有其物理镜像盘,提供冗余能力,允许一个以下磁盘故障,而不影响数据可用性,并且有快速读/写能力。RAID 0+1至少需要4个硬盘在磁盘镜像中建立带区集。RAID 0+1技术在保证数据高可靠性的同时,也保证了数据读/写的高效性。
RAID 5:是一种存储性能、数据安全和存储成本兼顾的存储解决方案。RAID 5可以理解为是RAID 0和RAID 1的折衷方案,RAID 5至少需要三块硬盘。RAID 5可以为系统提供数据安全保障,但保障程度要比镜像低而磁盘空间利用率要比镜像高。RAID 5具有和RAID 0相近似的数据读取速度,只是多了一个奇偶校验信息,写入数据的速度比对单个磁盘进行写入操作稍慢。同时由于多个数据对应一个奇偶校验信息,RAID 5的磁盘空间利用率要比RAID 1高,存储成本相对较低,是目前运用较多的一种解决方案。
-
本系统文章整理 JavaScript 高级的知识点,形成系统的知识体系。包括基础深入(数据类型、数据变量与内存、对象、函数、回调函数、this等),函数高级(原型与原型链、执行上下文与执行上下文栈、作用域与作用域链、闭包),对象高级(对象创建模式、继承模式),线程机制与事件机制(进程与线程、浏览器内核、定时器、事件循环模型、Web Workers),内存溢出与内存泄漏。
-
高级知识用法 1.高级知识类型 知识库除了普通问答以外,系统还提供多种知识展现形式,方便通过组合不同形式的知识形成多轮对话及多维知识体系,高级知识类型总体包括以下类型: 智能录入-问题链接/条件答案:通过设定问题的进一步链接和条件,帮助用户点击下一个答案。 智能录入-动态答案/变量答案:通过在答案中添加动态变量,在多个问题中添加统一变量,并且针对变量进行变更时,会将所有变量进行变更。 智能录入-随
-
本文向大家介绍Linux shell知识点汇总,包括了Linux shell知识点汇总的使用技巧和注意事项,需要的朋友参考一下 实际上Shell是一个命令解释器,它解释由用户输入的命令并且把它们送到内核。不仅如此,Shell有自己的编程语言用于对命令的编辑,它允许用户编写由shell命令组成的程序。Shell编程语言具有普通编程语言的很多特点,比如它也有循环结构和分支控制结构等,用这种编程语言编写
-
虽然是进阶知识, 但是也是必学内容.
-
本文向大家介绍python线程优先级队列知识点总结,包括了python线程优先级队列知识点总结的使用技巧和注意事项,需要的朋友参考一下 Python 的 Queue 模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列 PriorityQueue。 1、说明 这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队
-
我相信,明智地使用Hibernate的二级缓存可以很好地提高我的应用程序的性能,为此,我已经开始从internet和Hibernate课程学习它。虽然关于二级缓存及其工作方式有很多很好的解释,但我的目标是从我没有找到的具体问题开始,准确地了解事物的工作方式,因此我将问一些关于Hibernate缓存的一般问题,特别是关于二级缓存的问题。 A、 我很乐意回答问题,即使有些问题看起来很明显或无关紧要 >