《兴业数金》专题
-
Talend作业条件执行的首选模式
谢了。
-
Submit Spark作业未加载spark-cloudant:2.0.0-S_2_11包
那么需要在命令中做哪些更改来加载包呢? 此包的详细信息显示在https://mvnrepository.com/artifact/cloudant-labs/spark-cloudant/2.0.0-S2.11中
-
从Spring集成启动Spring批处理作业
我需要从远程SFTP服务器下载一个文件,并使用spring batch处理它们。我已经实现了使用Spring集成下载文件的代码。但我无法从Spring集成组件启动Spring批处理作业。我有以下代码: 但这不起作用(上一个方法中的错误),因为找不到文件类型的bean。我不能把这两部分连在一起。如何连接集成和批处理?
-
Jenkins-在从机中只运行单个作业
我有一个詹金斯服务器50多个工作。我添加了一个新的要求与特定用户执行。因此,我创建了slave节点(具有特定配置的相同主机),并将其限制为slave。但我以前的工作都开始用主+从了。所以他们开始失败了(因为我使用了另一个用户)。 问候。
-
带有扫描器输入Java作业问题
我努力解决问题,我真的很接近,但我很困惑为什么我的程序似乎跳过,没有读取输入学生姓名部分我的输入。当学生数为1时,似乎也有这个问题。任何帮助都将不胜感激!:]
-
带Spring Boot的Google app engine中的Cron作业
还有关于如何在App Engine中创建Cron作业的链接 我正在使用Spring Boot for Google App Engine,那么我如何使用Spring Boot进行Cron作业呢?
-
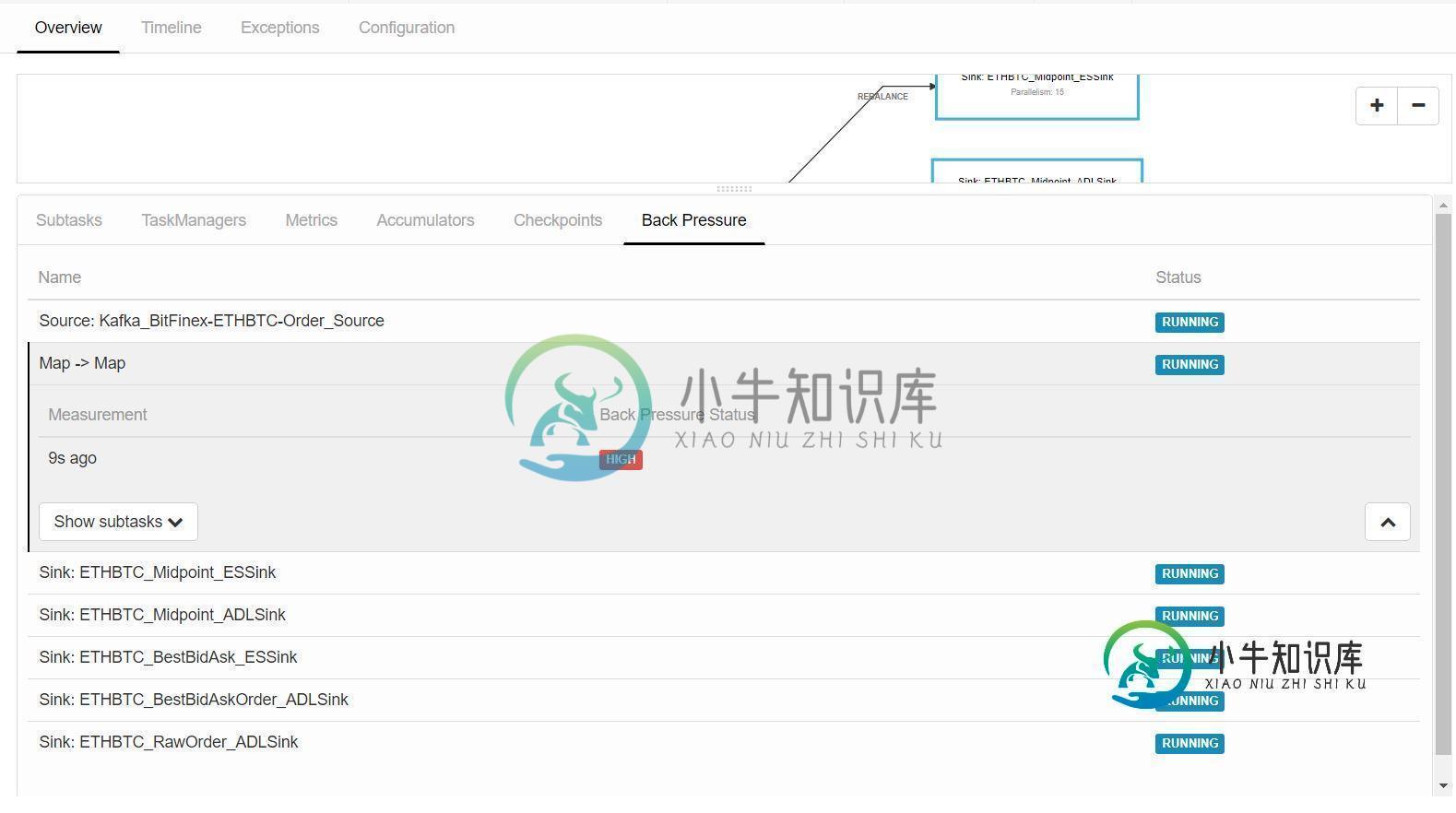 如何处理flink流作业中的背压?
如何处理flink流作业中的背压?我正在运行一个流式flink作业,它消耗来自kafka的流式数据,在flink映射函数中对数据进行一些处理,并将数据写入Azure数据湖和弹性搜索。对于map函数,我使用了1的并行性,因为我需要在作为全局变量维护的数据列表上逐个处理传入的数据。现在,当我运行该作业时,当flink开始从kafka获取流数据时,它的背压在map函数中变得很高。有什么设置或配置我可以做以避免背压在闪烁?
-
部署IBM worklight企业服务器时的BeanCreationException
我们试图通过Tomcat在Ubuntu服务器上部署Worklight Enterprise edition 虽然我们成功地完成了几个步骤,但在启动Tomcat并运行War文件时遇到了一个错误。我们使用MySQL作为数据库。 我们面临的具体错误是“.BeanCreationException:错误创建名为'Deploy Service'的bean。 严重:FWLST0003E:==========启
-
如何在Quartz中运行丢失的作业?
我有每天的cron作业,它应该在00:00运行在所有时区,但当应用程序在维护(可能是一两个小时),部分计划的作业丢失。 是否可以运行在维护期间错过的任务? 在Quartz shoutdown之前(从记录): 石英启动后:
-
Quartz Scheduler:如何将作业分组在一起?
我想问是否有人有同样的问题与石英调度器。我使用Trigger和JobKeys创建了作业,在这些作业中设置了groupnames。但当我打印出已设置的组时,它总是默认的。 如何设置此groupname以最终能够将作业分组在一起,最重要的是只取消指定的组?使用类似于下面这样的代码: 输出:
-
在Slurm群集上运行批处理作业
所以我现在花了几个小时试图解决这个问题,并希望得到任何帮助。
-
Docker桌面没有运行Windows 11企业版
一旦启动 Docker 桌面 4.4.4 版本 ,Docker 服务停止并出现以下错误
-
 百词斩商业分析二面经分享
百词斩商业分析二面经分享1. 你觉得数据分析师应该具有哪些能力? * 首先是硬实力,SQL、Excel、PPT等分析数据和展示数据的工具需要会 * 其次是软实力,当我们通过数据分析获得到洞见后,需要向别人展示,说服别人接受我们的建议 2. 你过去使用过哪些图表来直观的表达你的观点?聊聊你在案例大赛的经历就可以。 * 使用频次最高的是柱状图和折线图,可以表现事物随时间的波动趋势 * 其次是散点图,可以用两个维度给事物排名
-
 美团-快驴商业分析-实习面经
美团-快驴商业分析-实习面经面试时长约一个钟 1. 面试官介绍部门及小组情况 2. 自我介绍 3. 讲项目(40min) 深挖 深挖 深挖 中间穿插着一些ab test/ 统计学基础 比如 ab sample size/ 一二类错误定义/ outlier怎么办 / matching怎么做(lz简历提到才问的) 4. sql *2 口述 我本来写在ipad上 但是虚拟背景 直接全糊上 4. 反问 白天上班已经上懵了 根本没时间
-
 滴滴商业分析日常实习面经
滴滴商业分析日常实习面经bg:一段数分实习+中台运营 一面(25min): 1.自我介绍 2.简历中提到用过XGB模型,介绍一下:特征选了什么,最后的重要因素是什么(结合落地性),准确率多少 复盘:下次介绍的时候可以先明确自变量和因变量分别是什么,当时以为自己star法则说的还挺清楚的,结果输出一通之后,面试官的第一个问题就是x和y是什么...... 3.case题:目前滴滴在上线阶段,如何做好用户回流,有什么分析思路