《兴业数金》专题
-
在使用 Kafka 消息时计划作业
我想建立一个单一的Spring Boot应用程序,同时做多种不同的任务。我在互联网上做了研究,但我找不到任何出路。我来详细说说。我希望每隔一段时间启动一次作业,例如一天一次。我可以用Spring石英来做。我也想在一个专用的互联网地址上听信息。消息将来自Apache Kafka平台。因此,我想将Kafka集成用于Spring框架。它实际上是否适用(始终监听消息并按时执行计划的作业)
-
多节点环境中的计划作业
我正在进行一项预定的工作,该工作将以一定的间隔运行(例如每天下午1点),通过Cron安排。我正在使用Java和Spring。 编写计划作业非常简单 - 它确实如此:从db中抓取人员列表将某些条件,为每个人做一些计算并触发消息。 我正在本地和测试中开发单节点环境,但是当我们投入生产时,它将是多节点环境(带有负载均衡器等)。我关心的是多节点环境会如何影响计划的作业? 我的猜测是,我可能(或很可能)最终
-
Hbase mapreduce作业:所有列值均为空
我正在尝试创建一个地图减少工作在Java的表从一个HBase数据库。使用这里的示例和internet上的其他内容,我成功地编写了一个简单的行计数器。然而,试图编写一个实际对列中的数据执行某些操作的程序是不成功的,因为接收的字节总是空的。 我的司机工作的一部分是这样的: 如您所见,该表称为。我的映射器如下所示: 一些注意事项: 表中的列族只是。有多个列,其中一些列称为和(第一次看到); 即使值正确显
-
抢占式最短作业优先排序
假设我有两个进程等待使用抢先最短作业优先(SJF)执行。 在 Time = 2 时,两个进程的突发时间相同,即 3。SJF 排序会运行进程 2,因为它具有更高的初始突发时间,还是会运行进程,因为它们的突发时间当前相同? 谢谢:)
-
家庭作业-抢占式优先调度
嗨,伙计们。我们被分配了一个关于抢占优先调度的任务,我真的不知道如何做到这一点,因为两个或多个进程具有相同的优先级编号。 我必须做一个甘特图,计算周转时间和平均等待时间。 如果可能的话,你们能否发布一个关于如何做到这一点的分步解决方案,以便我可以研究它是如何完成的。 谢谢你们的帮助。
-
从crontab中删除过期的cron作业
我的产品需要对用户发送给其他用户的每条消息进行cronjob处理。此cronjob被添加到服务器上的crontab中。一切正常。现在,一旦任务完成,有没有办法从中删除过期的cronjob条目? 由于消息数量巨大,我的 crontab 不断增长,因此我想清理旧的作业条目。任何巧妙的方法来实现它?
-
从Spring批处理管理隐藏作业
我想从Spring批处理管理作业的选项卡上的“Job Names Registered”列表中隐藏一些作业。 我使用的是旧版本“spring-batch-core-2.2.6.release”和“spring-batch-admin-manager-1.3.0.release”,在org/springframework/batch/core/configuration/xml/spring-bat
-
Spring Boot REST-对单个作业使用ThreadPoolTaskExecutor
我加入了公司的一个新团队,我看到他们广泛使用“ThreadPoolTaskExecutor”。它基本上是前端的后端REST应用程序,它调用其他SOAP API并将结果返回给客户机--只是一个传递。99%的情况下,每个RESTendpoint只调用单个SOAP API,并将json格式的响应返回给客户机。然而,尽管这只是一个SOAP调用,但它们使用了“ThreadPoolTaskExecutor”并
-
在map reduce作业之间传递变量
我无法理解如何将变量(输出)从Job1传递到Job2。 假设我的Job1是WordCount。N=230的最终减速器输出。 我的第二份工作的逻辑需要这些信息。但我不想把它作为映射器输入。我希望输入与Job1相同。 我不喜欢使用计数器,因为我读到它不太可靠。 谢谢
-
添加跟踪和span id到Flink作业
我需要向集群中运行的Flink作业添加track和span id,请求流如下所示 使用者-- 我使用Spring Boot来创建我的rest API,并使用Spring Sleuth来添加跟踪和span id到生成的日志中,当调用rest API时添加跟踪和span id,当消息被放在Kakfa-toption-1上时也添加跟踪和span id,但我不能弄清楚如何添加跟踪和跨度ID,同时在Flin
-
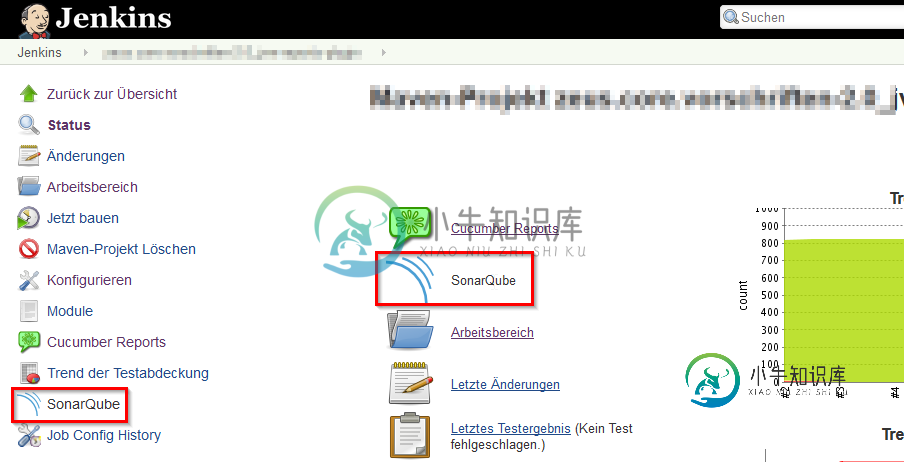 Jenkins作业上的SonarQube链接不可用
Jenkins作业上的SonarQube链接不可用我用... 詹金斯1.596.2(也试用1.609.1) Jenkins Sonarqube-插件2.1(也试用了2.2.1) Maven 3.3.1 sonar-maven-plugin:2.6(配置SonarQube构建后操作时) Sonar runner 2.4(配置SonarQube分析构建步骤时) 在浏览了jenkins sonarqube-plugin的源代码之后,我发现似乎坏了。它解
-
使用spark submit运行spark作业时的
我试图运行火花作业,基本上加载数据在卡桑德拉表。但它也产生了以下错误。
-
向谷歌云平台提交Spark作业
每个人都试着用https://console.developers.google.com/project/_/mc/template/hadoop? Spark对我来说安装正确,我可以SSH进入hadoop worker或master,Spark安装在/home/hadoop/Spark install/ 我可以使用spark python shell在云存储中读取文件 lines=sc.text
-
避免OLTP上的Spring批处理作业
我们有一个用Spring Boot编写的REST API。这个应用程序的一部分是每天运行的Spring批处理作业。我希望Spring批处理作业完成后,一个退出代码返回到启动应用程序的shell脚本,因此我在main方法中添加了。我才意识到这会导致整个Spring Boot应用程序退出,而这是我们不想要的。我正在寻找一种方法来执行Spring批处理作业,向调用它的shell脚本返回退出代码,并使Sp
-
并行Spring批作业的推荐方法
Spring批处理集成文档解释了如何使用远程分块和分区的步骤,请参见 http://docs.spring.io/spring-batch/trunk/reference/html/springbatchintegration.html#Externalizing-batch-process-execution 我们的工作不包括简单的读取器/处理器/写入器步骤。因此,我们只想让整个作业并行运行,每