《兴业数金》专题
-
 作业帮 一面
作业帮 一面情况说明:本来在boss上投的后端岗位,不知道为啥直接给安排了运维岗位的面试。 对于面向对象的理解,以及抽象、多态、代码复用,Abstract Class ,Interface AOP,面向切片编程,动态代理,反射 了解哪些数据结构 单向链表和双向链表的区别(回答时间复杂度平均下来都是O(n),这有问题吗?) 那为什么使用双向链表 乐观锁悲观锁 HashMap为什么线程不安全 Concurrent
-
从作业内部启动作业,这样父作业就不应该等待子作业在Spring批处理中完成?
-
如何在Spring Batch中从ItemReader访问作业参数?
问题内容: 这是我的一部分: 这是商品阅读器: 这是Spring Batch在运行时所说的: 怎么了 在Spring 3.0中,我在哪里可以了解有关这些机制的更多信息? 问题答案: 如前所述,您的阅读器需要进行“逐步”调整。您可以通过注释完成此操作。如果您将该注释添加到阅读器,则它应该对您有用,如下所示: 该范围默认情况下不可用,但是如果您正在使用XML名称空间,则该范围将不可用。如果不是这样,请
-
使用Java代码从jenkins作业中获取参数
问题内容: 我有一个参数化的詹金斯工作正在访问我的插件。 在Java的插件代码内部,我需要使用这些参数才能 触发jenkins中的另一项工作。我无法获取这些参数,现在这 是一个非常高优先级的问题。我尝试过 stackoverflow上可用的多种解决方案,例如,尝试访问环境变量, 但未收到参数的值。例如,我的参数是“ REPOS”,我 需要它的值,我尝试过: 但它返回null。 另外,尝试: 但它会
-
Spring批处理访问步骤内的作业参数
我有以下Spring批处理作业配置: 我用以下代码开始这项工作: 如何从作业步骤访问参数?
-
django中业务逻辑和数据访问的分离
问题内容: 我正在Django中编写一个项目,我发现文件中有80%的代码。这段代码令人困惑,并且在一段时间之后,我不再了解实际发生的事情。 这是困扰我的事情: 我发现模型级别(应该只负责处理数据库中的数据)在发送电子邮件,使用API到其他服务等方面也很丑陋。 另外,我发现在视图中放置业务逻辑也是不可接受的,因为这样很难控制。例如,在我的应用程序中,至少有三种方法来创建的新实例,但从技术上讲,它
-
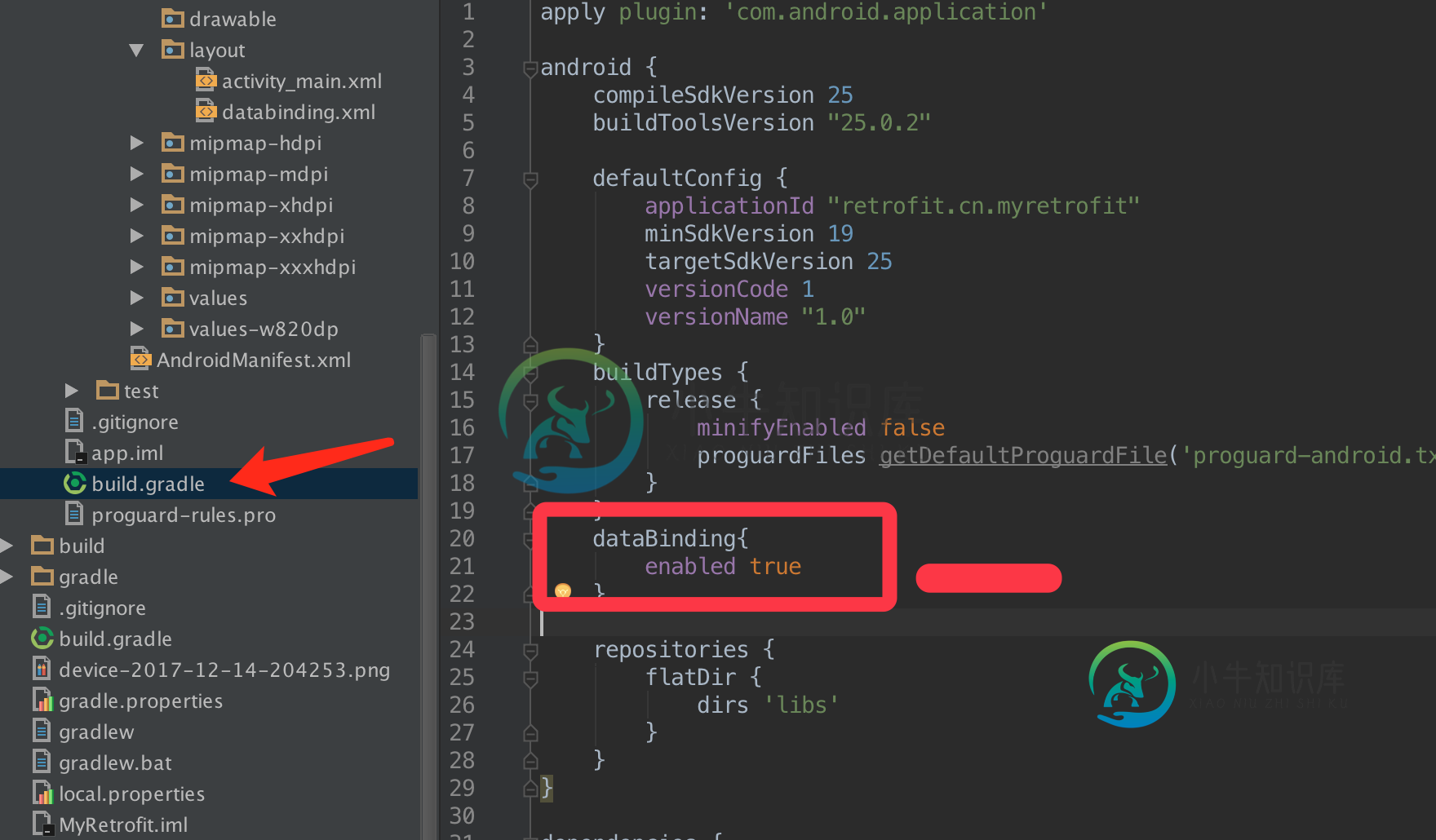 浅析Android企业级开发数据绑定技术
浅析Android企业级开发数据绑定技术本文向大家介绍浅析Android企业级开发数据绑定技术,包括了浅析Android企业级开发数据绑定技术的使用技巧和注意事项,需要的朋友参考一下 这篇文章通过发文的方式让大家知道什么是数据绑定,以及为什么要用数据绑定等问题,有助于大家理解Android企业级开发数据绑定技术。 首先要了解什么是数据绑定?为什么要用数据绑定?怎么用数据绑定? 语法的使用 简单例子,数据绑定textview控件,一般
-
处理Spring批处理中的作业参数验证
我正在使用Spring batch进行批处理,在进行批处理之前,我想验证所有作业参数,如productName、productID、开始日期、结束日期、productType,如果这些作业参数为null或包含错误值,我必须使验证步骤失败,并使作业失败。 我已经编写了验证步骤和Tasklet,在我的Tasklet中,我计划处理作业参数验证(对所有作业参数执行空检查)。因为我是第一次做Spring批处
-
使用反应式数据库编写业务逻辑
我正在编写一个向Android手机发送通知的反应式api。发送通知的过程需要从手机访问令牌代码以将消息推送给它。为了实现这一点,我在服务器端创建了一个endpoint来接收来自手机的令牌。我的问题是保存令牌,然后在上面描述的过程中使用它。这是TokenController、TokenService、TokenRepository和Token POJO: 为了发送通知,我有一个通知控制器,需要访问数
-
如何从python操作符创建数据流作业?
当我通过命令行运行Beam管道时,使用direct runner或dataflow runner,它工作得很好。。。 例子: 但是当我尝试使用空气流时,我有两个选项,bash操作符或python操作符。 使用bash操作符会成功,但会限制我使用气流功能的能力。 但是我想做的是作为python操作员运行它。所以我将模块导入到airflow dg文件中,然后作为python操作符运行它。 如果我使用本
-
如何控制平行Spring批量作业的数量
我有一个报告生成应用程序。由于这类报告的准备是重量级的,因此它们是用Spring Batch异步准备的。对此类报告的请求是通过使用HTTP的REST接口创建的。 目标是REST资源只需对报告执行进行排队并完成(如文档中所述)。因此,为JobLauncher提供了一个TaskExecutor: 由于报告确实是重量级的,在给定的时间内只能生成特定数量的报告。为了能够将Spring Batch配置为一次
-
在Spring batch中查询批处理作业元数据
在这个应用程序中,我使用了Spring Data JPA。它是另一个使用Spring Batch并创建这些表的应用程序。换句话说,我只想运行一个连接查询,并将它直接映射到我的定制对象,只需要一些必要的字段。在可能的范围内,我希望避免为这两个表制作分开的模型。但我不知道这里最好的方法。
-
Spring批处理中的数据中间作业分区
第1步--第一步从数据库中读取某些事务,并生成一个记录ID列表,这些记录ID将通过jobContext属性发送到第2步。 步骤2-这应该是一个分区步骤:从步骤应该基于从步骤1获得的列表进行分区(每个线程从列表中获得不同的Id),并在不相互干扰的情况下执行它们的读/处理/写操作。 我的问题是,尽管我希望根据步骤1产生的列表对数据进行分区,但spring在步骤1开始之前就配置了步骤2(因此调用了分区器
-
django中业务逻辑和数据访问的分离
null 我的数据库的实体,持久性级别:我的应用程序保留哪些数据? 我的应用程序的实体,业务逻辑级别:我的应用程序做什么? 在Django有哪些实施这种办法的良好做法?
-
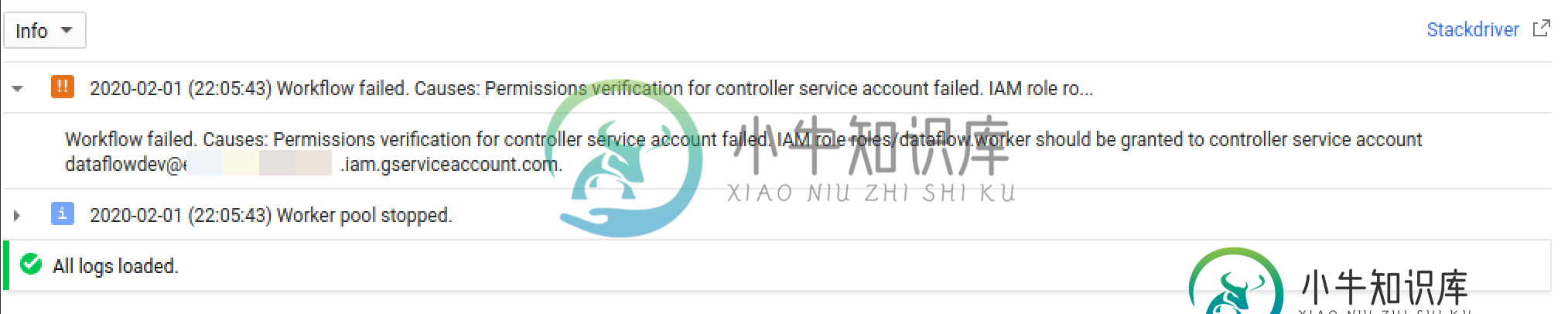 服务帐户执行批处理数据流作业
服务帐户执行批处理数据流作业我需要使用服务帐户执行数据流作业,下面是同一平台中提供的一个非常简单和基本的wordcount示例。 根据这一点,GCP要求服务号具有数据流工作者的权限,以便执行我的作业。即使我已经设置了所需的权限,错误仍然出现时,堰部分会出现: 有人能解释这种奇怪的行为吗?太感谢了