《上海爱数》专题
-
 海信互联网产运 一面面经
海信互联网产运 一面面经自我介绍 深挖实习 觉得实习对自己的哪些方面有锻炼 实习中出现突发事件你是怎么处理的 对这份工作的理解 对互联网产品运营的理解 这个岗位需要具备什么能力 专业能为这个岗位有什么帮助 未来想定居的城市 职业规划 反问环节 #非技术面试记录#
-
 作业帮海外用研运营凉经
作业帮海外用研运营凉经时间:25分钟 1.自我介绍 2.简历深挖 1)细问问卷调查项目经历(包括项目周期为什么这么长?问卷停留时长改善的原因是什么?项目回收数据不错,怎么做到的?有没有具体的激励等等) 2)如何触达海外用户进行调研和访谈 这个问题回答得比较差,简单回答了针对用户画像,寻找用户痛点,针对未解决的问题进行定性与定量研究之类,但总感觉不是面试官想要的,不知道如何把这个宽泛的问题回答得细致。 3)职业规划是什么
-
 前端 - uniapp app端实现海报功能?
前端 - uniapp app端实现海报功能?uniapp项目app端实现下载海报 现在的代码如下: html js 原先是下载二维码,现在换成下载海报,海报里显示@/static/img/codeImg.jpg,school_name、classes_name跟一个背景色background: #f3af1e,还有二维码codeImg,下载的海报图样式跟下面的图片一样,关闭跟下载按钮不要,其他都要 大佬们,修改上面的代码如何实现下载海报功能
-
 珠海 东信和平 java一面面经
珠海 东信和平 java一面面经1.自我介绍 2.讲讲JWT 3.数学怎么样? 4.加密算法你知道哪一些? 5.RSA是对称加密还是非对称加密?RSA原理 非对称,刚好说反 6.讲讲Nginx,说说你使用中如何出错以及解决的? 7.如果只有一个端口,Nginx转发,你怎么知道是哪一个端口转发的? .....不会 8.你这种外卖项目我看过好多次了,你们怎么都一样啊? 项目组人比较多哈哈哈哈(bushi) 9.讲讲Mysql存储引擎
-
 海康图像处理通用素质面
海康图像处理通用素质面一开始个人自我介绍 问问为啥想找这个领域的工作 说一下自己最心仪的项目或论文 如何学习这个领域的,学习过程 ~~~#海康威视信息集散地#
-
 鱼海科技 二面 C++ 面经 实习
鱼海科技 二面 C++ 面经 实习正好是高性能异构计算相关的岗位 主要做高性能计算,解方程那些 一面hr面内容见动态 二面技术面内容: 自我介绍 内存分级 GPU内存 影响GPU的硬件因素 递归的优缺点 深度优先和广度在解方程组的区别 手搓CUDA C++静态变量 C++代码数多少 代码这么少在干什么?(看c++ primer,八股没问可惜了) 堆栈的区别 还以为项目是图形学之类的,实际是深度学习 C++八股问得比较少 主要还是项
-
 东方海外 软件工程师面经
东方海外 软件工程师面经4月28号上午收到hr电话确认意向,春招也算是有个去处,五一放假没事记录一下面经 时间线: 2月21号投递 3月3号中远集团考试(行测+英语) 3月13号心理测评 4月7号技术笔试(牛客网平台,计算机基础+前后端知识+1道leetcode简单题) 4月19号面试(只有一面,两个面试官 hr+技术主管) 面试时间45min 技术: 1.自我介绍 2.讲一下项目中权限管理怎么做的 3.怎么保证接口安全
-
如何利用PHP curl设置海康威视相机参数
顺便说一下,这是相机对GET/system/deviceinfo的响应: 之前,我尝试使用所有三种EOL类型(Mac、linux、DOS),然后将它们全部删除,如上面的代码所示。我知道身份验证是有效的,因为我能从摄像机里读到任何东西。我还可以成功地发送没有数据或XML块要求的PUT命令,例如重新启动。所以我怀疑通过curl发送XML的方式存在一些问题。另外,我可以在登录时通过网络浏览器更改设备名称
-
 面经-百度网盘海外版-数据分析实习生
面经-百度网盘海外版-数据分析实习生一面 1.SQL题1 表a 用户注册表: uid、注册日期、地区 表b 用户活跃表: uid、登陆日期 留存有两种活跃用户留存和新增用户留存 计算注册用户次日留存 日期的加减函数 date_sub(日期,interval 1 day) 2.SQL题2 成交信息表: uid 成交类别 成交日期 所属地区 计算最近三天每个地区top3销量的产品 3.业务题 推测五道口一家奶茶店一个月的销售额 二面 B
-
 海尔提前批-数据挖掘分析师一面面经
海尔提前批-数据挖掘分析师一面面经1、自我介绍。 2、介绍自己做过的一个项目。 3、追问项目中的细节。 4、意向在青岛工作吗 反问 1、入职后会有培训吗 2、入职之后需要做哪些工作。 双人面试,没开摄像头,应该是同事面。感觉面试官都很友善。 虽然海尔在知乎被喷的挺惨,但面试印象还不错hhh 更新:关于牛友们的问题统一回答一下 1.有无英语测试 无 2. 测评后多久收到面试通知 3天左右,电话通知。之后短信发了面试链接。 3.有
-
 海康威视数字技术 交互设计 面试分享
海康威视数字技术 交互设计 面试分享面试过程:主要是通过网上投递,然后突然打电话面试,说稍后还会有面试。具体就聊了一下项目经历,人员分配,迭代周期什么的,每个问题都是抓住你的回答提问的,感觉很随机,没有提前准备过的样子,最后介绍了一下部门的产品还有工作流程。 面试官问的面试题: 1、说一下你的作品,你是怎么调研的,调研过程具体可以详细描述吗? 2、你们平时工作内容怎么分配的? 3、一个项目迭代周期是多久? 4、会加班吗? 5、你觉得
-
上海有多少辆自行车?请提供一个可行的解决该问题的思路
本文向大家介绍上海有多少辆自行车?请提供一个可行的解决该问题的思路相关面试题,主要包含被问及上海有多少辆自行车?请提供一个可行的解决该问题的思路时的应答技巧和注意事项,需要的朋友参考一下 上海市的自行车数量=私人自行车数量+共享单车数量 私人自行车数量=该城市总人数X能够骑自行车的人数X有自行车人数比例 共享单车数量=该城市总人数X能够骑自行车的人数X无自行车人数比例/每辆车每天可服务的用户数 其
-
 请结合在播影视剧,对比腾讯、优酷和爱奇艺三家在付费内容推广策略上的差异。
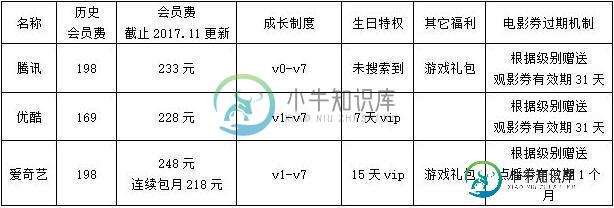
请结合在播影视剧,对比腾讯、优酷和爱奇艺三家在付费内容推广策略上的差异。本文向大家介绍请结合在播影视剧,对比腾讯、优酷和爱奇艺三家在付费内容推广策略上的差异。相关面试题,主要包含被问及请结合在播影视剧,对比腾讯、优酷和爱奇艺三家在付费内容推广策略上的差异。时的应答技巧和注意事项,需要的朋友参考一下 会员制度: 视频网站会员福利基本差不多,主要包括抢先看剧、免费片库、送电影券、跳广告、高清画质、下载加速等,其中爱奇艺和腾讯都专门有游戏礼包。 积分商城: 为了增加用户活跃
-
就餐辛普森:数一数与酒店相匹配的海龟
我正在使用repast simphony groovy API编程一个模拟。 有一个方法count(myTurtles),它允许我计算特定类myTurtle的代理数(turtles)。 我的问题是:有没有办法过滤这个计数,这样我就只能得到与某个属性(形状、颜色、大小…)的特定值相匹配的海龟?
-
 百度上海ACG测开二面面试官,你的面试水平和态度令百度蒙羞
百度上海ACG测开二面面试官,你的面试水平和态度令百度蒙羞上周面完百度一面,自己感觉答的不是很好,以为G了,没想到周日这个面试官约我二面,我就感觉大概率kpi面,但还是本着尊重百度的态度,抽空准备了一会,但没想到这kpi面,也太不把面试者当人看了吧 1.面试官态度不端正: a)面试迟到,上线后未解释迟到原因 b)在我开摄像头自我介绍的情况下,面试官不开摄像头,不尊重候选人 c)面试官网络卡顿导致听不清问题并且在我回答后由于网络卡顿,需要我重复回答 d)在