《万集科技》专题
-
 合肥天源迪科 - Java
合肥天源迪科 - Java自我介绍 还有没有做过别的项目,介绍一下 网关 为什么在网关层用Dubbo 为什么用 springboot,有什么好处 介绍一下rocketmq rocketmq怎么避免重复消费 mysql索引 介绍一下B+树 redis数据结构 redis为什么性能高 分布式锁 反问
-
7、Set集合与Map集合
Map和Set都叫做集合,但是他们也有所不同。Set常被用来检查对象中是否存在某个键名,Map集合常被用来获取已存的信息。 Set Set是有序列表,含有相互独立的非重复值。 创建Set 既然我们现在不知道Set长什么样,有什么价值,那么何不创建一个Set集合看看呢? 创建一个Set集合,你可以这样做: let set = new Set(); console.log(set);
-
Firestore:新集合与子集合
我正在尝试为firestore中的社交媒体应用程序组织数据。为帖子创建一个新集合或将其放入用户的子集合更好吗? 深度应该是一样的,但是一种方式比另一种方式有什么优势吗? 创建新集合: 职位(集合) 用户(集合) 用户中的子集合: 用户(集合)
-
采集帮助 - 使用采集
使用采集: 普通文章采集 图片集采集
-
采集帮助 - 了解采集
了解采集: 关于采集 采集流程 界面和功能介绍 采集管理菜单介绍 采集节点管理介绍 临时内容管理介绍 导入采集规则介绍 监控采集模式介绍 导出所有内容介绍 采集未下载内容介绍 常用过滤规则 HTML过滤 常用正则表达式
-
集群部署 - 升级集群
主版本和次版本升级 Seafile 在主版本和次版本中添加了新功能。有可能需要修改一些数据库表,或者需要更新搜素索引。一般来说升级集群包含以下步骤: 更新数据库 更新前端和后端节点上的符号链接以指向最新版本。 更新每个几点上的配置文件。 更新后端节点上的搜索索引。 一般来说,升级集群,您需要: 在一个前端节点上运行升级脚本(例如:./upgrade/upgrade_4_0_4_1.sh) 在其他所
-
集群部署 - MariaDB/Memcached集群
按照Seafile 集群文档中给出的推荐架构,Seafile 集群需要使用一个分布式、高可用的数据库和缓存集群。在本文档中,我们给出一个在 3 台服务器上部署 MariaDB 和 Memcached 集群的案例。 硬件和操作系统需求 最少使用3台服务器部署来集群,每台机器都应该有: 2核、4GB内存。 1个SATA磁盘用来存储操作系统。 1个SATA磁盘用来存储MariaDB数据。也可以把 Mar
-
Java读取200万行文本文件的最快方法
问题内容: 目前,我正在使用扫描仪/文件阅读器,同时使用hasnextline。我认为这种方法效率不高。还有其他方法可以读取与此功能类似的文件吗? 问题答案: 您会发现这是所需的速度:您可以每秒读取数百万行。字符串拆分和处理很可能导致遇到的任何性能问题。
-
 阿里云盘万能邀请码注册获取教程
阿里云盘万能邀请码注册获取教程本文向大家介绍阿里云盘万能邀请码注册获取教程,包括了阿里云盘万能邀请码注册获取教程的使用技巧和注意事项,需要的朋友参考一下 阿里云网盘注册邀请码怎么注册登陆?为了让更多的小伙伴也体验体验,之前也特分享了一批阿里云盘邀请码送给大家,下面为大家分享一下获取阿里云盘邀请码注册登录网盘的方法。 软件介绍 根据阿里云盘官网介绍,其组建了一支由智能算法、智能存储、新型网络、AloT、 网络安全等领域科学家、工
-
MySQL快速从60万行中选择10条随机行
问题内容: 如何最好地编写一个查询,从总共60万行中随机选择10行? 问题答案: 一个出色的职位,可以处理多种情况,从简单到有缺口,再到有缺口的不均匀。 http://jan.kneschke.de/projects/mysql/order-by- rand/ 对于大多数一般情况,这是您的操作方法: 这假定id的分布是相等的,并且id列表中可能存在间隙。请参阅文章以获取更多高级示例
-
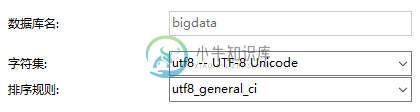 Mysql快速插入千万条数据的实战教程
Mysql快速插入千万条数据的实战教程本文向大家介绍Mysql快速插入千万条数据的实战教程,包括了Mysql快速插入千万条数据的实战教程的使用技巧和注意事项,需要的朋友参考一下 一.创建数据库 二.创建表 1.创建 dept表 2.创建emp表 三.设置参数 SHOW VARIABLES LIKE 'log_bin_trust_function_creators'; 默认关闭. 需要设置为1。因为表中设置 mediumint 字段
-
封装好的一个万能检测表单的方法
本文向大家介绍封装好的一个万能检测表单的方法,包括了封装好的一个万能检测表单的方法的使用技巧和注意事项,需要的朋友参考一下 检测表单中的不能为空(.notnull)的验证 作用:一对form标签下有多个(包括一个)表单需要提交时,使用js准确的判断当前按钮对那些元素做判断 用法:在form标签下 找到当前 表单的容器 给予class="form",当前表单的提交按钮给予 class="chec
-
MySQL从60万行中快速选择10条随机行
问题内容: 如何最好地编写一个查询,从总共60万行中随机选择10行? 问题答案: 一个出色的职位,处理从简单到有缺口,再到有缺口不均匀的几种情况。 http://jan.kneschke.de/projects/mysql/order-by- rand/ 对于大多数一般情况,这是您的操作方法: 这假定id的分布是相等的,并且id列表中可能存在间隙。请参阅文章以获取更多高级示例
-
在Python中合并具有数百万行的两个表
问题内容: 我正在使用Python进行一些数据分析。我有两个表,第一个(叫它“ A”)有1000万行和10列,第二个(“ B”)有7300万行和2列。他们有1个具有共同ID的列,我想根据该列将两个表相交。特别是我想要表的内部联接。 我无法将表B作为pandas数据框加载到内存中,以在pandas上使用常规合并功能。我尝试通过读取表B上的文件的块,将每个块与A相交,并将这些交集连接起来(内部联接的输
-
在java中使用lmax Disruptor(3.0)处理数百万文档
我有以下用例: 当我的服务启动时,它可能需要在尽可能短的时间内处理数百万个文档。将有三个数据来源。 我已设置以下内容: 我的每个源调用consume都使用Guice来创建一个单例破坏者。 我的eventHandler例程是 我在日志中看到,制作人(