《海康威视面试》专题
-
如何添加标题到海运箱图
看起来很好用,但还没能在网上找到有用的东西。 我已经尝试了两个和
-
处理海量数据的Spring批处理
我的数据库中有大约1000万个blob格式的文件,我需要转换并以pdf格式保存它们。每个文件大小约为0.5-10mb,组合文件大小约为20 TB。我正在尝试使用spring批处理实现该功能。然而,我的问题是,当我运行批处理时,服务器内存是否可以容纳那么多的数据?我正在尝试使用基于块的处理和线程池任务执行器。请建议运行作业的最佳方法是否可以在更短的时间内处理如此多的数据
-
熊猫:具有重复索引的海螺
我试图做为。具有和其他在中具有。这是我的代码: 我得到这个错误: 什么,我哪里做错了?
-
 在数字海洋Ubuntu上设置Laravel 5.1
在数字海洋Ubuntu上设置Laravel 5.1我遵循这个指南,在Ubuntu(LAMP stack)上为Digital Ocean设置Laravel 5.1。当我尝试通过单击鼠标访问我的Laravel应用程序时,我得到: 我先安装Composer,然后安装Laravel,然后安装目录在我的路径中“这样您的系统就可以找到laravel可执行文件。” : 然后按照这个指南改变我的webroot,这样我就可以像Laravel期望的那样从提供服务:
-
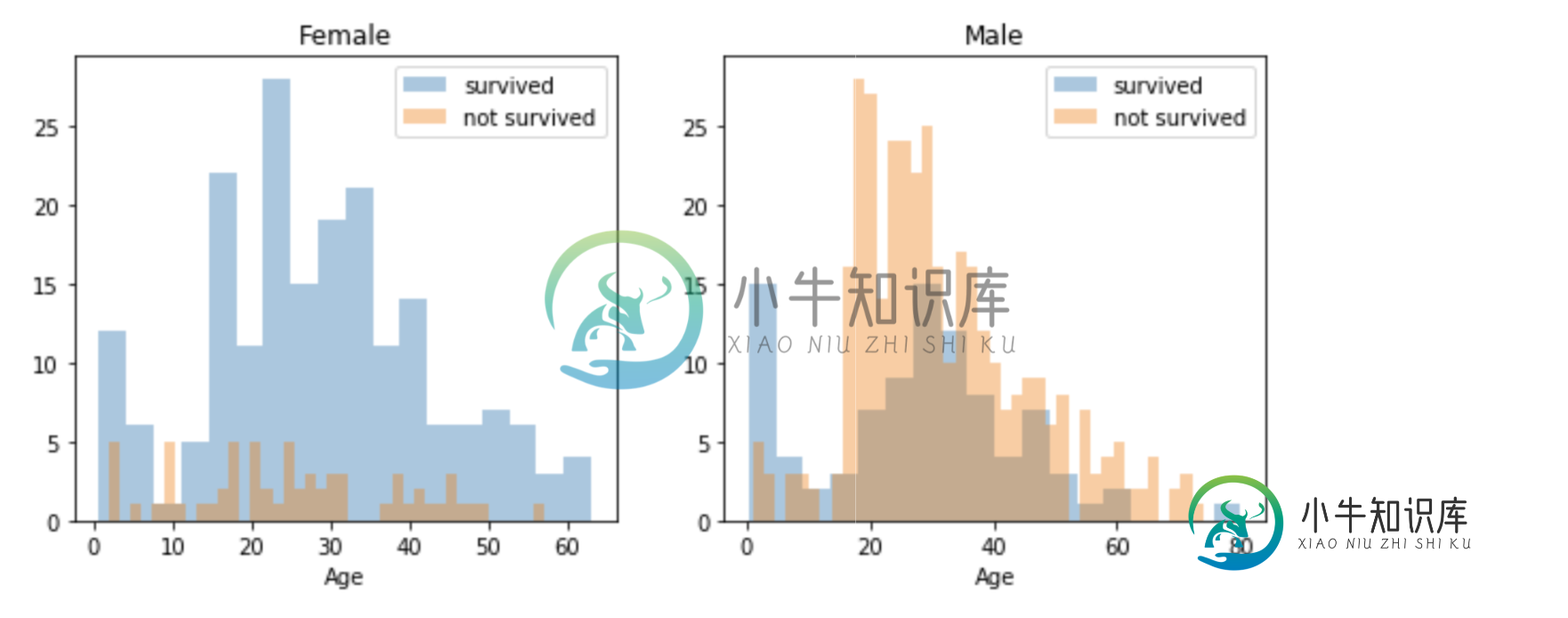 海运扩展图的论点是什么?
海运扩展图的论点是什么?我正在使用泰坦尼克号数据集。为了可视化数据分布,我使用seaborn绘图方法。但我无法理解的参数及其最终输出。我想知道下面几行中使用的参数(参数)的用法,特别是和和的用法。 我已经在留档中搜索了并上网,但没有写清楚。
-
第六章 海量数据处理 - 6.7 Bitmap
方法介绍 什么是Bit-map 所谓的Bit-map就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。 来看一个具体的例子,假设我们要对0-7内的5个元素(4,7,2,5,3)排序(这里假设这些元素没有重复)。那么我们就可以采用Bit-map的方法来达到排序的目的。要表示8个数,我们就只需要8个Bit(1By
-
第六章 海量数据处理 - 6.5 MapReduce
方法介绍 MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE)。这样做的好处是可以在任务被分解后,可以通过大量机器进行并行计算,减少整个操作的时间。但如果你要我再通俗点介绍,那么,说白了,Mapreduce的原理就是一个归并排序。 适用范围:数据量大,但是数据种类小可以放入内存 基本原理及要点:将数据交给不同的机器去处理
-
0字节存储海量语料资源
关键词提取 互联网资源无穷无尽,如何获取到我们所需的那部分语料库呢?这需要我们给出特定的关键词,而基于问句的关键词提取上一节已经做了介绍,利用pynlpir库可以非常方便地实现关键词提取,比如: # coding:utf-8 import sys reload(sys) sys.setdefaultencoding( "utf-8" ) import pynlpir pynlpir.open()
-
 上海初创公司 Java实习 已offer
上海初创公司 Java实习 已offer首先我觉得我能找到一份实习,就很开心了,现在太难了。 一面: 1. 项目:简单介绍一下你的项目。 2. 项目:说一下消息队列MQ,项目的什么场景下用到了MQ,为什么需要MQ 3. Java:聊一聊Java可以用哪些方式保证线程安全 4. 算法:数据流的中位数 5. 算法: 描述: 给出一个目录结构(多叉树),每个子目录都有指向父目录的指针,但父目录没有指向子目录的指针。 问题:给定任意两个子目录,
-
 作业帮海外用研运营凉经
作业帮海外用研运营凉经时间:25分钟 1.自我介绍 2.简历深挖 1)细问问卷调查项目经历(包括项目周期为什么这么长?问卷停留时长改善的原因是什么?项目回收数据不错,怎么做到的?有没有具体的激励等等) 2)如何触达海外用户进行调研和访谈 这个问题回答得比较差,简单回答了针对用户画像,寻找用户痛点,针对未解决的问题进行定性与定量研究之类,但总感觉不是面试官想要的,不知道如何把这个宽泛的问题回答得细致。 3)职业规划是什么
-
 前端 - uniapp app端实现海报功能?
前端 - uniapp app端实现海报功能?uniapp项目app端实现下载海报 现在的代码如下: html js 原先是下载二维码,现在换成下载海报,海报里显示@/static/img/codeImg.jpg,school_name、classes_name跟一个背景色background: #f3af1e,还有二维码codeImg,下载的海报图样式跟下面的图片一样,关闭跟下载按钮不要,其他都要 大佬们,修改上面的代码如何实现下载海报功能
-
 上海松鼠云上人工智能技术有限公司(米学) Go开发面经
上海松鼠云上人工智能技术有限公司(米学) Go开发面经电话面,26min,八股文大杂烩。 GMP,有锁吗? channel底层,啥时候阻塞 map安全吗,有序吗,哪些能当key sync.Map读取逻辑 你自己设计map会怎么设计? 索引大杂烩 幻读,解决方案 联合索引,索引下推 回表 Redis数据结构,应用场景 消息队列怎么实现,分布式锁怎么实现,限流怎么实现 持久化,会阻塞吗 为什么是三次握手?TIME_WAIT状态意义? 四次挥手可不可以是三
-
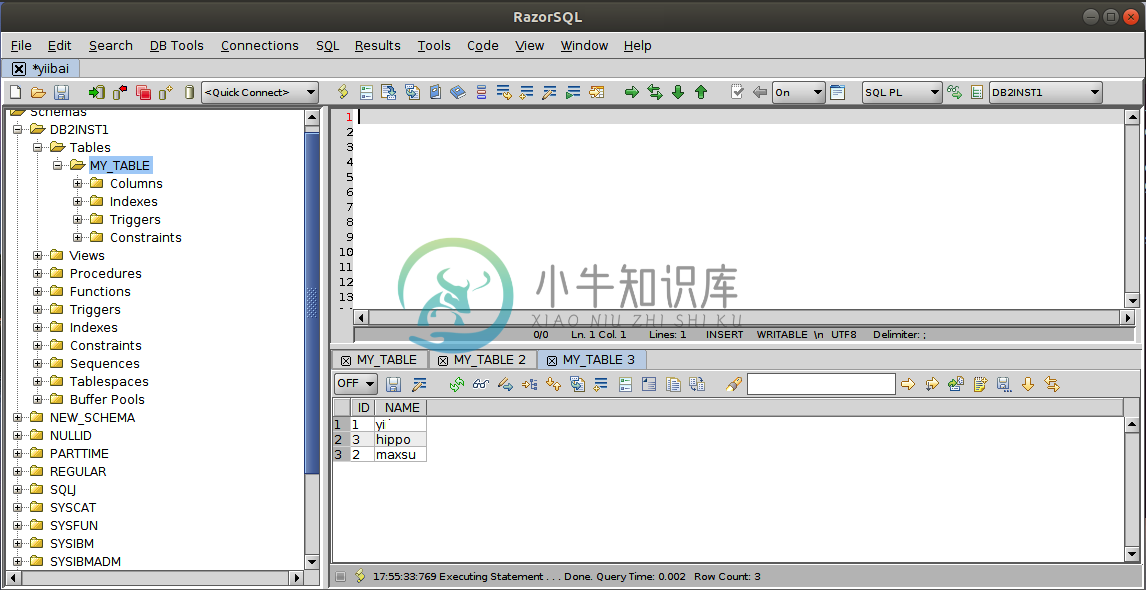 DB2 RazorSQL视图
DB2 RazorSQL视图主要内容:查看表内容视图用于定义表示存储在表中的数据的替代方法。视图不是真正的表,也没有任何永久存储。 它可以用于查看一个或多个表中的数据。它是结果表的命名规范。 视图可以从一个或多个表派生。最多可以使用15个表来创建视图。视图可以包含表中的所有列或某些列。 查看表内容 查看内容(View Content )块有助于查看存储在表中的所有记录。
-
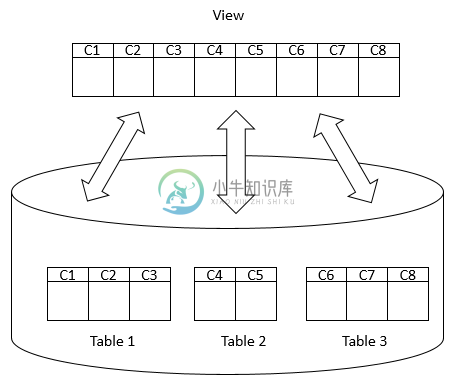 SQL Server视图
SQL Server视图在本教程中,将了解视图以及如何管理视图,包括:创建新视图,删除视图以及通过视图更新基础表的数据。 使用SELECT语句查询一个或多个表中的数据时,将获得结果集。 例如,以下语句返回 和 表中所有产品的产品名称,品牌和价格: 下次,如果要获得相同的结果集,可以将此查询语句保存到文本文件中,打开它,然后再次执行。 SQL Server提供了一种通过视图将此查询保存在数据库目录中的更好方法。 视图是存储
-
 JSF Facelets视图
JSF Facelets视图主要内容:映射Faces ServletFacelets视图是页面。 您可以通过向页面添加组件来创建网页或视图,将组件连接到后端的值和属性,并在组件上注册转换器,验证器或侦听器。 网页作为前端。 您的应用程序的第一页默认为。 网页(如,在中)的第一部分声明页面的内容类型,即XHTML: 一个完整的文件:index.xhtml 代码内容如下所示 - Facelets HTML标签以开头,用于在网页和核心标签上添加组件用于验证用户输入。 标