
海运扩展图的论点是什么?

我正在使用泰坦尼克号数据集。为了可视化数据分布,我使用seaborn绘图方法。但我无法理解distplot的参数及其最终输出。我想知道下面几行中使用的参数(参数)的用法,特别是bin和轴[0]和kde=False的用法。
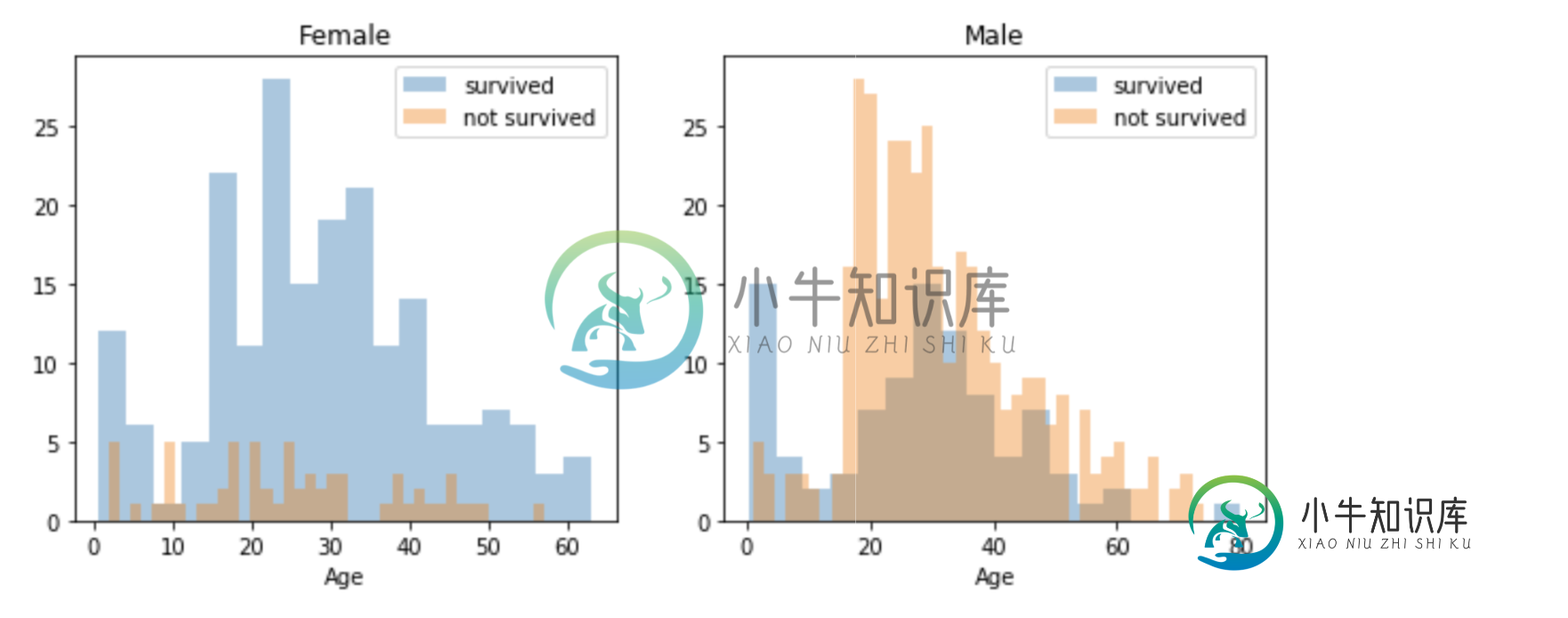
ax = sns.distplot(women[women['Survived']==1].Age.dropna(), bins=18,
label = survived, ax = axes[0], kde =False)
ax = sns.distplot(women[women['Survived']==0].Age.dropna(), bins=40,
label = not_survived, ax = axes[0], kde =False)
我已经在留档中搜索了扩容并上网,但没有写清楚。
共有2个答案

首先,我们试着了解一下什么是膨胀图?DITPLNE是seborn python库的一个函数。它是这样表示的:sns.seaborn()。
它用于绘制海运直方图。
现在,在你的脑海中可能会有疑问,为什么我会绘制直方图。直方图有助于可视化条形图中的数字类型数据集。
在y轴上给出数字数据集,因为你已经给出了"女性['幸存']==1"和[女性['幸存']==0]
在x轴上给出了垃圾箱。这意味着在特定范围内分布给定的数据集,并在条形图中显示,如您给定的bins=18和bins=40在此处输入图像描述
现在,我展示seabornsns的语法。distplot()
Syntax: sns.distplot(
a,
bins=None,
hist=True,
kde=True,
rug=False,
fit=None,
hist_kws=None,
kde_kws=None,
rug_kws=None,
fit_kws=None,
color=None,
vertical=False,
norm_hist=False,
axlabel=None,
label=None,
ax=None,
)
使用上述参数,您可以很好地绘制直方图。按照本教程,使用sns绘制seaborn直方图。距离图

- 轴[0]
根据您的代码,我假设轴应该是轴对象的列表,轴[0]表示您访问列表中的第一个对象。使用ax=axes[0]表示希望绘图位于左侧。请看这篇有用的文章。
默认情况下,seborn绘制内核密度估计和直方图,kde=False意味着您想要隐藏它,并且只显示直方图。
从统计学上讲,直方图是一种非参数估计,它的形状反映了数据的分布。箱子的数量会影响形状。因此,如果希望绘图表示数据分布,则不应只是随机选取一个仓位编号。决定适当数量的箱子最常用的方法是使用Freedman–Diaconis规则,这也是中的默认设置。distplot()。换句话说,当您使用时。distplot()函数要显示数据分布,最好不要指定bin参数。
-
扩展是可定制化浏览体验的小程序,它们使用户可以根据个人需要或者偏好定制 Chrome 的功能和行为。它们基于 Web 技术(例如 HTML,JavaScript 和 CSS)构建。 扩展必须满足狭义定义且易于理解的单一目的(译者注:功能简单易懂化)。一个扩展可以包括多个组件和一系列功能,只要所有的内容都有助于实现共同的目标。 用户交互界面应尽量小且有意图。他们的范围从简单的图标,如右侧显示的 Go
-
问题内容: 我试图找出扩展Thread类的可能的优点是什么? 这是我描述的另一个问题的一部分:在Java中有两种创建线程的方法 从Thread类扩展 实现可运行的接口 如此处所述,使用可运行接口有许多好处。我的问题是从Thread类扩展的优点是什么?我想到的唯一好处是可以从Thread类扩展,并且可以称其为ThreadExtended类。然后,他/她可以在ThreadExtended中添加更多功能
-
我试图找出扩展Thread类的可能优势是什么? null
-
扩展说明 扩展点本身的加载容器,可从不同容器加载扩展点。 扩展接口 org.apache.dubbo.common.extension.ExtensionFactory 扩展配置 <dubbo:application compiler="jdk" /> 已知扩展 org.apache.dubbo.common.extension.factory.SpiExtensionFactory org.a
-
与业界大多Java服务的扩展机制是一样的,Dorado使用JDK内置的服务提供发现机制。但Dorado在获取扩展点实现上进行了一些改造,比如可以按照名字或者角色(调用端或服务端)获取扩展点实现。所有的SPI接口通过@SPI注解来识别,使用者实现SPI接口并按照Java SPI规范配置即可使用。 Dorado目前提供了以下的SPI扩展点 : 标注不支持多个实现的扩展点要注意,使用中只能选择一种实现
-
说明 本部分说明如何在现有的机器中添加一个新的计算节点。添加节点之前,OpenShift 共有四个节点,1 个 master,1 个 infra,2 个 nodes,如下命令所示: # oc get nodes NAME STATUS ROLES AGE VERSION infra.example.com Ready infr