《万朋数智》专题
-
动态数据库查询可获取超过 100 万的数据 - Java 中的示例
我正在尝试运行一个查询并获取所有项目。似乎没有检索到所有项目,我需要使用start键再次运行查询。 从文件中 对于Query或Scan操作,如果操作没有返回表中所有匹配的项目,DynamoDB可能会返回LastEvalatedKey值。要获取匹配项的完整计数,请从上一个请求中获取LastEvalatedKey值,并在下一个请求中将其用作ExunisiveStartKey值。重复此操作,直到Dyna
-
在Python 3中加速数百万个正则表达式的替换
问题内容: 我正在使用Python 3.5.2 我有两个清单 大约750,000个“句子”(长字符串)的列表 我想从我的750,000个句子中删除的大约20,000个“单词”的列表 因此,我必须遍历750,000个句子并执行大约20,000个替换,但前提是我的单词实际上是“单词”,并且不属于较大的字符串。 我这样做是通过预编译我的单词,使它们位于\b元字符的两侧 然后我遍历我的“句子” 这个嵌套循
-
C#百万数据查询出现超时问题的解决方法
本文向大家介绍C#百万数据查询出现超时问题的解决方法,包括了C#百万数据查询出现超时问题的解决方法的使用技巧和注意事项,需要的朋友参考一下 本文较为详细的讲解了C#百万数据查询出现超时问题的解决方法,分享给大家供大家参考之用。具体方法如下: 很多时候我们用C#从百万数据中筛选一些信息时,经常会出现程序连接超时的错误,常见的错误有很多,例如: Timeout expired. The timeout
-
Spring Boot-通过JPQL UPDATE查询批量更新数十万个对象?
我正在使用具有HiberNate的Spring Boot1.5.2。 我有一个对象列表。每个对象都包含许多属性和@OneTo许多关系(即从数据库中获取此对象并将此对象更新到数据库需要很长时间)。 这就是我使用自定义 JPQL 查询的原因: 一个用于加载对象列表的基本属性 一个用于更新对象所需的属性 我从CrudRepository扩展了这个方法,用于获取对象列表(只有所需的属性) 现在,我想通过以
-
以很小的内存占用执行数百万个可运行的
我有N个愿望是ID。对于每一个ID,我都需要执行一个Runnable(即,我不关心返回值),并等待它们全部完成。每个Runnable的运行时间从几秒到几分钟不等,并行运行大约100个线程是安全的。 在我们当前的解决方案中,我们使用Executors.NewFixedThreadPool(),对每个ID调用submit(),然后对每个返回的Future调用get()。 代码工作得很好,而且非常简单,
-
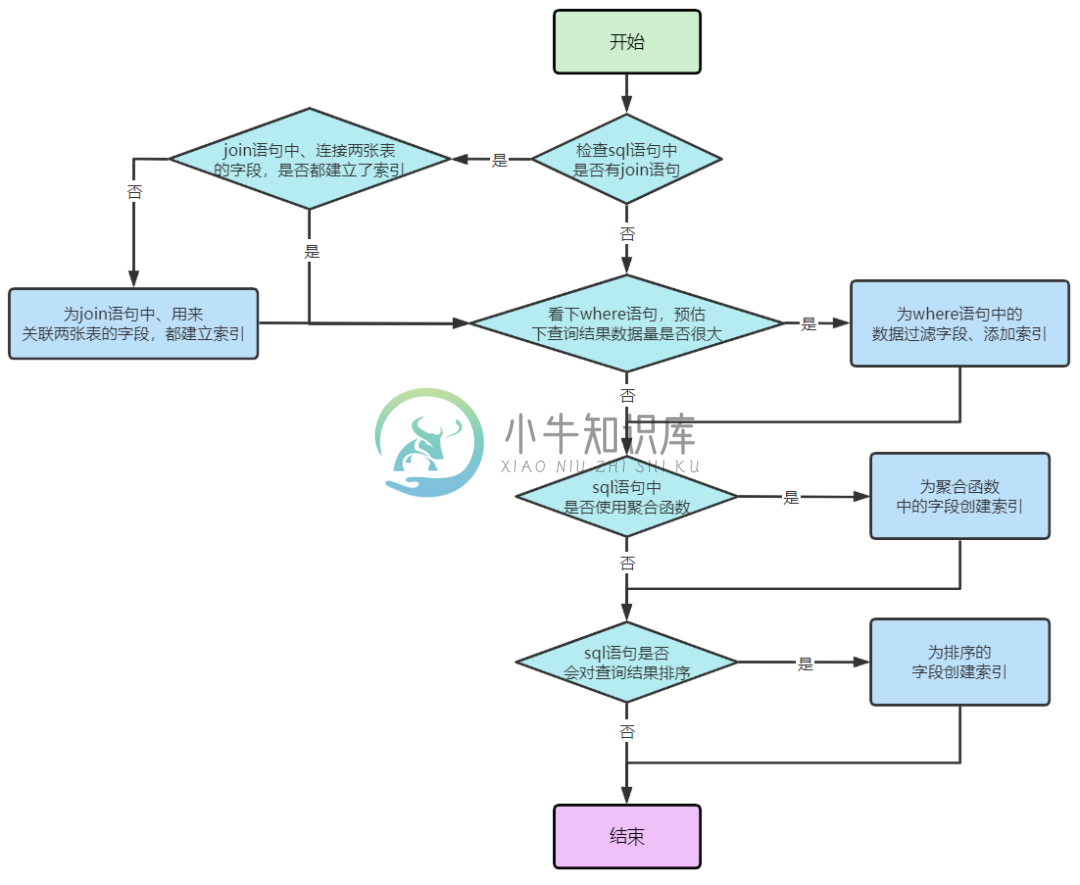 千万数据量下的真实业务场景SQL性能优化!
千万数据量下的真实业务场景SQL性能优化!主要内容:前 言,Simple nested loop算法,Block nested loop 算法,Index nested loop算法,到底能不能使用join?,join关联查询优化实战,优化:被驱动表order_no列添加索引,进一步优化:去掉join,被动向主动的转变,监控系统诞生前 言 通过前几期文章的积累,现在我们的理论知识已经极为扎实了,这个时候就可以动手开始sql优化了,sql优化是非常重要,因为即使再好的MySQL设计架构,也扛不住一个频繁查询的垃圾sql语句。 关于sql的
-
MySQL在600万行表上的性能
问题内容: 有一天,我怀疑我将不得不学习hadoop并将所有这些数据传输到非结构化数据库中,但是我感到惊讶的是,在如此短的时间内,性能如此显着下降。 我有一个只有不到600万行的mysql表。我正在对该表进行非常简单的查询,并相信我已经安装了所有正确的索引。 查询是 解释返回 因此,据我所知,我使用的索引正确,但是此查询需要11秒钟才能运行。 数据库是MyISAM,而phpMyAdmin表示该表是
-
 3.6 上海 万得 java 一面凉经
3.6 上海 万得 java 一面凉经上周五约的面, 本来准备好好准备两天的, 结果急性肠胃炎(maybe), 躺了两天. 面之前10min还去拉了一趟. 用的他们家的会议软件, 在图书馆角落面的, 结果有个社牛跑过来跟我坐一起, tnnd 总结: 全场常规八股, 互动不多 耗时: 25min 正文 自我介绍: (2min) 24届, 是学生 java基础: (9min) ++i和i++ java三个特性: 我一开始想的(面向对象 跨
-
 万集前端一面hr面(hr挂)
万集前端一面hr面(hr挂)1.移动端适配的方法,rem的具体实现方法 2.js的基本数据类型 3.undefined的具体场景 4.js单线程(事件循环) 5.跨域 6.es6的方法 7.箭头函数的区别 8.var、let和const的区别 9.http协议的请求方式 10.生命周期 11.keep-alive实现 12.css垂直居中 hr面没有谈薪环节呀!我hr面完之后流程终止#万集科技#
-
 万得 Java开发 11.9 一面 二面
万得 Java开发 11.9 一面 二面11.9 一面(25min): 1.自我介绍 2.怎么看待加班、团队合作 3.问设计模式了解多少,我说单例模式(饿汉、懒汉、双重校验+锁) 4.枚举实现单例模式 5.问看过什么书 6.MySQL索引底层 7.MySQL事务实现原理 8.事务隔离级别 9.模糊查询索引失效的情况 10.SQL优化 11.用什么分析具体的SQL语句、type字段表示什么 12.创建线程的方式 13.Runnable和C
-
 万集 测试 一面 面经 已凉
万集 测试 一面 面经 已凉9.2 牛客投递 北京 测试 hr加微信约面 9.5 10:00 25分钟 面试官是一个小姐姐 语音聊天 1.自我介绍 2.着重了解项目,问俺的毕业论文。是使用C和Python,介绍项目原理,设计架构,代码行数。 3.有无使用py库。 4.C与Python调用。 5.static关键字。 6.shell脚本,有无应用。 7.linux常见指令。 8.TCP/IP模型,各层协议。TCP IP ARP
-
OracleSQL从十万行中选择1000行
我有一个大约15万行的表,我必须使用JavaQuartz Scheduler一次获取1000行。要求是一次限制1000行,然后再限制1000行等(与MySQL限制查询相同)。 我正在使用以下查询: 问题是上面的查询返回了我在结果集中不需要的额外列rownum,因为返回的数据被传递给MapListHandler(),后者返回将结果转换为JSON,并且我将此JSON传递给不期望额外rownum列的We
-
 2023Wind万得信息测试岗一面
2023Wind万得信息测试岗一面1. 自我介绍 2. Linux常用命令:调节权限,文件解压。你经常用什么linux系统,如何更改ip地址 3. sql:主键有哪些约束 4. 对加班怎么看,995 5. 职业规划是什么 6. influxdb和grafana的关系 7. 了解哪些测试方法。你这里Junit,gitlab是特定的测试,没有看出系统级的方法 8. 为什么投测试岗,如果需要你干开发呢,未来的职业打算是什么样的,在金融公
-
 4.17蚂蚁一面 4.18万得一面
4.17蚂蚁一面 4.18万得一面#4.17 蚂蚁一面 电话面试,全程八股,难度不大 线性数据结构有哪些,分别什么适用什么情况。 约瑟夫环问题。 二叉树的遍历方式。 数据在网络中传输的过程。(中间穿插问了TCP和UDP的区别) 面向对象的特性。 然后还有一两个问题,忘了。。。 结束之后面试官直接告诉我说让我过了。 听说蚂蚁会比较难,不知道为什么我遇到的这个面试官问的还挺简单的 #4.18 万得一面 boss上聊的某中厂,前面没有笔
-
 万物心选前端4-11面试
万物心选前端4-11面试先自我介绍,然后问学了多久前端,为什么选择前端,介绍下自己的项目。 css 要使用多种方式实现,在飞书文档里面写 1.写css div多个div在一行显示 2.flex对齐 3.写一个和手机宽度一样的正方形布局,左右边距50px 4.选中前三个加样式 5.写一个防抖函数 6.写一个函数去获取url指定的参数值 7.把第上一个函数优化下实现一个复用的效果 8.tcp udp 9.三次握手 10.问最