《万朋数智》专题
-
 13.万声音乐 (GO实习生)
13.万声音乐 (GO实习生)一面 15min 自我介绍 数组、链表、栈、队列数据结构及应用场景 排序算法知道哪些,快排 二面 20min Go语言基础,defer关键字 三次握手四次挥手 TLS协议(不会) Redis常用命令及其时间复杂度(Redis命令时间复杂度,第一次被问到) 数据库的索引 二面是项目组长,很厉害,随便问几个问题就招架不住了
-
 万得java后端一面面经
万得java后端一面面经中午一点面试😡困死我了😡 项目相关的问题 Java集合 线程池的创建方式 了解jvm、gc垃圾回收吗(不了解) 说说自己了解的设计模式 实习相关 因为是在公司找了个会议室,只能手机面试,所以没有手撕环节 反问环节 总体上很轻松,也很简单,希望能过 离谱 刚问了一下hr笔试是两轮技术面面完才发,而且笔试成绩占比很大
-
 2025 万得 java开发 提前批
2025 万得 java开发 提前批7.4 投递 万得是一二面一块进行,通过了后面才发笔试 7.7 一面 15 min 项目难点、最大的亮点;合作情况 项目中算法具体介绍,测试数据 消息队列的异步具体实现 操作系统中的读写者问题 归并排序(稳定or不稳定) b 树底层结构 相关论文发表情况 本来是九点半一面,十点二面,面试官临时有事约到下午去了 7.7 二面 15 min 操作系统相关: 操作系统里进程和线程的区别 进程之间的通信方
-
 Vue.js实现模拟微信朋友圈开发demo
Vue.js实现模拟微信朋友圈开发demo本文向大家介绍Vue.js实现模拟微信朋友圈开发demo,包括了Vue.js实现模拟微信朋友圈开发demo的使用技巧和注意事项,需要的朋友参考一下 我用Vue.js实现微信朋友圈的一些功能,实现展示朋友圈,评论,点赞。 先构造一个vue的实例,对会更改的数据进行双向绑定, 我用JSON伪造模版数据,先实现显示朋友圈的效果,使用v-for方法去循环ALLFeeds中的每一项item生成包括name、
-
android7.0实现分享图片到朋友圈功能
本文向大家介绍android7.0实现分享图片到朋友圈功能,包括了android7.0实现分享图片到朋友圈功能的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了android实现分享图片到朋友圈功能的具体代码,供大家参考,具体内容如下 在Android7.0中,系统对scheme为file://的uri进行了限制,所以通过这种uri来进行分享的一些接口就不能用了,比如使用代码来调用分享
-
android实现多图文分享朋友圈功能
本文向大家介绍android实现多图文分享朋友圈功能,包括了android实现多图文分享朋友圈功能的使用技巧和注意事项,需要的朋友参考一下 很多安卓程序员都在寻找如何调用系统分享可以实现朋友圈多图加文字分享的功能,小编经过测试入坑后,为你整理以下内容: 其中最关键的就是: 文字部分一直分享失败,搞了很久都分享失败后来才发现是需要加上这一句了·····坑! 原来Kdescription是微信描述信息
-
 利用python如何处理百万条数据(适用java新手)
利用python如何处理百万条数据(适用java新手)本文向大家介绍利用python如何处理百万条数据(适用java新手),包括了利用python如何处理百万条数据(适用java新手)的使用技巧和注意事项,需要的朋友参考一下 1、前言 因为负责基础服务,经常需要处理一些数据,但是大多时候采用awk以及java程序即可,但是这次突然有百万级数据需要处理,通过awk无法进行匹配,然后我又采用java来处理,文件一分为8同时开启8个线程并发处理,但是依然处
-
SQL对数百万行重复删除查询以提高性能
问题内容: 这是一次冒险。我从上一个问题中的循环重复查询开始,但是每个循环将遍历所有 1700万条记录 , 这意味着将花费数周的时间 (使用MSSQL 2005,运行服务器需要4:30分钟)。我从这个站点和这个帖子中闪现了信息。 并已经到达下面的查询。问题是,对于任何类型的性能,这是否是对1700万条记录运行的正确查询类型?如果不是,那是什么? SQL查询: 问题答案: 看到QueryPlan会有
-
创建数百万个小型临时对象的最佳实践
创建(和发布)数百万个小对象的“最佳实践”是什么? 我正在用Java编写一个国际象棋程序,搜索算法为每一个可能的移动生成一个“移动”对象,一次标称搜索每秒可以轻松生成超过一百万个移动对象。JVM GC已经能够处理我的开发系统上的负载,但我有兴趣探索以下替代方法: 最小化垃圾收集的开销,以及 降低低端系统的峰值内存占用 绝大多数对象的寿命都很短,但生成的移动中约有1%是持久化的,并作为持久化值返回,
-
如何优化大多数出现的值(亿万行)的检索
问题内容: 我正在尝试从包含数亿行的SQLite表中检索一些最常出现的值。 到目前为止,查询可能如下所示: 该字段上有一个索引。 但是,使用ORDER BY子句,查询会花费很多时间,我从未见过它的结尾。 可以采取什么措施来大幅度改善对如此大量数据的此类查询? 我试图添加一个HAVING子句(例如:HAVING count> 100000)以减少要排序的行数,但是没有成功。 请注意,我不太在意插入所
-
如何用apache spark处理数百万个较小的s3文件
注意:计数是对处理文件需要多长时间的更多调试。这项工作几乎花了一整天的时间,超过10个实例,但仍然失败,错误发布在列表的底部。然后我找到了这个链接,它基本上说这不是最佳的:https://forums.databricks.com/questions/480/how-do-i-ingest-a-large-number-of-files-from-s3-my.html 然后,我决定尝试另一个我目前
-
mysql - MYSQL 统计二十九万条数据要13.96秒正常吗?
二十九万条数据要13秒多,是不是有点久?这个语句也没办法优化了吧?
-
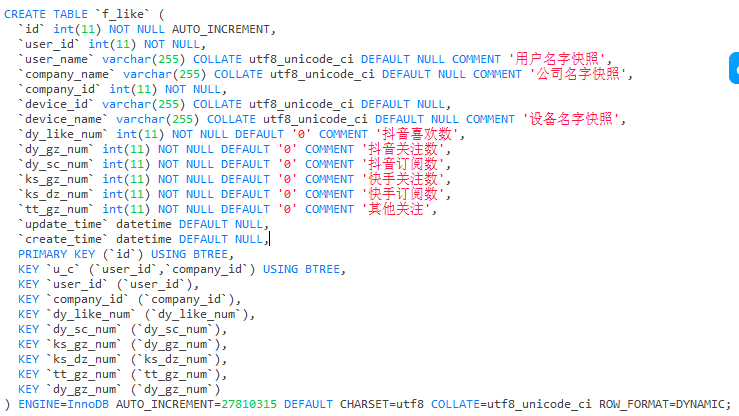 mysql sum多个字段千万级数据如何查询优化?
mysql sum多个字段千万级数据如何查询优化?统计数据表中多个sum千万级数据超时。由于业务需要实时 所以做不来快照表 我加了索引似乎也不管用 后来为了不联表 我直接把快照写入进去了
-
前端表格展示十万级数量的数据,有没有好的方案?
前端表格展示十万级数量的数据,有没有好的方案 就现有的UI库组件,页面会很卡
-
上千万或上亿的数据,统计其出现次数最多的前N个数据?
本文向大家介绍上千万或上亿的数据,统计其出现次数最多的前N个数据?相关面试题,主要包含被问及上千万或上亿的数据,统计其出现次数最多的前N个数据?时的应答技巧和注意事项,需要的朋友参考一下 做法相同,先hash到小文件,然后hashmap计数比较