《花旗银行》专题
-
如何运行火花壳与纱在客户模式?
我已经在一个15节点的Hadoop集群上安装了。所有节点都运行和最新版本的Hadoop。Hadoop集群本身是功能性的,例如,YARN可以成功地运行各种MapReduce作业。 我可以使用以下命令在节点上本地运行Spark Shell,而不会出现任何问题:。 你知道为什么我不能用客户端模式在纱线上运行Spark Shell吗?
-
在单独的机器上运行火花驱动器
目前,我正在群集模式(独立群集)下使用Spark 2.0.0,群集配置如下: 工作线程:使用了4个内核:总共32个,使用了32个内存:总共54.7 GB,使用了42.0 GB 我有4个奴隶(工人)和1台主机。火花盘有三个主要部件-主部件、驱动部件、工作部件(参考) 现在我的问题是,驱动程序正在其中一个工作节点中启动,这阻碍了我在其全部容量(RAM方面)中使用工作节点。例如,如果我在运行spark作
-
RDD火花。违约Spark数据帧的并行等效
Narrow转换(映射、过滤器等)的SparkSQL数据帧是否有“spark.default.parallelism”等价物? 显然,RDD和DataFrame之间的分区控制是不同的。数据帧具有spark。sql。洗牌用于控制分区的分区(如果我理解正确的话,则为宽转换)和“spark.default.parallelism”将没有效果。 Spark数据帧洗牌如何影响分区 但洗牌与分区有什么关系呢?
-
执行器核心数和利益或其他-火花
需要进行一些运行时澄清。 在我读到的其他地方的一个线程中,有人说Spark Executor应该只分配一个核心。然而,我想知道这是否真的永远是真的。阅读各种so问题和诸如此类的问题,以及Karau、Wendell等人的著作,可以清楚地看到,有相同或相反的专家指出,在某些情况下,每个执行者应该指定更多的内核,但讨论往往更多的是技术性的,而不是功能性的。也就是说,缺少功能性的例子。 > 我的理解是RD
-
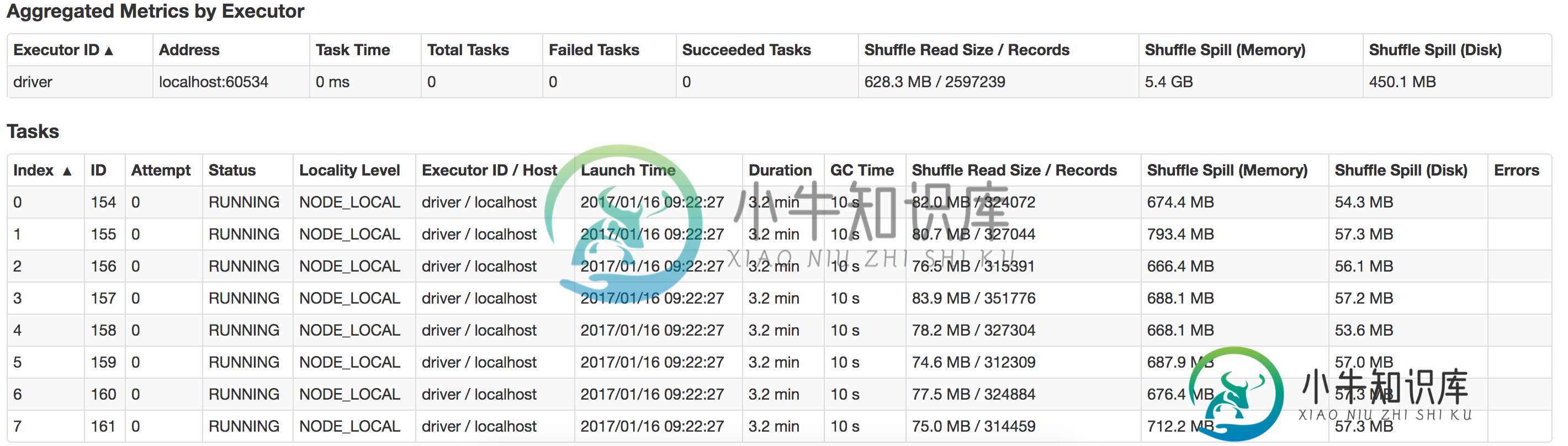 火花驱动程序内存和执行器内存
火花驱动程序内存和执行器内存我是Spark的初学者,我正在运行我的应用程序,从文本文件中读取14KB的数据,执行一些转换和操作(收集、收集AsMap),并将数据保存到数据库 我在我的macbook上本地运行它,内存为16G,有8个逻辑核。 Java最大堆设置为12G。 这是我用来运行应用程序的命令。 bin/spark-submit-class com . myapp . application-master local[*
-
斯卡拉火花 将多个列对分解成行
如何将多个列对分解为多行? 我有一个包含以下内容的数据帧 我想要一个最终的数据帧,如下所示 我试着使用下面的代码,但是它返回了4条记录,而不是我想要的两条记录
-
 2022.09.26 杭州银行总行信息技术部初面
2022.09.26 杭州银行总行信息技术部初面时间貌似不到十分钟,八股文也没有怎么问,仅仅是简单的了解了一下情况 采用腾讯会议的方式,一共两位面试官 自我介绍。 面试官随便挑了一个项目,让简单介绍一下。 看到你两个项目中都使用到了Redis,那么能不能简单的介绍一下Redis,并说一下Redis为什么这么快?(内存存储、单线程、高效的数据结构、IO多路复用技术,第四点我忘了说了) Redis源码读过吗。(原本以为他会问一些Redis源码方面的
-
 杭州银行总行信息科技部门-初面
杭州银行总行信息科技部门-初面乌龙:直接给我发了一个终面邀请? 后面又改成初面 时间:9.26 一、第一个面试官 1、进去两个人,首先开始自我介绍 2、问项目的功能,用的什么语言 3、TCP和UDP的区别 二、第二个面试官(有本地口音,问的问题一个没听清) 4、strcpy和strcnpy区别(后面才反应过来) 5、什么定义 6、什么int 最后,可能觉得我这也不会,就说结束了。 挺不好的一次银行面试经历 应该无了。。。 #杭
-
 中信银行信用卡中心(一/二/hr)面经
中信银行信用卡中心(一/二/hr)面经给想去的友友参考一下吧。 一面 10.20 面试官应该是后端的,对前端了解的不多,基本上就是聊天,没什么深入的问题。 你认为前后端的区别? 用过哪些库(感觉实在没啥聊的哈哈哈哈哈,直接问这些。。) 看我有开源作品,让我拿一个出来说一下 聊了下markdown解析器,实现过程 链表顺序表相关问题(删除插入时间复杂度) 问了下最多的开源项目star有多少(我说400多,面试官觉得很惊讶,小小的夸了一下
-
 宁波银行-永赢金租 一面 后端 10.10 30min
宁波银行-永赢金租 一面 后端 10.10 30min自我介绍 讲解一下自己熟悉的设计模式 讲解一下熟悉的线性表 线性表在Java集合的类的对应 讲解一下线程的六种状态,这个地方疏忽了,名字忘记了,说了一些最显著的区别。 JVM的内存区域,以及各自干什么的 元数据区里面存放的那些东西 递归调用没有返回值,会出现什么错误,为什么会出现这个错误 栈帧里面存放的数据 数据库的左右连接,出了一个题 Spring的常用注解 Springboot的自动装配原理
-
 10月11日 宁波银行・永赢租赁一面
10月11日 宁波银行・永赢租赁一面1.java8新特性 2.本地缓存和分布式缓存的区别 3.sleep和wait的区别 4.@SpringBootApplication注解 5.ArrayList和LinkedList区别 6.volatile、synchronized、lock的区别,哪个效率高 7.linux指令,chmod 555 文件名 8.MySQL中的数据类型 9.char、varchar的最大长度 10.int和In
-
 杭州银行总行信息科技终面面经
杭州银行总行信息科技终面面经(看网上没人写,我感觉已经凉了,就我来写吧) 三个面试官,两个轮流问问题,还有一个估计是HR 问题就是正常你做的项目问题以及一些八股问题,之后还有两三句情况了解,我是问了我的专业(非科班)全程十分钟多点 感觉凉了是因为问的八股不会了#面经##秋招#
-
 农业银行广州研发中心 开发面经
农业银行广州研发中心 开发面经8号下午两点场,每个人都要身份证验证然后发一个编号,会叮嘱你自我介绍不能说名字,然后就是漫长的等待,一个多小时之后轮到进去,有三个面试官开视频轮流问你: 自我介绍; 实习过吗,技术栈是什么; 做过什么项目,说看不到我的信息。。。 第二个面试官: Java的锁的优化; 阻塞队列的实现方式; 挑个项目讲一下,做了多久,做了啥; 第三个面试官: 实现线程的方式和区别; spring boot的自动装配;
-
 邮储银行总行信息技术岗AI面试
邮储银行总行信息技术岗AI面试1.你是如何看待所投递岗位的工作的,你认为你有哪些特质符合该岗位的需求 2.举例说说你如何应用创新性的方法解决问题,产生了好的结果 3.如果你的领导给你布置了一个工作量很大的季度任务,对你来说比较困难,你要如何完成 4.如果你和一位老同事关于一个问题有不一样的看法,老同事说你太年轻不懂,你该如何与他进行沟通 5.你是如何学习专业技能的,通过哪些方式和途径提升自己的专业水平 6.用普通话朗读一段文字
-
 中信银行总行信息科技岗笔面经
中信银行总行信息科技岗笔面经09月25号笔试。两个小时,包括常识题,推理题,数学题,英语单选题等题量比较大。除了这些必做题还有需要选一套选做题,我选的it类,一共50个选择,包含java, python, c++等题量不少。整体时间不够用。 10月25号一面。自我介绍,介绍了一个项目。未来的职业发展规划。问机器学习和深度学习都是了解对吧,随机森林和GBDT的区别,又问了CNN,RNN,transform了解那说一下。对于面向