《理想汽车》专题
-
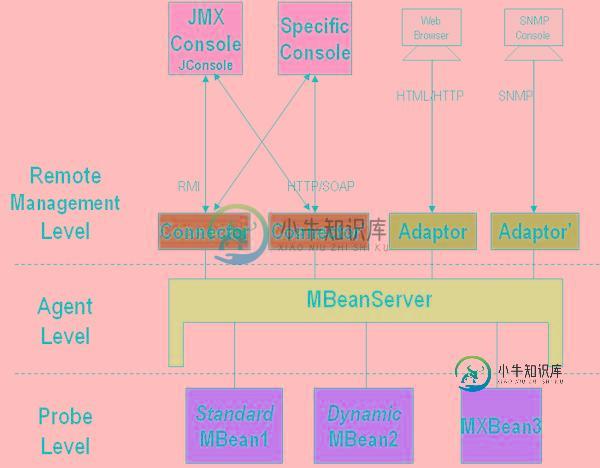 Java Management Extensions管理扩展原理解析
Java Management Extensions管理扩展原理解析本文向大家介绍Java Management Extensions管理扩展原理解析,包括了Java Management Extensions管理扩展原理解析的使用技巧和注意事项,需要的朋友参考一下 所谓JMX,是Java Management Extensions(Java管理扩展)的缩写,是一个为应用程序植入管理功能的框架。用户可以在任何Java应用程序中使用这些代理和服务实现管理。 一、JM
-
 ElasticSearch合理分配索引分片原理
ElasticSearch合理分配索引分片原理本文向大家介绍ElasticSearch合理分配索引分片原理,包括了ElasticSearch合理分配索引分片原理的使用技巧和注意事项,需要的朋友参考一下 Elasticsearch 是一个非常通用的平台,支持各种用户实例,并为组织数据和复制策略提供了极大的灵活性。但是,这种灵活性有时会使我们很难在早期确定如何很好地将数据组织成索引和分片,尤其是不熟悉 Elastic Stack。虽然不一定会在首
-
Mybatis mapper动态代理的原理解析
本文向大家介绍Mybatis mapper动态代理的原理解析,包括了Mybatis mapper动态代理的原理解析的使用技巧和注意事项,需要的朋友参考一下 前言 在开始动态代理的原理讲解以前,我们先看一下集成mybatis以后dao层不使用动态代理以及使用动态代理的两种实现方式,通过对比我们自己实现dao层接口以及mybatis动态代理可以更加直观的展现出mybatis动态代理替我们所做的工作,有
-
上下文管理器和多处理池
问题内容: 假设您正在使用一个对象,并且正在使用构造函数的设置来传递一个初始化函数,然后该初始化函数将在全局命名空间中创建资源。假设资源具有上下文管理器。如果上下文管理的资源必须在流程的整个生命周期中都可以使用,但是在最后要进行适当的清理,您将如何处理它的生命周期呢? 到目前为止,我有点像这样: 从这里开始,池进程可以使用资源。到现在为止还挺好。但是,由于类不提供or或参数,因此处理清理工作有些棘
-
深入理解PHP之OpCode原理详解
本文向大家介绍深入理解PHP之OpCode原理详解,包括了深入理解PHP之OpCode原理详解的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP中OpCode的原理。分享给大家供大家参考,具体如下: OpCode是一种PHP脚本编译后的中间语言,就像Java的ByteCode,或者.NET的MSL。 此文主要基于《 Understanding OPcode》和 网络,根据个人的理解和修
-
AnyLogic批处理代理i. t. o重量
如何将批次大小I.t.o设置为要批次的重量?我目前正在模拟一种马铃薯植物。由于土豆的随机性,土豆(代理)都有自己的重量,但现在我必须将它们分装成10公斤的袋子。重量应该在10kg以上,但不能更小,所以它将是9.9kg加上一个土豆。 F1帮助功能建议使用自定义队列。但我不知道如何继续这一选择。 任何帮助都将不胜感激
-
处理海量数据的Spring批处理
我的数据库中有大约1000万个blob格式的文件,我需要转换并以pdf格式保存它们。每个文件大小约为0.5-10mb,组合文件大小约为20 TB。我正在尝试使用spring批处理实现该功能。然而,我的问题是,当我运行批处理时,服务器内存是否可以容纳那么多的数据?我正在尝试使用基于块的处理和线程池任务执行器。请建议运行作业的最佳方法是否可以在更短的时间内处理如此多的数据
-
Docker Nginx代理:容器之间的代理
问题内容: 我目前在公司中使用Docker-Compose运行开发堆栈,以向开发人员提供他们编写我们的应用程序所需的一切。 它尤其包括: 一个Gitlab容器(sameersbn / gitlab),用于管理私有GIT存储库, 一个用于构建和持续集成的Jenkins容器(library / jenkins), 一个Archiva容器(ninjaben / archiva-docker)管理Mave
-
Scala如何处理理解中的条件?
我试图创建一个简洁的结构,用于理解基于未来的业务逻辑。下面是一个示例,其中包含一个基于异常处理的工作示例: 然而,这可能被视为一种非功能性或非Scala的处理方式。有更好的方法吗? 请注意,这些错误来自不同的来源——有些在业务级别(“检查所有权”),有些在控制器级别(“授权”),有些在数据库级别(“找不到实体”)。因此,从单一常见错误类型派生它们的方法可能不起作用。
-
spark流式处理失败的批处理
我在spark streaming应用程序中看到一些失败的批处理,原因是与内存相关的问题,如 无法计算拆分,找不到块输入-0-1464774108087
-
spring批处理不处理所有记录
我正在使用spring批处理使用RepositoryItemReader从postgresql DB读取记录,然后将其写入主题。我看到大约有100万条记录需要处理,但它并没有处理所有的记录。我已经将reader的pageSize设置为10,000并且与提交间隔(块大小)相同
-
Spring批处理块处理提交频率
如果我正在读写本地文件,那么对远程数据库服务器的更新相对昂贵。如果增加[chunk-size],内存使用量就会上升。 提交频率对编写本地文件并没有太大的影响,所以对我来说,元数据更新才是一个问题。该步骤是可重新启动的,因此从技术上讲,我不需要记录中间提交计数。 对于JobRepository,我可以只使用map或内存数据库,但我需要其他信息,例如持久化的开始/结束时间,而且这个问题只涉及一个步骤。
-
Apache Flink错误处理和条件处理
我是Flink的新手,已经通过网站/示例/博客开始学习。我正在努力正确使用操作符。基本上我有两个问题 问题1:Flink是否支持声明性异常处理,我需要处理解析/验证/。。。错误? 我可以使用组织吗。阿帕奇。Flink。运行时。操作员。分类ExceptionHandler或类似的程序来处理错误 还是Rich/FlatMap功能是我的最佳选择?如果Rich/FlatMap是唯一的选项,那么是否有办法在
-
流处理和消息处理的区别
流处理和传统消息处理的基本区别是什么?正如人们所说,kafka是流处理的好选择,但本质上,kafka是一个类似于ActivMQ、RabbitMQ等的消息传递框架。 为什么我们通常不说ActiveMQ也适合流处理呢。 消费者消费消息的速度是否决定了它是否是流?
-
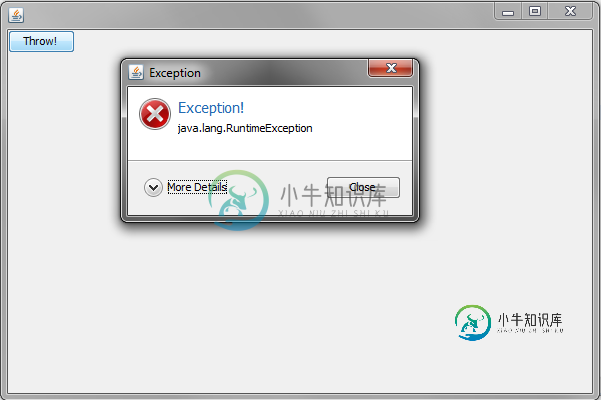 在GUI中处理未处理的异常
在GUI中处理未处理的异常我主要是为技术精明的人编写一个小工具,例如程序员、工程师等,因为这些工具通常是快速的,随着时间的推移,我知道会有未处理的异常,用户不会介意。我希望用户能够向我发送回溯,这样我就可以检查发生了什么,并可能改进应用程序。 我通常做wxPython编程,但我最近做了一些Java。我已经将