《同花顺》专题
-
火花码给出错误
我在运行下面我写的SPARK代码时出错了。我试图根据键找到所有向量的总和。每个输入行以键(整数)开始,然后是127个浮点数,这是一个具有127个维度的单个向量,即每一行以键和向量开始。
-
火花流集成水槽
我遵循火花流水槽集成的指导。但我最终无法获得任何事件。(https://spark.apache.org/docs/latest/streaming-flume-integration.html)谁能帮我分析一下?在烟雾中,我创建了“avro_flume.conf”的文件,如下所示: 在文件中,123.57.54.113是本地主机的ip。 最后,根本没有任何事件。 怎么了?谢谢!
-
使用Tweepy的火花流
我正在尝试使用python库Tweepy来传输twitter数据。我设置了工作环境,谷歌了一下这些东西,但是我不知道它们是如何工作的。我想在python (tweepy)中使用spark streaming(DStream-Batch processing)。我至少经历了以下环节: < li >如何获取tweepy中某个位置的特定标签的推文? < Li > http://spark . Apach
-
火花教程的问题
我正在尝试 https://github.com/apache/spark/blob/v2.0.1/examples/src/main/scala/org/apache/spark/examples/sql/streaming/StructuredNetworkWordCountWindowed.scala 个例子。 但是,指定端口号处的输入应该是什么?
-
森林火花斯卡拉
我尝试使用I forest https://github.com/titicaca/spark-iforest,的scala实现,但是当我构建时(就像README中报告的< code>mvn clean package),它给我这些错误: 有人知道为什么吗?谢谢 scala版本2.11.12 火花版本2.4.0 maven版本3.5.2 我修改了pom.xml,调整了scala、spark和mav
-
番石榴/火花问题
我的 Spark 版本是 2.2.0,它在本地工作,但在具有相同版本的 EMR 上,它给出了以下异常。
-
 闲置的火花工人
闲置的火花工人我已经配置了连接到Cassandra集群的独立spark集群,其中有1个主服务器、1个从服务器和Thrift服务器,该服务器用作Tableau应用程序的JDBC连接器。无论怎样,当我启动任何查询时,从属服务器都会出现在工作者列表中。所有工作负载都由主执行器执行。同样在Thrift web控制台中,我观察到只有一个执行器处于活动状态。 基本上,我希望火花集群的两个执行器上的分布式工作负载能够实现更高
-
火花纱远程提交
我可以从IDE(远程)编程运行这个程序吗?我使用Scala-IDE。我寻找一些代码来遵循,但仍然没有找到合适的 我的环境:-Cloudera 5.8.2[OS redhat 7.2,kerberos 5,Spark2.1,scala 2.11]-Windows 7
-
火花列明智字数
我们正试图在spark中生成数据集的逐列统计数据。除了使用统计库中的summary函数之外。我们使用以下程序: > 我们确定具有字符串值的列 为整个数据集生成键值对,使用列号作为键,使用列的值作为值 生成新的格式映射 (K,V)- 然后我们使用reduceByKey来找到所有列中所有唯一值的总和。我们缓存这个输出以减少进一步的计算时间。 在下一步中,我们使用for循环遍历列,以查找所有列的统计信息
-
带点火花的列名
我试图从获取列,并将其转换为。
-
SpringJPA花了太多时间
我正在开发一个spring批处理应用程序(内存为2GB),尝试处理数据(在处理过程中使用select查询获取数据),并在postgres DB中插入大约100万条处理过的记录。我在这个项目中使用Spring Data JPA。但是Spring JPA在处理这些记录时消耗了太多内存
-
安装cassandra火花接头
编辑1 当选择正确的scala版本时,它似乎会更进一步,但我不确定下面的输出是否仍然有需要解决的错误:
-
雪花时间戳转换
下面的代码给出了2021年8月6日星期五12:16:27 GMT-0700(太平洋夏时制)的值,而不是mm/dd/yyyy hh:mm:ss。我在这里漏掉了什么?请告知
-
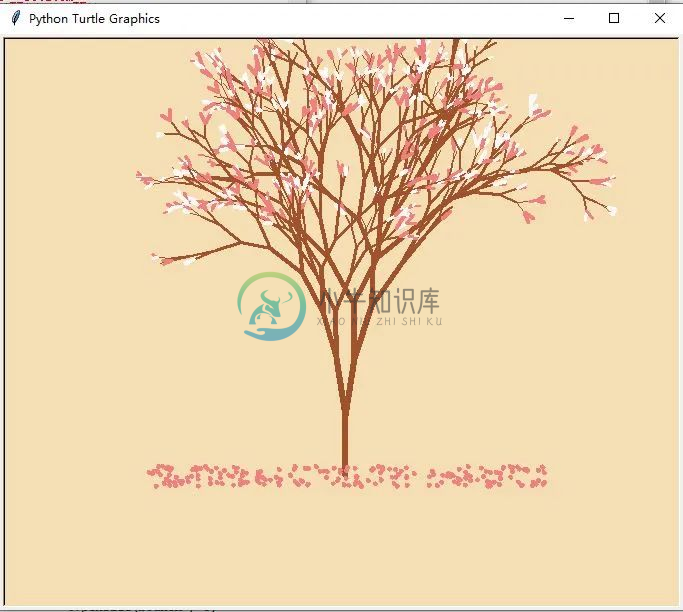 教你用python画樱花
教你用python画樱花现在让我们从用Python画一朵樱花开始吧~
-
花生壳-安装介绍
CentOS 下过程 官网:http://hsk.oray.com/ 官网下载:http://hsk.oray.com/download/#type=linux 官网安装说明:http://service.oray.com/question/1890.html 软件包下载:wget http://download.oray.com/peanuthull/linux/phddns-2.0.6.el6