《同花顺》专题
-
火花UDF过载
我有一个要求,火花UDF必须超载,我知道UDF超载是不支持火花。因此,为了克服spark的这一限制,我尝试创建一个接受任何类型的UDF,它在UDF中找到实际的数据类型,并调用相应的方法进行计算并相应地返回值。这样做时,我得到一个错误 以下是示例代码: 有可能使上述要求成为可能吗?如果没有,请建议我一个更好的方法。 注:Spark版本-2.4.0
-
JDBC火花连接
我正在研究建立一个JDBC Spark连接,以便从r/Python使用。我知道和都是可用的,但它们似乎更适合交互式分析,特别是因为它们为用户保留了集群资源。我在考虑一些更类似于Tableau ODBC Spark connection的东西--一些更轻量级的东西(据我所知),用于支持简单的随机访问。虽然这似乎是可能的,而且有一些文档,但(对我来说)JDBC驱动程序的需求是什么并不清楚。 既然Hiv
-
 JavaScript 秘密花园
JavaScript 秘密花园JavaScript 秘密花园是一个不断更新,主要关心 JavaScript 一些古怪用法的文档。 对于如何避免常见的错误,难以发现的问题,以及性能问题和不好的实践给出建议, 初学者可以籍此深入了解 JavaScript 的语言特性。 JavaScript 秘密花园不是用来教你 JavaScript。为了更好的理解这篇文章的内容, 你需要事先学习 JavaScript 的基础知识。在 Mozill
-
JavaScript 秘密花园
这篇文章的作者是两位 Stack Overflow 用户, 伊沃·韦特泽尔 Ivo Wetzel(写作) 和 张易江 Zhang Yi Jiang(设计)。
-
妙码生花 - BuildAdmin
项目是基于Thinkphp6、Vue3、TypeScript、Vite、Pinia、Element Plus等最新稳定技术栈的后台管理系统,支持CRUD代码生成、内置WEB终端可直接执行npm install等命令、还内置了管理员管理/附件管理/会员管理/数据全局回收站/敏感数据修改记录等功能,无需授权即可免费商用,希望可以帮助大家快速开发。 主要特性 �� CRUD代码生成 一行命令即可生成数据
-
火花流后立即使用火花RDD过滤器
我正在使用火花流,我从Kafka读取流。阅读此流后,我将其添加到hazelcast地图中。 问题是,我需要在读取Kafka的流之后立即从地图中过滤值。 我正在使用下面的代码来并行化地图值。 但在这个逻辑中,我在另一个逻辑中使用JavaRDD,即JavaInputDStream.foreachRDD,这会导致序列化问题。 第一个问题是,如何通过事件驱动来运行spark作业? 另一方面,我只是想得到一
-
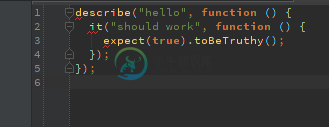 WebStorm茉莉花集成-JSHint无法识别茉莉花
WebStorm茉莉花集成-JSHint无法识别茉莉花我使用文件在 Webstorm 8.0.4 中设置了茉莉花集成 这与语法突出显示的工作方式一样,我可以跳转到声明,文档显示正确。所以连接看起来很好。然而,JSHint仍然为每个关键字抱怨它没有被定义,例如 另请参见以下屏幕截图。正如您所看到的,语法突出显示很好,但我仍然收到一个错误。
-
火花SQL:为什么火花不一直做广播
我在aws s3和emr上使用Spark 2.4进行项目,我有一个左连接,有两个巨大的数据部分。火花执行不稳定,它经常因内存问题而失败。 集群有10台m3.2xlarge类型的机器,每台机器有16个vCore、30 GiB内存、160个SSD GB存储。 我有这样的配置: 左侧连接发生在 150GB 的左侧和大约 30GB 的右侧之间,因此有很多随机播放。我的解决方案是将右侧切得足够小,例如 1G
-
自Android 6棉花糖以来,javax.crypto.Cipher的工作方式有所不同
问题内容: 我已经成功使用javax.crypto.Cipher.getInstance(“ DESede / CBC / NoPadding”)在Android上通过DESFire卡进行身份验证 。它可以在Android 4到5的多种设备上运行,但是在我更新为6棉花糖(和6.0.1)的Nexus 7上停止了工作。在更新之前,它一直在同一设备上工作。 似乎Cipher的工作方式不同,对于相同的密钥
-
为什么结果根据花括号的位置而有所不同?
问题内容: 当左花括号在新行上时,返回,并且警报中显示“ no-it break:undefined”。 当花括号与处于同一行时,将返回一个对象,并警告“奇妙”。 问题答案: 这是JavaScript的陷阱之一:自动分号插入。不以分号结尾但可能是语句结尾的行会自动终止,因此您的第一个示例实际上是这样的: 在第二个示例中,您返回一个对象(由花括号构建),该对象的属性及其值为,实际上与此相同:
-
火花流-4核和16核的处理时间相同。为什么?
场景:我正在用spark streaming做一些测试。大约有100条记录的文件每25秒就出现一次。 问题:在程序中使用local[*]时,4核pc的处理时间平均为23秒。当我将相同的应用部署到16核服务器时,我期望处理时间有所改善。然而,我发现它在16个内核中也花费了同样的时间(我还检查了ubuntu中的cpu使用率,cpu得到了充分利用)。所有配置默认由spark提供。 问题:处理时间不应该随
-
茉莉花2.0异步完成()和角-inject()在同一测试中它()
问题内容: 我通常的测试用例看起来像 而且Jasmine 2.0异步测试应该看起来像 如何在一次测试中同时使用完成和注入? 问题答案: 这应该起作用;我更新到Jasmine 2.0时遇到了同样的问题
-
Impala:如何查询具有不同模式的多个拼花文件
在Spark 2.1中,我经常使用类似的东西 加载拼花文件文件夹,即使使用不同的模式。然后,我使用SparkSQL对数据帧执行一些SQL查询。 现在我想试试黑斑羚,因为我读了这篇维基文章,其中包含如下句子: Apache Impala是一个开源的大规模并行处理(MPP)SQL查询引擎,用于存储在运行Apache Hadoop[…]的计算机集群中的数据。 读取Hadoop文件格式,包括text、LZ
-
如何分区通过火花中的列并在将数据帧保存在火花scala之前删除相同的列
假设我们有一个列为col1、col2、col3、col4的数据帧。现在,在保存df时,我想使用col2进行分区,并且我将保存的最终df不应该有col2。所以最终的df应该是col1、col3、col4。关于如何实现这一点,有什么建议吗?
-
火花雪花连接器是否仅适用于databricks spark?
使用databricks spark,可以使用spark雪花连接器(spark-snowflake_2.11-2.3.0.jar,snowflake-jdbc-2.8.1.jar)将数据写入snowflake,而不使用jdbc连接。但如果没有databricks,当我尝试在安装spark的本地机器中应用相同的代码时,我无法使用spark snowflake连接器将代码写入snowflake。我面临