《DB》专题
-
Cosmos DB:如何在创建文档时将分区键值设置为id?
我创建一篇文章。 宇宙数据库设置其 我将其设置为<-how?
-
为什么我的Azure Cosmos DB SQL API容器拒绝使用相同分区键值的多个项?
在Azure Cosmos DB(SQL API)中,我创建了一个容器,它的“分区键”设置为,现在我正在尝试在data Explorer中创建和编辑数据。 我看到,如果将的值更改为其他值(例如),则可以保存这个新项。 要么我对这个功能的期望是错误的,要么我在某种程度上做错了。这里怎么了?
-
无法在Azure Cosmos DB中用中文替换分区密钥头中的项
我尝试使用golang在Azure Cosmos db中使用github.com/vippsas/go-cosmosdb包进行CURD操作。 我相信JS SDK或我使用的包都是基于Azure Cosmos DB Restful API的。我想这个包裹很可能少了什么。
-
在Azure Cosmos DB中,这是一个糟糕的分区密钥方案吗?
我的下一个想法是将时态数据作为分区密钥的一部分。这似乎是有意义的,因为我们每天都在批量导入大量的时间戳数据。而且,99%的针对该数据库的查询都包含日期范围。我提出了一个派生的抽象值,在上面的文档中标记为。此值将帐户id与时间因子(每个电话的年和月)组合在一起。使用该方案,每个租户每年将获得12个分区,而不是整个帐户的单个分区。每个租户的容量仍然不同,所以我们仍然会有一些大的分区和一些小的分区。但是
-
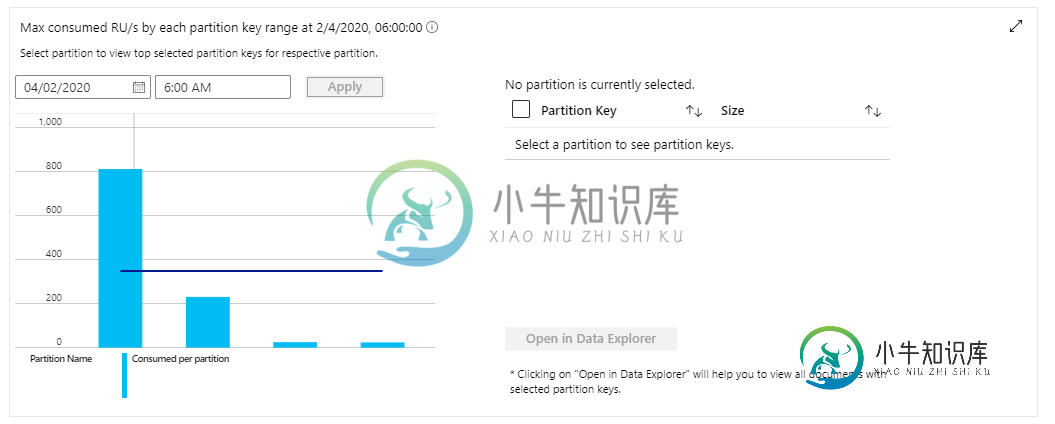 Azure cosmos DB物理分区不平衡,没有指示热分区键
Azure cosmos DB物理分区不平衡,没有指示热分区键我有这个问题:新的物理分区正在为我创建,请求经常发生在同一个分区上。我想知道这怎么可能,因为我没有指示热分区键? 我唯一的分区密钥是一个id,其组成如下: 用户id_年份_旅行号
-
cosmos DB-'逻辑分区‘计数和每个逻辑分区图所需的项目数
我确实遵循了如何在Cosmos DB中查找逻辑分区计数和大小的答案,这导致我选择了“https://docs.microsoft.com/en-us/azure/cosmos-db/use-metrics#decision-the-aphultis-distributions”。然而,该报告不再出现在Azure Portal上。我得到的只是“通过贯穿和存储的顶级逻辑分区键”。我想要一个我的所有“逻
-
Cosmos DB分区密钥选择
巴拉特
-
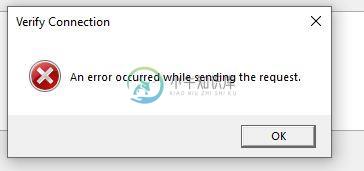 发送请求时发生Azure cosmos db迁移工具错误
发送请求时发生Azure cosmos db迁移工具错误我无法连接到Azure cosmos迁移工具,得到一个错误,比如:发送请求时发生了一个错误。
-
Azure Cosmos DB分区
-
Cosmos DB中用户配置文件文档的适当分区密钥是什么
如果我为上面的集合选择作为分区键,这意味着它将创建100万个逻辑分区(并且没有基数)。是分区密钥的合适候选项吗?我可以选择分区键作为或文档中的任何其他键,以具有良好的基数;但是它会在查询中产生问题,因为它们将是基于的跨分区扫描来过滤文档。 对于上面文档的适当分区键应该是什么有什么建议吗?
-
collection上的Azure Cosmos db唯一键
我阅读了这篇文章,但这里只介绍了每个分区的唯一密钥:https://docs.microsoft.com/en-us/azure/cosmos-db/unique-keys。 我在谷歌上搜索了很多,但我找不到任何关于英国收藏的结果。这可能吗?如果是,有没有关于它的文件?
-
 无法使用数字分区键查询Cosmos DB
无法使用数字分区键查询Cosmos DB我试图使用数字字段作为分区键,但无法在它们上运行存储过程。我不确定我是否做错了什么,或者这是不可能的。 我有两个集合,有两个不同的分区键。 集合1中的示例文档
-
Azure cosmos db集合未获取分区密钥
当我转到并检查我的文档数据库时,集合就创建了。当我转到集合的时,我看不到分区键。 我手动创建了另一个集合,它在部分中显示了分区键。 由于此分区键错误,函数引发错误
-
在Cosmos DB中,物理分区在逻辑分区之间分割的吞吐量如何?
我试图理解Azure Cosmos DB中物理/逻辑分区和吞吐量可用性之间的关系,并有一个关于每个逻辑分区可用吞吐量的问题。 物理分区的可用吞吐量是在逻辑分区之间平均分配,还是在任何逻辑分区都可以使用物理分区可用吞吐量的0-100%的意义上随机分布? > 在这篇Cosmos DB Conf演示文稿-中,演示者提到物理分区可用的吞吐量均匀地分布在物理分区内的所有逻辑分区中(或者至少我是这样推断的)。
-
 为什么cosmos db为同一个分区键值创建5个分区?
为什么cosmos db为同一个分区键值创建5个分区?我们使用的是Cosmos DB SQL API,下面是一个集合: 大小:无限 吞吐量:50000 RU/s PartitionKey:散列 我们将插入200,000条记录,每个记录的大小为2.1KB,并且分区键列的值相同。据我们所知,具有相同分区键值的所有文档都存储在同一个逻辑分区中,无论我们是在固定大小的集合还是在无限大小的集合中,逻辑分区都不应超过10 GB的限制。 显然,我们的总数据甚至不到