《DB》专题
-
 DBeaver无法访问非默认数据库
DBeaver无法访问非默认数据库我正在使用DBEAVER3.8.0,并试图建立到本地PostgreSQL数据库的一般连接。 若要查看所有数据库,请选中“显示非默认数据库”复选框。当我试图访问我的一个数据库的架构时,我得到了错误
-
DBeaver只能在连接中看到默认的PostgreSQL数据库
我在Windows上使用DBeaver V5.2.5并使用它连接到PostgreSQL数据库。 要创建连接,我必须指定数据库,并且我没有在同一服务器上看到其他数据库的意思。 在windows版本上是否有等效的设置?
-
DB2创建表失败
我在我们的测试Databse上用Liqibase创建了一个表,我们没有问题创建下表: 如果我在客户数据库上运行此语句,则错误如下: DB2 SQL 错误: SQLCODE=-104, SQLSTATE=42601, SQLERRMC=(;LT 当前时间戳;DEFAULT, DRIVER=4.13.127 有什么建议吗?
-
DB2存储过程razor sql
我试图使用RazorSQL客户端在DB2数据库中创建一个存储过程,但遇到了以下错误: 块引用错误:字符、标记或子句无效或丢失。DB2SQL错误:SQLCODE=-104, SQLSTATE=42601, SQLERRMC=SELECT 存储过程代码为:
-
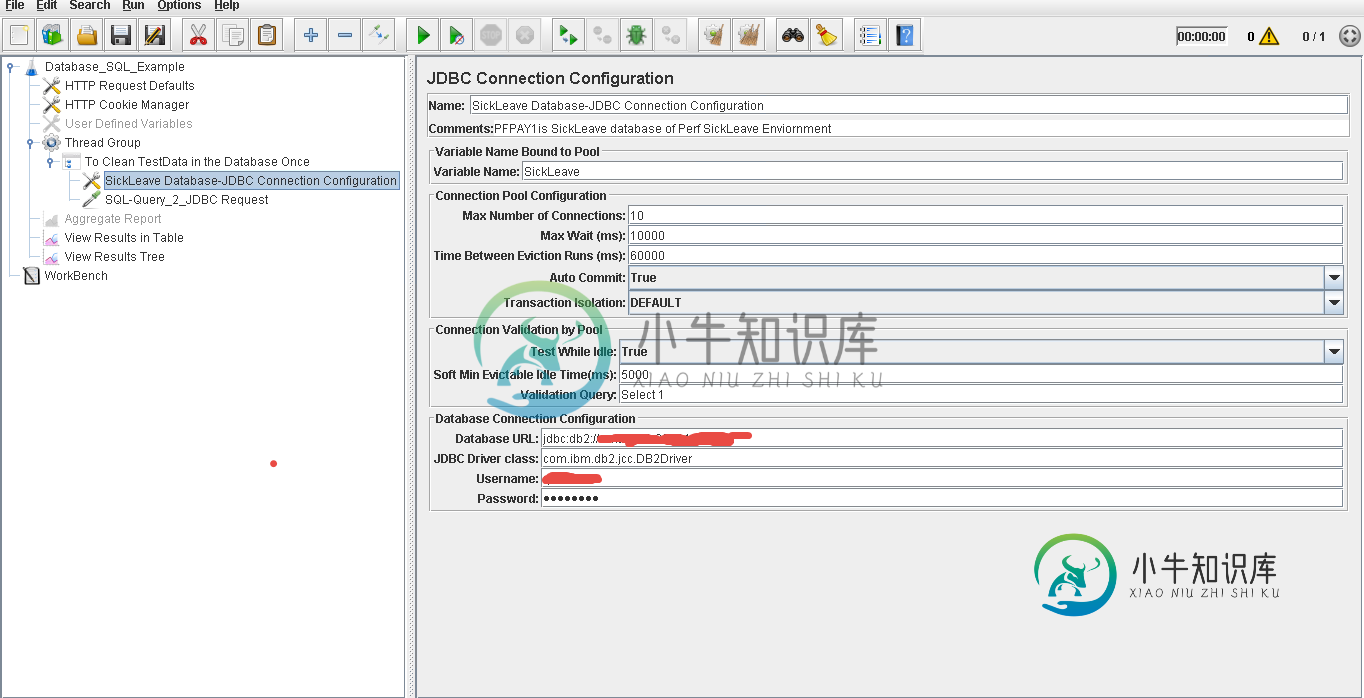 Jmeter throws 无法为 DB2 创建 PoolableConnectionFactory
Jmeter throws 无法为 DB2 创建 PoolableConnectionFactoryJmeter版本3.2 我已经将jar文件db2jcc.jar、db2jcc4.jar和db2jcc_license_cisuz.jar复制到了lib目录中。 当我执行jdbc请求得到下面error.Not确定我还错过了什么。 无法创建 PoolableConnectionFactory (DB2 SQL Error: SQLCODE=-104, SQLSTATE=42601, SQLERRMC=
-
读取CVS文件后,从BatFile创建H2 Db
一切工作只是试图消除一个步骤,我有2个批处理文件 1)读取csv文件,创建表格并保存为压缩文件 如果存在表,则删除表1;创建表2(col1VARCHAR(10)Not NULL, col2VARCHAR(10)NULL)作为SELECT*from CSVREAD('Table1.csv'); 脚本到'MyDB.sql'压缩放气; 2)从第一个batfile获取压缩文件并创建DB文件 java.ex
-
H2 DB CSVREAD不翻译换行符
我想使用嵌入在我的应用程序中的 H2 数据库来创建一个由 CSV 文件填充的内存中数据库。所以我使用了CSVREAD函数。 除了一个麻烦的问题之外,一切都很好,那就是它似乎无法识别换行符。它将字面上翻译为两个字符和。 文档说默认的转义字符是引号,但是如果我尝试使用引号来转义除另一个引号之外的任何其他内容,它只会在那里结束记录。 有没有可能将带有换行符的文本放入CSV文件中,并让H2的CSVREAD
-
Single JDBC OracleDataSource/HikariCP with primary/backup DB
我正在尝试设置一个引用我们的主数据库的单个连接池,直到所述变得不正常,之后池故障转移,填满我们的备份。到目前为止,我一直在利用应用程序服务器的JNDI数据源的未记录功能,该功能允许我指定2个JDBC连接URL字符串: 我有以下代码,毫无疑问,部分是几个月前从一些Hikari / Spring文档中抄录下来的。 我的Google-Fu让我失望了。有人对如何实现故障转移功能有什么想法吗? Edit-r
-
在Azure函数中从Azure服务总线接收JSON(Cosmos DB文档)作为输入
到目前为止,我正在与以下工作: 具有单路输出的f1 具有ICollector输出的f1 引发此异常: 2018-05-15T20:48:21.535[错误]执行函数Functions.ServiceBusQueuetRiggerCSharp1时出现异常。Microsoft.Azure.WebJobs.Host:异常绑定参数“My QueueItem”。Microsoft.azure.WebJobs
-
Spring Boot 无法更新 azure cosmos db(MongoDb) 上的分片集合
我在数据库中有一个集合“documentDev ”,其切分关键字为“dNumber”样本文档: 如果我尝试使用任何查询工具更新这个文档,比如- 它会正确更新文档。但是如果我确实使用了Spring boot的mongorepository命令,如DocumentRepo.save(Object),它会引发异常 由以下原因引起:com.mongodb.MongoCommandException:命令失
-
如何使用spring oauth2和DB实现资源服务器和身份验证服务器?
如何使用spring oauth2和DB实现资源服务器和身份验证服务器,以及如何使用以下模式:https://github.com/spring-projects/spring-security-oauth/blob/master/spring-security-oauth2/src/test/resources/schema.sql 测试数据会很棒!!!
-
Spring Batch无法通过DB(postgres)获得作业锁
我有几个运行在不同节点上并执行Spring批处理作业的“Orchestrator”微服务实例。一次只有一个实例必须是“活动的”并执行该作业。每天通过带有cron表达式的注释调度作业两次。因此,mocriservice尝试使用一个标识的作业来执行,该作业是一个被截断为秒,以补偿我的实例所运行的OpenShift节点之间的时间差。底层DB是Postgres12,事务隔离级别设置为可重复读取。 这个问题
-
Spring批量分区DBtoFile Java配置示例
我目前正在开发Spring Boot和Spring Batch应用程序,以从数据库中读取200,000条记录,对其进行处理并生成XML输出。 我编写了一个单线程Spring批处理程序,它使用<code>JDBCPagingItemReaderStateVentItemReader生成此输出。整个过程需要30分钟。我想通过使用Spring批处理本地分区来增强这个程序。任何人都可以共享Java配置代码
-
Spring Batch:我们如何从DB预加载值,它将用于处理器部分
我需要在ItemProcessor部分查找几个表。我不想对ItemProcessor部分中的每一行进行多个JDBC调用,当spring批处理开始处理更多记录时,这可能会导致性能问题。避免这种情况的变通方法是什么?有没有办法在ItemProcessor之前或批处理开始之前预加载这些对象,并在ItemProcessor中引用它们?
-
Spring data-db to jms-如何设置已处理的标志?
新到Spring批次... 我已经设置了一个Spring批处理项目,该项目使用自定义ItemReader从数据库中读取项,使用ItemProcessor将它们转换为XML,并将它们放在ItemWriter中的JMS队列中。 在块的同一事务中需要做的是将数据库中的原始项标记为已发送。 这个逻辑会去哪里?我是否需要在同一步骤中设置一个额外的Tasklet,就像在留档中建议的那样(5.2.1。Taskl