《驱动》专题
-
在testng中添加selenium android驱动程序jar时出错。找不到类文件?
我正在为一个Android应用程序编写一个测试类,但我不断收到错误代码“项目未生成,因为它的构建路径不完整。找不到org.openqa.selenium.html5.BrowserConnection的类文件。修复构建路径,然后尝试构建这个项目。”每次我都尝试将selenium Android驱动程序jar文件添加到项目中。我需要Android驱动程序正确使用带有Appium的TestNG,否则A
-
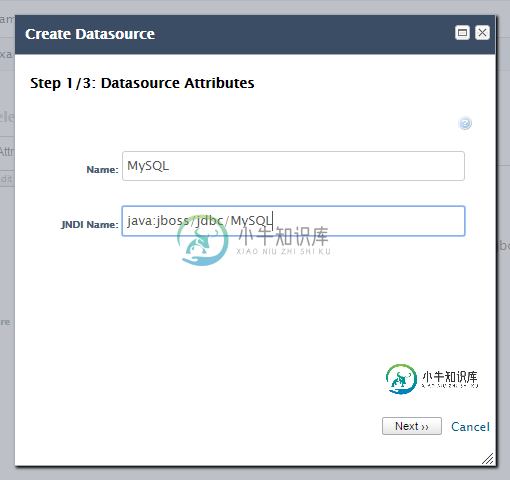 在JBoss新建数据源向导中没有可选择的MySQL驱动程序
在JBoss新建数据源向导中没有可选择的MySQL驱动程序我正在尝试使用JBoss(7.1.1)向导添加一个新的MySQL数据源。我有这样的结构: $jboss_dir/modules/com/mysql/main/module.xml的内容: 我在$jboss_dir/standalone/configuration/standalone.xml中的datasources/drivers标记下添加了这一行: 要尝试此操作,首先启动服务器(没有错误消息)
-
如何打开位于C/D/驱动器中的Jupyter笔记本文件?[副本]
我试图打开位于我的C.Drive中的python文件,但无法到达那里,因为我只能打开位于桌面或其他文件中的文件。
-
Tomcat 8 Oracle 11 JNDI无法为连接URL 'null '创建类''的JDBC驱动程序
我正在尝试使用Tomcat 8服务器和Oracle 11g数据库在STS中设置Spring 4 MVC应用程序,但在设置数据源时遇到了问题。 我知道Spring设置没有问题,因为没有数据源,它可以正常工作。 下面是数据源 bean: 我的web.xml资源引用: 我的Tomcat服务器。xml资源: - 还有我的背景.xml 我得到的错误是: 错误:无法从java.sql获取JDBC连接。SQLE
-
PostgreSQL 9 JDBC驱动程序为存储过程返回不正确的元数据
我在一个开发商业智能(报告)工具的团队中。我们报告了许多来源,包括存储过程。我们使用JDBC驱动程序提供的元数据来确定存储过程的输入和输出参数。 PostgreSQL 9 JDBC驱动程序似乎错误地返回了过程参数的元数据。 例如,我的存储过程如下所示: 所以它在一个结果集中有一个参数,两列返回。 PostgreSQL驱动程序报告有3个IN参数。 personid(参数) 人员(返回第一列) 名称(
-
使用网络路径或驱动器的Java将文件写入远程位置?
我已经使用Windows共享在服务器上共享了一个文件夹。在我正在运行代码的另一台计算机上,我映射了一个指向该文件夹的网络驱动器。 在我的代码中,我时不时地将文件从本地计算机传输到服务器。类似于这样:
-
如何使用进度数据库配置数据源/驱动程序管理器?
我想在我的Spring Boot应用程序中配置一个进步数据库10.2B连接。 我试图阅读进度文档,但没有找到任何适合我的场景的内容。这是我找到的文档链接:进度文档 我在OpenEdge解决方案中提供了“openedge.jar”驱动程序文件。 但是,我不知道如何使用“pom.xml”中的Maven在Spring Boot中配置不同的DriverClass。 我应该怎么做?我应该创建一个名为“Dat
-
如何通过无头驱动程序访问站点而不被拒绝权限
-
在Oracle JDBC驱动程序中看到额外的连接执行SELECT SYS_CONTEXT查询
无法从连接中找到引用此查询原因的Oracle文档。使用JDBC驱动程序OJDBC7-12.1.0.2.jar 我们看到有一个从DUAL运行SELECT SYS_CONTEXT('userenv','current_schema')的短时间连接 在代码中
-
如何使用Google Drive.NET API v3使用服务帐户访问团队驱动器
这个想法是使用。NET后端应用程序中的服务帐户将文件上载/下载到公司员工共享的团队驱动器。例如,company有其域,并在Google提供用户帐户。此外,员工也有团队动力。其中一个帐户(不是admin)用于创建服务帐户,到目前为止已经完成了以下步骤: 在Google云平台中为组织创建了一个项目 启用了Google Drive API 创建了服务帐户 为该服务帐户创建了密钥 在IAM选项卡中分配编辑
-
驱动程序无法通过使用 SSL 建立与 SQL Server 的安全连接
我在连接到SQL数据库时遇到问题。每当我尝试连接到SQL server时,都会出现以下错误; 这是使用 每当我使用JtDS驱动程序时(如本文所建议的),我仍然无法连接到SQL server,并出现以下错误。 我使用的连接字符串:(使用jtds) 或者不使用jtds时... 我还有一个服务器,它实际上能够使用这些配置运行并连接到数据库。我只是在本地连接数据库时不断遇到这些错误。 我正在运行macOS
-
当服务帐户被删除时,谷歌驱动器文件会发生什么?
有没有办法将这些文件的所有权大规模转移到另一个“通常的”谷歌驱动器帐户?
-
DB2通过IBM客户机访问ODBC驱动程序-列出所有表和列
im通过IBM Client Access ODBC驱动程序与DB2数据库连接。如何列出所有表和列? 像在SQL-Server information_schema.columns中还是在Oracle all_tab_columns中? 你好,丹尼斯
-
Derby给出了ClassNotFoundException:org。阿帕奇。德比。jdbc。使用Maven时嵌入驱动程序
我看过以下主题,但它们没有发布我问题的解决方案: 爪哇。lang.ClassNotFoundException:org。阿帕奇。德比。jdbc。嵌入式驱动程序 未找到JDBC Derby驱动程序 SQLException:未找到适合jdbc的驱动程序:derby://localhost:1527 类[org.apache.derby.jdbc.ClientDriver]未找到异常 找不到类[org
-
Spark Streaming如何在驱动程序和执行者之间安排映射任务?
我使用阿帕奇火花2.1和阿帕奇Kafka0.9。 我有一个Spark Streaming应用程序,它与20个执行程序一起运行,并从具有20个分区的Kafka读取。此Spark应用程序仅执行和操作。 以下是Spark应用程序的作用: 从kafka创建一个直接流,间隔15秒 执行数据验证 使用仅映射的drool执行转换。没有减少转换 使用检查和放置写入HBase 我想知道,如果执行器和分区是1-1映射