《匹配》专题
-
枚举与模式匹配 - match 控制流运算符
Rust 有一个叫做 match 的极为强大的控制流运算符,它允许我们将一个值与一系列的模式相比较并根据相匹配的模式执行相应代码。模式可由字面值、变量、通配符和许多其他内容构成;第十八章会涉及到所有不同种类的模式以及它们的作用。match 的力量来源于模式的表现力以及编译器检查,它确保了所有可能的情况都得到处理。 可以把 match 表达式想象成某种硬币分类器:硬币滑入有着不同大小孔洞的轨道,每一
-
正则表达式以匹配结束的HTML标签
问题内容: 我正在研究一个小的Python脚本来清理HTML文档。它的工作方式是接受KEEP的标签列表,然后解析不在列表中的HTML代码,破坏标签我一直在使用正则表达式来做到这一点,而且我已经能够匹配开始标签和自动关闭标签但不关闭标签。 我一直在尝试匹配结束标记的模式是。在我看来这是合乎逻辑的,所以为什么不起作用?本应匹配任何不是一个锚定标记(不就是“a”是可以anything –这只是一个例子)
-
如何匹配,但排除正则表达式模式?
问题内容: 这个正则表达式模式: 产生以下结果: 如何删除“ cID =“? 谢谢 问题答案: 您可以使用lookbehind(不在Javascript中): 或者,您可以使用分组并获取第一个分组:
-
SQL查询以查找多个条件的匹配项
问题内容: 如果我有一个看起来像这样的表: 还有一个THINGS表,如下所示: 我正在尝试提出一个纯SQL查询,该查询可以让我找出什么可以访问什么。基本上,我想要一个看起来像这样的查询: 并返回“ John”和“ Mary”。关键是访问事物所需的许可数量是任意的。 我觉得这应该很明显,但是我无法提出一个优雅的解决方案。首选与Oracle兼容的解决方案。 编辑: Kosta和JBrooks的解决方案
-
根据匹配条件对SQL记录进行排序
问题内容: 我有这个查询: 是否可以根据首先匹配的条件对从该查询返回的记录进行排序。我想先获取所有匹配的记录,然后再获取其他匹配的记录。 例如,如果我有以下记录: 我希望对它们进行如下排序: 有可能吗? 问题答案:
-
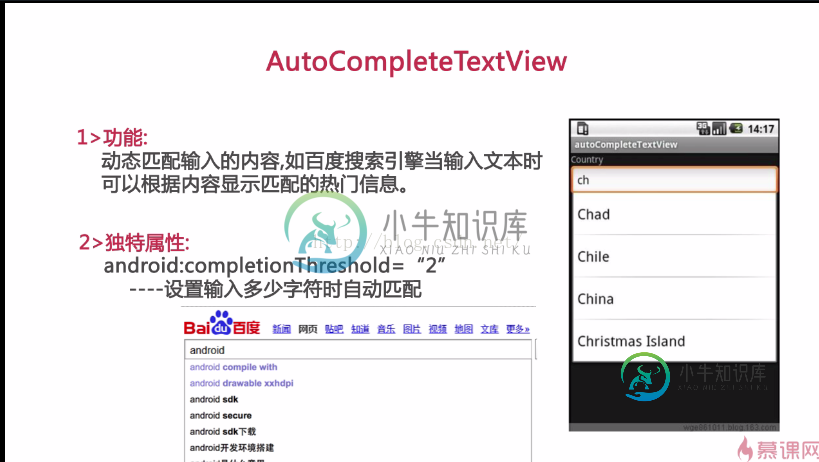 Android实现动态自动匹配输入的内容
Android实现动态自动匹配输入的内容本文向大家介绍Android实现动态自动匹配输入的内容,包括了Android实现动态自动匹配输入的内容的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Android实现动态自动匹配输入内容的具体代码,供大家参考,具体内容如下 用这两个控件 分别实现这两个: 布局文件: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
标头和客户端库次要版本不匹配
问题内容: 在PHP中,每当尝试连接到数据库时,都会收到以下警告(通过) 警告:mysql_connect():标头和客户端库次要版本不匹配。标头:50162图书馆:50524 在我的输出中,我在mysqli下列出了以下值 客户端API库版本=> 5.5.24 客户端API标头版本=> 5.1.62 我已经尝试更新php5-mysql 和 php,但是我已经拥有了两者的最新版本。我该如何更新标头版
-
ASCII“图像”中的“垂直”正则表达式匹配
问题内容: 注意:这是有关现代正则表达式口味的问题。这不是使用其他方法解决此问题的最佳方法。它是由一个较早的问题启发而来的,但是这个问题并不局限于正则表达式。 问题 在ASCII“图像” /艺术/地图/字符串中,例如: 我想找到一个简单的垂直线3 s: 图像中的行数是可变的, 每 行的宽度也是可变的。 问题 使用正则表达式(PCRE / PHP,Perl,.NET或类似文件)可以: 确定是否存在这
-
正则表达式匹配没有标签的链接
问题内容: 这是我的正则表达式,可以很好地匹配字符串中的链接。但是我不希望它选择每个链接。如果链接位于链接之前或之后,则不应对该链接进行数学计算。怎么做到呢? 这些应匹配: 这些不应该匹配: 为什么需要这个?:我希望每个链接都可以单击,即使它不在锚标记之间也是如此。 问题答案: 关于使用正则表达式解析html的所有免责声明,如果您想对这个任务使用正则表达式,则可以使用: 交替匹配的左侧 完成,然后
-
用于Express中路由匹配的正则表达式
问题内容: 我对正则表达式不太满意,因此我想确保自己正确执行了此操作。假设我有两条非常相似的路线,和。我想创建一个匹配这两个页面的路由。 这是正确的方法吗?现在,我只是在创建两条单独的路线。 问题答案: 作品
-
在HTML标签之间预匹配php中的文本
问题内容: 您好,我想在PHP中使用preg_match来解析html文档中以下内容中的“所需文本” 通常,我会使用simple_html_dom进行此类操作,但在这种情况下无法使用(上述元素并未出现在每个所需的div标签中,因此我被迫使用这种方法来准确跟踪何时未出现以及然后从simple_html_dom调整我的数组)。 无论如何,这将解决我的问题。 非常感谢。 问题答案:
-
使用^匹配Python正则表达式中的行首
问题内容: 我正在尝试从Thomson-Reuters Web of Science中提取出版年份的ISI风格数据。“出版年”行如下所示(在行的开头): 对于我正在编写的脚本,我定义了以下正则表达式函数: 但是,由于该模式可能出现在数据的其他位置,因此会产生假阳性结果。 因此,我只想匹配行首的模式。通常,我会为此目的而使用,但是无法匹配我的结果。另一方面,使用似乎可以满足我的要求,但这可能给我带来
-
从Elasticsearch中的数组中选择匹配的对象
问题内容: 我有一个类似于上述对象的文档结构,我只想返回名称为“ abc”的用户,但问题是它与名称“ abc”匹配但返回了所有数组。我只想要匹配的用户。 映射- 问题答案: 然后,如果您将字段映射为类型,则这是一个好的开始! 使用nested,您可以通过如下查询仅检索匹配的用户名:
-
正则表达式以匹配跨平台换行符
问题内容: 我的程序可以接受具有\ n,\ r \ n或\ r换行符的数据(例如Unix,PC或Mac样式) 构造匹配任何编码的正则表达式的最佳方法是什么? 另外,我可以在输入上使用Universal_newline支持,但是现在我很想看看正则表达式是什么。 问题答案: 我想精确使用的正则表达式是。 当我不关心一致性或空行时,我使用,我想这会使我的程序快0.2%。
-
python正则表达式中的括号匹配问题
本文向大家介绍python正则表达式中的括号匹配问题,包括了python正则表达式中的括号匹配问题的使用技巧和注意事项,需要的朋友参考一下 问题: m = re.findall('[0-9]*4[0-9]*', '[4]') 可以匹配到4. m = re.findall('([0-9])*4([0-9])*', '[4]') 匹配不到4. 这是为什么呢?PS,这个是一个简化的说明,我要用的正则比这