《汇编》专题
-
6.7 推荐利用 entry/onpremise 搭建一个 Sentry 异常汇总工具
之前我们说过利用「钉钉群」来通知 Laravel 的异常,但我们发现钉钉的作用更多的是通知我们有异常了,要跟进异常问题了。 我们还是需要有一个地方,很直观的来汇总异常和分析异常,总不能每次出现问题我们都去服务器上看项目的 Log 吧。 在 Laravel 的文档说明中,推荐使用 Bugsnag 或 Sentry: 所有异常都由 App\Exceptions\Handler 类处理。 这个类包含两个
-
 2023秋招汇川技术-项目管理工程师三面面经
2023秋招汇川技术-项目管理工程师三面面经之前在公众号上看到的公司,主要做工业自动化软件的,在苏州,感觉还不错,就打算试一下,本篇是凉经~ 一面面试官是技术面试官,人很好,每提出一个问题都会有个引导,面试结束还会对我的表现做评价,后来也了解了自己的不足之处吧 一面问题: 自我介绍 你面试岗位清楚吗?怎么看项目管理工程师? 你在项目里扮演什么职位,主要职责是什么? 在整个项目过程中,分为三个阶段,事前,事中,事后,有输入(目标是什么),你对
-
如何从汇编程序源以与clang-c main相同的方式生成对象文件。c是的
我想研究一个文件的细节,我已经制作了一个 文件,当我 我得到一个 a.out 文件作为回报,该文件可以直接使用 . 和 会产生错误。 我想生成一个对象文件,其文件类型与的结果相同。我该怎么做? 我可能混淆了操作,导致错误的解释。不生成可执行文件,因此可执行文件是 CLANG 的结果。感谢所有回答者,很抱歉造成混乱,浪费了您的时间。
-
按多个键分组并汇总/列出词典列表的平均值
问题内容: 请问用多个键分组并汇总/平均使用Python词典列表的值的最pythonic方法是什么?假设我有以下词典列表: 所需的汇总输出: 或平均: 我发现了这一点:用Python组合并汇总字典列表的值,但这似乎没有给我我想要的东西。 问题答案: 获取汇总结果 输出量 为了获得平均值,您可以像这样简单地更改for循环内的内容 输出量 建议: 无论如何,我会像这样同时添加和和 输出量
-
nginx、Apache、IIS服务器解决 413 Request Entity Too Large问题方法汇总
本文向大家介绍nginx、Apache、IIS服务器解决 413 Request Entity Too Large问题方法汇总,包括了nginx、Apache、IIS服务器解决 413 Request Entity Too Large问题方法汇总的使用技巧和注意事项,需要的朋友参考一下 一、nginx服务器 nginx出现这个问题的原因是请求实体太长了。一般出现种情况是Post请求时Body内容P
-
汇流复制器无法在目标kafka服务器上复制数据
我已经在两个不同的主机上安装了融合Kafka,并尝试让融合复制器工作。我已经完全遵循了本教程中提到的内容。 当我启动复制器时,我没有看到任何错误,这是我看到的日志: WorkerSourceTask { id = Replicator-source-0 }正在提交偏移量(org . Apache . Kafka . connect . runtime . WorkerSourceTask:397)
-
 2022秋招阿里面试导航汇总-《你想要的都在这里》
2022秋招阿里面试导航汇总-《你想要的都在这里》前言(文中有福利,一定记得要看完) 阿里招聘开始了,最近为小伙伴们准备了校招日程(全),有需要大家可以收藏起来,会持续更新。欢迎和小码哥聊一聊:扣扣群:917138995,可帮查内推进度 &探讨技术细节&刷题经验,最新秋招信息。 综合阿里的招聘信息可以知道阿里P7年收入大部分30-40k左右,另外还有股票和期权。当然高薪资也意味着工作很累,不只是工作忙,而且工作压力也不容小觑。另外社招员工2年后才
-
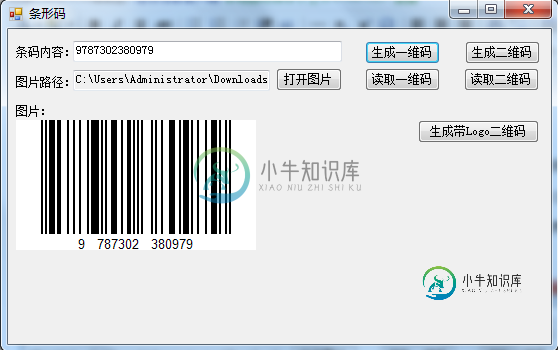 基于C#生成条形码操作知识汇总附源码下载
基于C#生成条形码操作知识汇总附源码下载本文向大家介绍基于C#生成条形码操作知识汇总附源码下载,包括了基于C#生成条形码操作知识汇总附源码下载的使用技巧和注意事项,需要的朋友参考一下 1. 介绍 1.1 条形码 条形码(barcode):是将宽度不等的多个黑条和空白,按照一定的编码规则排列,用以表达一组信息的图形标识符。 1.2 条形码分类 可分为一维条形码和二维条形码: 一维条形码:只是在一个方向(一般是水平方向)表达信息,而在垂直方
-
如何在每个列上执行相同的汇总而不列出列?
问题内容: 我有一个带有 N 列的表。让我们给他们打电话,,,,… 。在多行中,我想为[1,N]中的每个X获得单个行。 有没有一种方法(在存储过程中)而无需手动将每个列名写入查询中呢? 我们遇到了一个问题,即应用程序服务器中的错误意味着我们在以后插入垃圾时重写了良好的列值。为了解决这个问题,我存储了信息日志结构,其中每一行代表一个逻辑查询。然后,在给出记录已完成的信号时,我可以确定是否有任何值(错
-
JS数组排序技巧汇总(冒泡、sort、快速、希尔等排序)
本文向大家介绍JS数组排序技巧汇总(冒泡、sort、快速、希尔等排序),包括了JS数组排序技巧汇总(冒泡、sort、快速、希尔等排序)的使用技巧和注意事项,需要的朋友参考一下 本文实例总结了JS数组排序技巧。分享给大家供大家参考,具体如下: ① 冒泡排序 ② js 利用sort进行排序 ③ 快速排序 ④希尔排序 ⑤ 插入排序 附:js中数组(Array)的排序(sort)注意事项 结论: 1.数组
-
php数组查找重复项,将它们汇总并删除重复项
问题内容: 我有一个数组: 我需要找到具有相同setid的条目,将它们的收入加起来并删除重复的条目-最后,它应该看起来像这样: 有人知道我的问题有解决方案吗?还是我必须走很长的路并手动执行每个步骤? 谢谢和问候 问题答案: 只需创建一个新数组,您就可以使用setid作为键来快速进行寻址。并在最后对数组重新索引。
-
如何在首选项汇总中显示Android首选项的当前值?
例如:如果我有一个“丢弃旧消息”的首选项设置,它指定了需要清理消息的天数。在中,我希望用户看到: “丢弃旧消息”<-title “x天后清理邮件”<-摘要,其中x是当前首选项值 额外的功劳:使它可重用,所以我可以很容易地将它应用到我的所有首选项,而不管它们的类型是什么(这样它就可以使用EditTextPreference,ListPreference等,只需最少的编码量)。
-
在Postgres中使用带有汇总和groupby的子查询进行更新
问题内容: 我正在尝试用另一列分组的该列的最大值更新表中的一列。 例如,假设我们有一个名为transactions的表,其中有两列:和。无论出于何种原因,我们都希望将其设置为等于每个值的最大值。 我很沮丧并且不擅长在SQL中执行这样的操作,但是到目前为止,这是我所拥有的: 问题答案: 除了@Gordon已经指出的语法错误之外,通常最好 排除空更新 : 无需更改任何内容就无需编写新的行版本(几乎需要
-
AWS转录无法通过SDK使用表创建自定义词汇表
AWS Transcripbe提供了两个创建自定义词汇表的选项。有关更多信息,请自定义词汇表 null 失败原因 您试图创建的词汇表包含无效字符或格式不正确的术语。有关更多信息,请参见开发人员指南。 但是我可以使用表(通过AWS控制台)创建相同的语词,所以我不认为我的语词有问题。 我想通过AWS Java SDK使用表创建自定义词汇表。我可以通过AWS控制台创建相同的内容,但通过Java SDK无
-
使用Jackson将json映射到java对象时的所有错误汇总