《慢查询》专题
-
带有多个Elasticsearch群集的Spring Boot启动速度非常慢
我有Spring启动应用程序与三个弹性搜索群集(ES v6.4.2)配置。application.properties文件如下(我为每个集群配置了三个主节点,但为了简单起见,这里显示了一个): 对于每个集群,我都有一个单独的配置类,在其中设置TransportClient和ElasticsearchTemplate。 现在,当我在本地计算机上运行所有三个集群的情况下本地启动应用程序时,应用程序会正
-
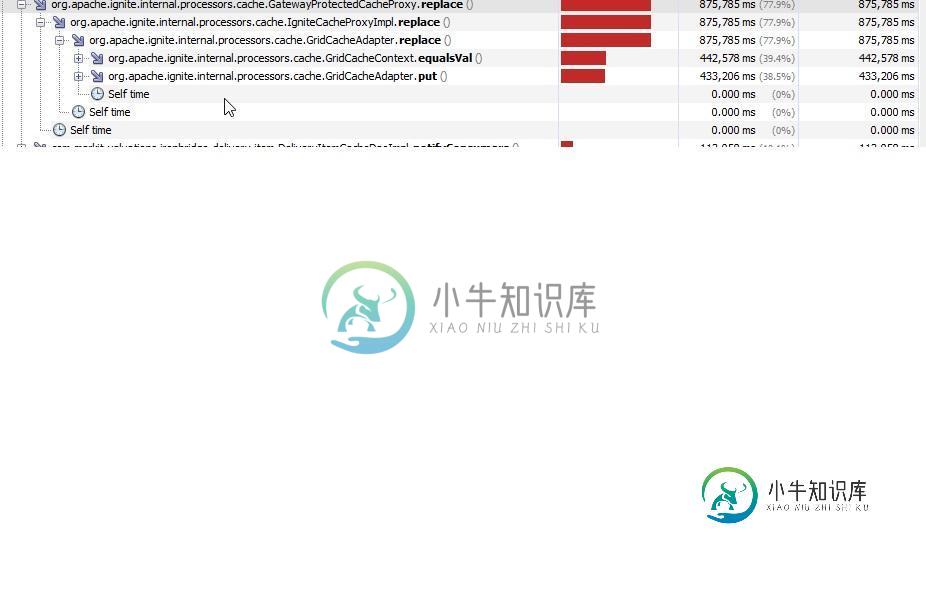 为什么Apache Ignite cache.replace-k-v-v api调用执行得很慢?
为什么Apache Ignite cache.replace-k-v-v api调用执行得很慢?我们正在RHEL平台上运行带有12个节点的Ignite集群,运行在OpenJDK1.8上的Ignite 2.7.0上。 使用使用大量cputime 我们目睹了一个进程的缓慢,当我们试图通过分析JVM来进一步钻探它时,主要的罪魁祸首(占总时间的78%)似乎来自Igniteapi调用。 在77.9个by replace中,39%被gridcacheadapter.equalval占用,38.5%被gr
-
访问静态函数变量比访问全局变量慢吗?
我假设在每次调用时都必须检查其变量是否初始化,因此将比慢,这样做对吗?
-
为什么Delphi zlib和zip库在64位以下如此缓慢?
在对实际应用程序进行基准测试时,我遇到了一个与Delphi附带的zlib和zip库相关的令人惊讶的性能特性。 我使用Explorer shell ZIP功能压缩了同一个文件,我粗略的秒表计时是8秒,所以上面的32位时间似乎是合理的。 由于上面代码使用的压缩算法是zlib(Delphi的邮政编码只支持store和deflate),所以我的信念是Delphi使用的zlib库才是这个问题的根源。为什么d
-
底部导航组合之间的延迟/慢速导航-Jetpack Compose
我正在使用带有4个可组合的。他们都有一个,中的每个项目都有一个使用Coil for Jetpack Compose从网络填充的图像。类似于Twitter / YouTube。 当我在这些项目之间导航时,可组合物会被销毁,只有在导航回它们时才会重新组合。当在这些可组合物之间导航时,甚至线圈图像也会被清除并重新获取(从内存或本地存储中)。这当然是预期的行为。 问题是这会导致它们之间的导航速度太慢。每次
-
如何修复:AndroidTensorFlow Lite推理比标准TensorFlow推理慢得多
我用TensorFlow和Keras开发并训练了一个卷积神经网络。现在,我想把这个模型部署到Android设备上,在那里我需要它来实现实时应用。 我找到了两种将Keras模型部署到Android的方法: 将图形冻结为.pb文件(例如“model.pb”),然后在Android设备上使用“TensorFlowInferenceInterface” 将冻结的图形转换为.tflite模型(例如“mode
-
为什么范围()函数比最小和最大的组合慢?
我碰到了R的< code>range函数。它确实是一个有用的工具,并使代码更具可读性,但是如果用一个简单的包含< code>min和< code>max的一行程序来代替它,它的速度可以提高一倍。 我做了一些基准测试,range函数的“糟糕”性能让我吃惊。为了进行比较,我编写了一个名为< code>range2的函数,它使用了min和max(参见代码)。除了速度之外,如果一个简单的一行程序可以胜过这
-
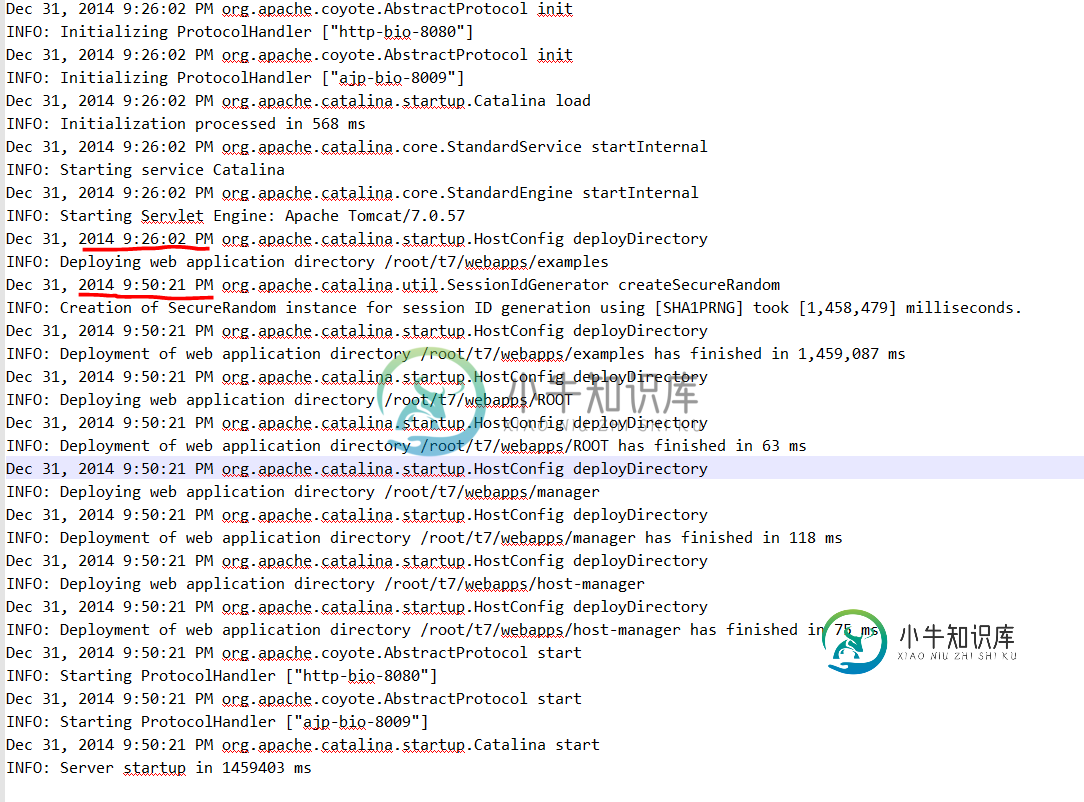 在没有任何配置的情况下缓慢部署tomcat 7
在没有任何配置的情况下缓慢部署tomcat 7Tomcat每次部署花费大约20分钟,我发现它在部署阶段被卡住了,请参见下面的日志, 第一次启动会消耗大约2-7分钟,然后每次重启都会变得更糟。 环境: sudo apt-get install python-software sudo add-apt-repository ppa:webupd8team/java sudo apt-get更新
-
使用datastax java驱动程序2.1.4连接到Cassandra集群太慢
我最近在同一个内网的两台硬件配置完全相同的服务器上搭建了一个只有两个节点的cassandra集群。它与cqlsh配合得很好,一切似乎都很完美。然后我按照datastax网站上的代码示例编写java代码来处理集群,问题就来了。该程序正常工作,它连接到群集,并成功地向其中写入数据和从中读取数据。然而,连接速度太慢了!我将代码部署在一个集群节点所在的同一台机器上,连接需要5秒多的时间。更准确地说,是行s
-
加载Jenkins作业配置页面很慢,没有运行作业
目前,当我们试图打开Jenkins配置页面时,大约需要45秒,而对于其他页面,如请求作业视图或查看控制台输出,则不到3秒。根据线程转储分析结果,我们得到了一个CPU“峰值”,描述为 "您的应用程序可能受到高CPU的困扰。"查看线程报告,我们没有看到任何阻塞状态,但有一个可疑状态:"1个线程是无限循环:DestRoyJavaVM" 不幸的是,我们无法确定这种高CPU的原因,可能还有相关的无限循环。
-
为什么在我的情况下编写simple.xlsx的书非常慢?
我真的需要有人帮忙。我有非常非常奇怪的代码,即使只写2个单元格也要花35秒。(两倍于智能手机等设备)。 注:在计算过程中,这两种方法都没有问题。他们挺快的。不需要调试这些 null null
-
构建异常是否比构建异常供应商慢?[副本]
原始关闭原因未解决 为什么我们要这样写呢?创建异常实例是否比创建供应商实例更昂贵?
-
为什么排序组的分组求和比未排序组慢?
我有2列制表符分隔的整数,其中第一列是随机整数,第二列是标识组的整数,可以由此程序生成。() 然后,我使用第二个程序()计算每个组的和。 如果我在给定大小的数据集上运行这些程序,然后打乱相同数据集的行的顺序,打乱的数据计算总和的速度比有序数据快2倍或更多。 我本来希望按组排序的原始数据具有更好的数据局部性并且速度更快,但我观察到相反的行为。我想知道是否有人可以假设原因?
-
使用Perl6处理大型文本文件,速度太慢。(2014-09)
https://github.com/yeahnoob/perl6-perf 中的代码宿主,如下所示: 在“wordpairs.txt”很小的情况下运行良好。 但是当“单词对.txt”文件大约有140,000行(每行,两个单词)时,它的运行非常非常慢。它不能自己完成,即使在运行20秒后也是如此。 它有什么问题?代码中是否有任何错误??感谢任何人的帮助! 代码(目前,2014-09-04): 运行时
-
PostgreSQL:与sql相比,plpgsql语言的相同请求速度较慢
我是PostgreSQL的新手,我面临着一个关于表函数性能的问题。我需要做的是相当于MSSQL中的存储过程。经过一些研究,我发现一个表函数是可行的,所以我举了一个例子,用plpgsql创建了我的函数。 通过比较执行时间,使用函数比直接调用查询慢2倍(查询在函数中完全相同)。 经过一点挖掘,我发现在函数中使用SQL语言可以大大提高执行时间(与调用查询的时间完全相同)。读了这篇文章后,我了解到plpg