《线程池》专题
-
从另一个线程调用方法时主线程被阻塞
我试图用一个自定义对象创建一个新线程,然后从主线程调用这个自定义对象方法。其思想是,主线程可以继续执行其他任务,而自定义对象可以继续在第二个线程中工作: 输出为: 它应该更像这样: 所以主线程被阻塞,直到方法完成。主线程是否在第二个线程中等待完成(作为返回类型为空,我认为情况不会如此)?还是在第一个线程中执行,因此阻塞了它? 我知道使用下面的代码,我可以在另一个线程中执行,但它每次都会从头开始创建
-
C#多线程与跨线程访问界面控件的方法
本文向大家介绍C#多线程与跨线程访问界面控件的方法,包括了C#多线程与跨线程访问界面控件的方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#多线程与跨线程访问界面控件的方法。分享给大家供大家参考。具体分析如下: 在编写WinForm访问WebService时,常会遇到因为网络延迟造成界面卡死的现象。启用新线程去访问WebService是一个可行的方法。 典型的,有下面的启动新线程示例
-
获取Java线程ID和失控Java线程的堆栈跟踪
问题内容: 在最繁忙的生产安装中,有时会遇到一个似乎陷入无限循环的单线程。经过大量研究和调试,我仍未弄清楚是谁的罪魁祸首,但似乎应该有可能。这是血腥的细节: 当前调试说明: 1) ps -eL 18975 向我展示了Linux pid的问题子线程19269 2) jstack -l 18975 说没有死锁, jstack -m 18975 不起作用 3) jstack -l 18975 确实给了我
-
JVM线程调度器如何控制多处理器的线程?
我一直在阅读有关多线程的Head First。我对多线程的了解是: 当我们使用Thread类的对象调用start()时,线程将进入可运行状态。因此,所有线程在通过这些线程的对象调用start()后都会进入可运行状态。它是JVM线程调度器,它从可运行状态随机选择线程,使其处于运行状态。进入运行状态后,该特定线程的已确定调用堆栈将被执行。 同样,JVM线程调度器可以通过将线程从运行状态切换到可运行状态
-
执行后将子线程的状态传递给其父线程
我想从可运行线程抛出异常,但不可能从线程抛出它,所以我们可以将chlild线程的状态(任何异常)传递给父线程吗?. 我读到过thread.join(),但在这种情况下,父线程会一直等到子线程完成执行。 在我的例子中,我的父线程在一段时间后逐个启动线程,但当任何线程抛出异常时,它应该将失败通知paent,以便父线程不会启动其他线程。 有什么方法可以实现吗?谁能帮我解决这个问题。
-
当通过JNI从本机线程回调时,Java线程泄漏
总结:当从本机创建的线程上的本机代码调用Java时,我看到Java线程泄漏。 (2014年2月11日更新:我们向Oracle提出了支持请求。Oracle已在Java 7 Update 45上确认了这一点。它只影响64位Linux(可能还有Mac)平台:32位Linux不受影响)。 (2014年4月29日更新:Oracle对此问题进行了修复,并将在Java 7 Update 80中发布)。 我有一个
-
如何与子线程共享父线程本地对象引用?
用例 我有一个基于gRPC Guice的服务应用程序,其中对于特定的调用,代码流如下所示:
-
创建2个线程,每个线程运行不同的任务
-
主线程执行完成后Spring批处理线程不返回
我是spring batch的新手。我已经使用多个线程从spring创建并成功执行了作业,它工作得很好,只是当程序执行完成时,程序流不会结束/停止。i、 即使main方法的最后一条语句被执行,程序也不会退出。我不确定它是否一直在等待线程完成,或者是什么。有人能给我一些建议吗?“下面是我的作业配置文件 下面是启动器代码 如上所述,代码在5个不同的线程中为任务“hello”运行,为任务“world”运
-
当主线程调用sys.exit()时,其他线程会发生什么?
来自文档:http://docs.python.org/2/library/thread 让我们在这里只讨论非守护进程线程。因为第一个引号没有特别提到非守护进程线程,所以我假设,如果主线程退出,即使是非守护进程线程也应该被杀死。然而,第二句引文却表明了另一种情况。事实上,当主线程退出时,非守护进程线程确实不会被杀死。那么,这里的第一个引用有什么意义呢?
-
为什么Spring批处理是单线程而不是多线程
我正在通过quartz调度程序调用spring批处理作业,它应该每1分钟运行一次。当作业第一次运行时,成功打开ItemReader并运行作业。但是,当作业尝试第二次运行时,它使用的是第一次运行的相同实例,该实例已经初始化,并接收“java.lang.IllegalStateException:Stream is eignitialized.Close before re-opening”。我已经将
-
Java消费者线程等待所有生产者线程完成
我有一个生产者-消费者模式的多线程任务。可能有许多生产者和一个消费者。我使用ArrayBlockingQueue作为共享资源。 Producer类中的run()方法: Consumer类中的run()方法: main()方法: 现在,当队列为空时,我有消费者结束条件。但是可能会有一段时间队列变成空的,但是一些生产者线程仍然在工作。所以我只需要在完成所有生产者线程之后才完成消费者线程(但它们的数量事
-
连接线程如何影响主线程中的执行顺序?
我知道线程是并发运行的,所以您无法预测执行的顺序,但在提供的代码中,我在运行其他代码之前加入了thread。如果应该等到线程执行完毕,那么为什么顺序仍然是随机的呢?在两个print语句之前加入任何内容总是会导致它们最后被打印,而如果我在之后加入所有内容,它并不总是最后,为什么?
-
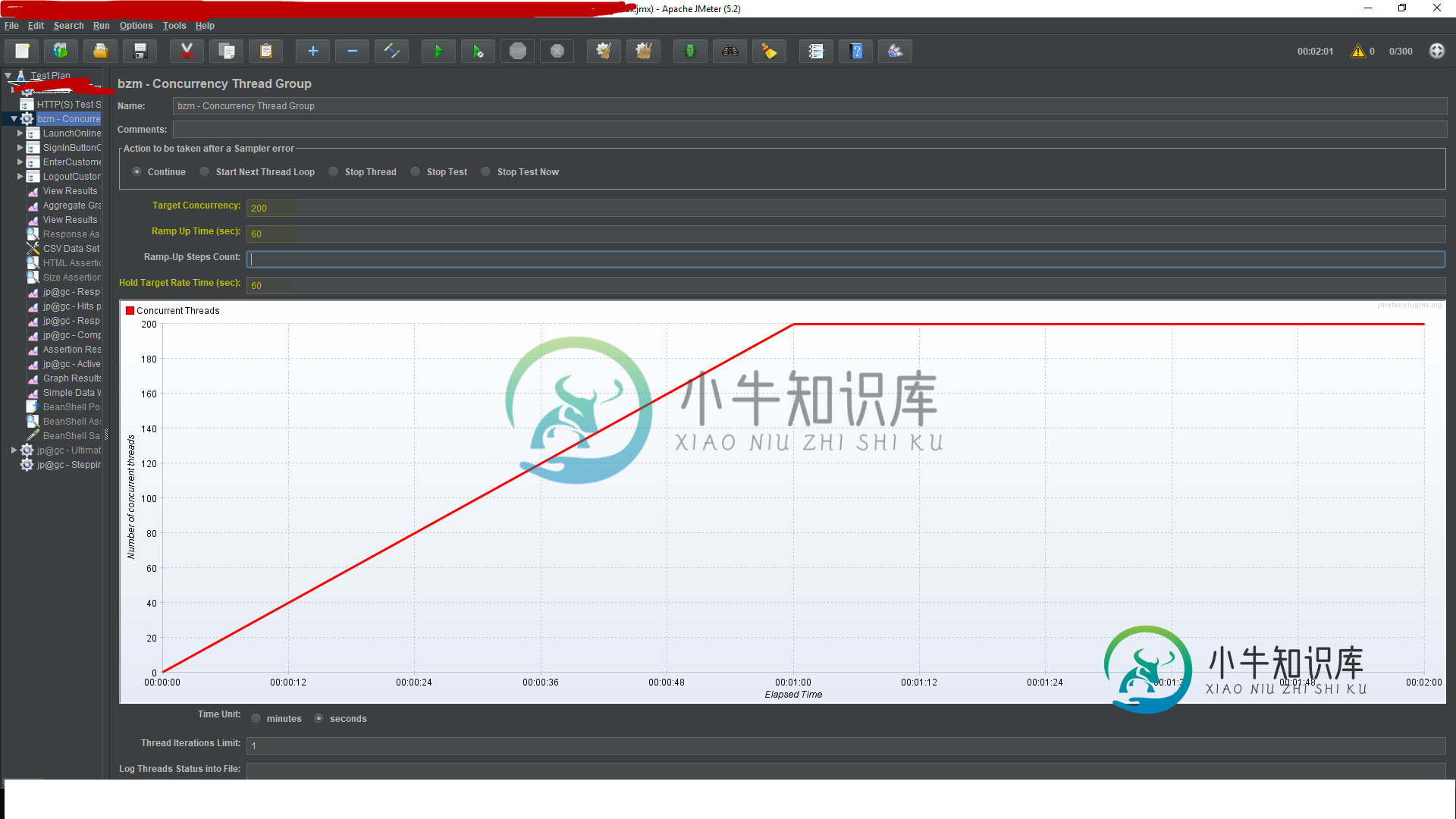 并发线程和最终线程组及性能基准标记
并发线程和最终线程组及性能基准标记在理解并发线程和最终线程组的概念时,我对运行并发线程或最终线程组时的汇总/聚合报告结果的理解感到困惑,例如,如果我有200个用户,上升时间为60秒,那么在成功完成执行后,我并没有看到所有的采样请求都是200个样本,而只有少数采样请求有200个样本。当我使用普通线程组时,每次采样请求完成后,我总是得到相同的线程数。 对于更多用户的实际负载测试,您能否建议我应该选择哪一个线程组。 您是否可以提供一些有
-
用多线程和通道发布时,线程都被阻塞,rabbitmq
我在我产品环境中发现了一个问题。 我们在一个mq集群中有6个队列,我们有200个线程的线程池(实际上会更多,因为它会在一个独立的线程池中安排一些特殊任务)来处理来自上游的请求,当处理请求时,我会发布一个消息给rabbitmq Broker。 所以我有200个线程将消息发布到这6个队列。 对于每个队列,我将创建一个AMQP连接,对于每个线程,我有一个Channel的threadlocal,这样每个线