《集群化》专题
-
对于水平扩展的分布式系统,Ppub / Sub中的Redis群集与ZeroMQ
问题内容: 如果我要设计一个庞大的分布式系统,其吞吐量应与系统中的用户数和通道数成线性比例,哪个更好? 1) Redis群集 (仅适用于Redis 3.0 alpha,如果它处于群集模式,则可以在一个节点上发布并在另一个完全不同的节点上订阅,消息将传播并到达您)。发布的复杂度为 O(N + M) ,其中N是已订阅客户端的数量,M是系统中已订阅模式的数量,但是在Redis集群中,它如何扩展?我接受对
-
是否有任何Redis客户端(首选Java)支持Redis集群上的事务?
问题内容: 我集中精力查看在线,但是找不到提供此功能的成熟Redis客户端。只发现了这个项目。任何人都知道Redis客户提供上述内容吗?谢谢。 问题答案: Redis集群中的事务与Redis Standalone的事务不同。 与客户问题相比,这更多是关于担保和权衡的概念性问题。 说明 在Redis群集中,特定节点是一个或多个哈希槽的主节点,这是在多个节点之间分片数据的分区方案。根据命令中使用的键计
-
Java对应用程序进行网格/集群启用的最佳库是什么?
问题内容: 这种功能可以在服务器群集上运行应用程序,以分配负载并提供额外的冗余。 我看过GridGain的演示文稿,对此印象深刻。 认识其他人吗? 问题答案: 有几个: Terracotta(开源,基于Mozilla Public License); Oracle Coherence(以前是Tangosol Coherence;商业;基于JSR 107,从未正式采用); GigaSpaces(商业
-
在Amazon EC2上运行的Elasticsearch集群是否需要使用负载均衡器?
问题内容: 我对我的Elasticsearch集群如何处理流量感到有些困惑。我在群集中连接了多个EC2实例。现在,在我的应用程序中,我将其设置为通过实例之一的ip连接到集群。我知道此节点随后可以与集群中的所有其他节点连接并进行适当的转发,但是由于所有流量最初都定向到该节点时,该特定实例是否不会变得过重?我必须先使用负载均衡器,然后将应用程序指向该负载均衡器,还是我不能正确理解这一点? 谢谢!:)
-
使用VPN在不同网络中运行节点的混合/异构Kubernetes集群
我的目标是建立一个混合/异构Kubernetes集群的模型,其中我有以下设置: 主节点在AWS(cloud)-IP-172-31-28-6上运行 从节点在我的笔记本电脑上运行-osbox 从节点运行在Raspberry pi-edge-1上 在我的笔记本电脑上本地运行一个有三个VM的Kubernetes集群是没有问题的,并且与两个Weave Net都能很好地工作。然而,在对上面描述的Kuberne
-
如何使用Apache Spark kmeans对SIFT描述符进行集群(是否通过pickle)
酸洗是传输描述符数据的最佳方式 如何从一组pickle文件到一个集群就绪的数据集,以及应该注意哪些陷阱(Sark、pickling、SIFT) 我感兴趣的是假设描述符生成代码和集群环境之间有一些公共存储,python 2代码的序列会是什么样子
-
OpenShift 中 3 个代理集群中 Kafka 代理的常规网络连接故障
由于未知的原因,在生产和测试中通常每周几次,我们无法与 Kafka 代理通信,并且此消息在日志中重复出现:无法建立与节点 nnnn 的警告连接。经纪人可能不可用。(org.apache.kafka.clients.NetworkClient) 奇怪的是,这反过来又阻止了Kafka的工作(我们不能生产/消费)。 OpenShift没有意识到它不起作用,Kafka也没有识别它。 如果没有执行Broke
-
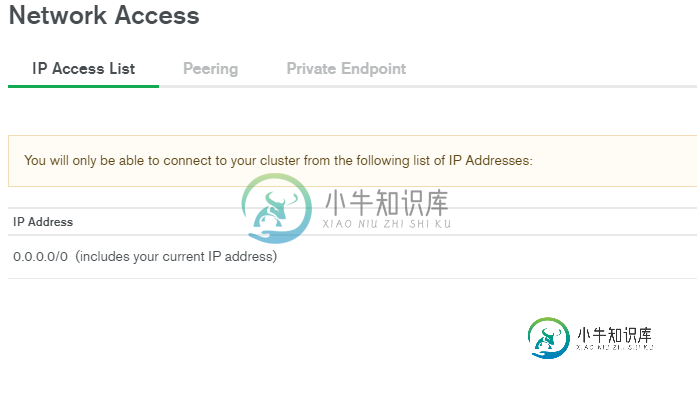 MongooseServerSelectionError:使用Minikube时无法连接到MongoDB Atlas集群中的任何服务器
MongooseServerSelectionError:使用Minikube时无法连接到MongoDB Atlas集群中的任何服务器我使用node创建了一个RESTAPI,并使用Kubernetes和Docker对其进行了容器化。出于开发目的,kubernetes吊舱在minikube环境中运行。 该应用程序运行良好,现在给出了以下错误。 该问题似乎是MongoDB连接URL/Access问题,但连接字符串是正确的。(使用MongoDB Cloud支持仔细检查)。每个人都有相关的网络访问权限 我还可以确认可以使用相同的连接UR
-
Kubenetes:在Kubernetes集群中是否可以通过单个请求击中多个Pod
问题内容: 我想清除Kubernetes命名空间中所有Pod中的缓存。我想向端点发送一个请求,然后该端点将向命名空间中的所有Pod发送HTTP调用以清除缓存。目前,我只能使用Kubernetes击中一个吊舱,我无法控制哪个吊舱会被击中。 即使负载均衡器设置为RR,连续击中Pod(n次,其中n是Pod的总数)也无济于事,因为其他一些请求可能会不断蔓延。 这里讨论了相同的问题,但是我找不到实现的解决方
-
如何在Terraform中使用secret manager创建Aurora无服务器数据库集群
我一直在读这一页:https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/rds_cluster 这里的示例主要针对已配置的数据库,我是无服务器数据库的新手,是否有使用存储在secret manager中的机密创建无服务器Aurora数据库集群(SQL db)的Terraform示例? 非常感谢。
-
Quartz调度器在集群模式下的所有节点上触发cron作业
我有一个应用程序,使用Quartz作为作业调度程序。有两种情况 null > 应用程序的两个实例都将启动并连接到数据库。两者都报告它们已成功群集并连接到数据库。 当我根据场景1调度作业时,在作业执行时,只有一个应用程序执行作业。 场景2,即每10秒执行一次的cron作业,由两个应用程序同时执行。 任何帮助或指导将非常感谢!
-
MongoDB搭建高可用集群的完整步骤(3个分片+3个副本)
本文向大家介绍MongoDB搭建高可用集群的完整步骤(3个分片+3个副本),包括了MongoDB搭建高可用集群的完整步骤(3个分片+3个副本)的使用技巧和注意事项,需要的朋友参考一下 配置脚本以及目录下载:点我下载 一、规划好端口ip 架构图如下,任意抽取每个副本集中的一个分片(非仲裁节点)可以组成一份完整的数据。 1. 第一个副本集rs1 2. 第二个副本集rs2
-
Apache Camel使用数据库在集群中运行的路由的单个实例
我在两台服务器上部署了Apache Camel应用程序,它们使用JMSendpoint。我想确保一次只使用一条来自jmsendpoint的驼峰路由。我可以用于集群的唯一选项是使用数据库作为锁存储。Apache Camel是否提供了这样的功能?
-
kubectl错误访问EKS群集时必须登录到服务器(未经授权
我一直在努力遵循EKS入门指南。当我尝试调用kubectl get service时,我得到的消息是:错误:您必须登录到服务器(未经授权),这是我做的: 1。创建了EKS集群。 2。创建了配置文件,如下所示:
-
 无法在Istio代理背后的k8s中建立到VerneMQ群集的mqtt连接
无法在Istio代理背后的k8s中建立到VerneMQ群集的mqtt连接我正在设置k8s上的Prem k8s集群。对于测试,我在使用Kubeadm设置的vm上使用单节点集群。我的需求包括在k8s中运行MQTT集群(vernemq)并通过Ingress(istio)进行外部访问。 在不部署ingress的情况下,我可以通过NodePort或LoadBalancer服务连接(mosquitto_sub)。 Istio是使用安装的 null 在命名空间中,我使用LoadBa