《一致性哈希》专题
-
多个线程一次更新数据库中的同一行如何保持一致性
问题内容: 在我的Java应用程序中,多个线程一次更新同一行如何获得一致性结果? 例如 问题答案: 有两种可能的方法。 您要么选择悲观方法,要么锁定行,表甚至行范围。 或者您使用版本化的实体(乐观锁定)。 也许您可以在这里找到更多信息: https://docs.jboss.org/hibernate/orm/3.3/reference/en/html/transactions.html
-
1.3.9 如何保证缓存与数据库的双写一致性?
面试题 如何保证缓存与数据库的双写一致性? 面试官心理分析 你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题? 面试题剖析 一般来说,如果允许缓存可以稍微的跟数据库偶尔有不一致的情况,也就是说如果你的系统不是严格要求 “缓存+数据库” 必须保持一致性的话,最好不要做这个方案,即:读请求和写请求串行化,串到一个内存队列里去。 串行
-
带有锁定的Postgresql的一致性,并选择进行更新
问题内容: 我有一个可以支持一定数量的并发操作的应用程序。这由postgres中的“插槽”表表示。当节点联机时,它们会在表中插入许多行,每个插槽一个。当作业声明插槽时,它们会更新表中声明其中一个插槽的行,并在完成时再次释放它。 插槽表如下所示: 在任何时候,它都有一些固定的行数,每行可以或可以不填写job_name。 当新作业要启动时,它将运行以下查询以获取应在其上运行的节点的名称: (从游标中读
-
使用Kafka作为EventStore时恢复Flink中的状态一致性
我将微服务实现为事件源聚合,而事件源聚合又被实现为Flink FlatMapFunction。在基本设置中,聚合从两个kafka主题读取事件和命令。然后,它将新事件写入第一个主题并处理第三个主题的结果。因此,Kafka充当事件存储。希望这张图能有所帮助: 由于Kafka没有选中点,因此命令可能会被重放两次,而且输出事件似乎也可以在主题中写入两次。 在重复消息的情况下如何恢复状态?聚合是否可以知道其
-
谷歌应用引擎数据存储:处理最终一致性
我正在开发一个GAE web应用程序,我需要在没有祖先关系的两个实体的实例之间创建和删除关联(还要考虑同一个实例可能有多个关联,这些关联可能随时间变化,而祖先关系一旦创建,就无法删除)。我经历过“最终一致性”策略,这意味着我的网页中的数据不能与我正在创建/删除的关系一致地刷新。然而,我已经看到,通过两次执行put()方法,一致性似乎是强制的。 这符合“最终一致性”定义,该定义规定“…如果没有进行新
-
Object tify中的多对多关系具有很强的一致性
作为谷歌云数据存储的新手,我希望确保自己走上了正确的轨道。 我需要什么: 多对多关系 这是我想出的: 如果我对这个实现的理解正确,那么过滤特定用户的数据实体的唯一方法就是在内存中获取所有权限实体和过滤数据实体,对吗? 有没有更好的方法来实现它仍然满足要求? 更新时间: 在我的理解中,这个实现将允许我实现检索数据的逻辑,以确保强一致性(使用用户id-祖先查询来检索所有权限实体,然后使用get_by_
-
Datastax cassandra对象映射器设置一致性,如果不存在
我创建了用注释的实体,它类似于我的cassandra表。我可以做保存,得到和一切没有太大的问题。 是否有更好的方法动态设置对象映射器操作与访问器和实体的一致性级别? 如果映射对象不存在,如何保存?
-
使用Jackson流API反序列化对象时的不一致性
我正在尝试使用Jackson流API从XML反序列化巨大的对象。其思想是结合流式API和ObjectMapper来按小块解析XML(或JSON)。但是,我看到了一些与XML解析器不一致的行为。使用以下代码段: null 为什么XML1缺少FIELD_NAME标记?为什么第二个XML只有一个START_OBJECT令牌?是否有任何设置可以让我看到外部标记的FIELD_NAME?
-
 微服务注册中心如何保证数据强一致性?
微服务注册中心如何保证数据强一致性?主要内容:1、再回顾:什么是服务注册中心?,2、Consul服务注册中心的整体架构,3、Consul如何通过Raft协议实现强一致性?,4、Consul如何通过Agent实现分布式健康检查?1、再回顾:什么是服务注册中心? 先回顾一下什么叫做服务注册中心? 顾名思义,假设你有一个分布式系统,里面包含了多个服务,部署在不同的机器上,然后这些不同机器上的服务之间要互相调用。 举个现实点的例子吧,比如电商系统里的订单服务需要调用库存服务,如下图所示。 现在的问题在于,订单服务在192.168.31.1
-
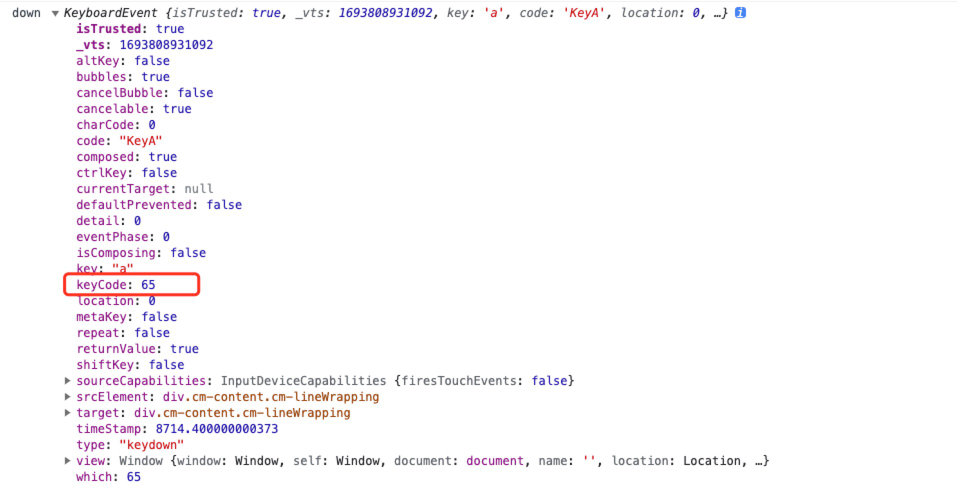 前端 keydown 和 keyup 返回的事件对象属性不一致?
前端 keydown 和 keyup 返回的事件对象属性不一致?遇到了 keyup 和 keydown 区别的问题,于是自己简单在控制台输出了一个小写字母 a。 这是 keydown 的输出打印。 这是 keypress 的打印。 为什么这两个事件对象返回字母 a 的 keyCode 编码竟然不一致?
-
Java MD5哈希与C#MD5哈希不匹配
问题内容: 我对加密/哈希知之甚少。 我必须对加密密钥进行哈希处理。Java中的示例是这样的… 现在,如果我错了,请纠正我,但是上面的代码使用MD5算法对字符串进行了哈希处理。 当我在C#中哈希相同的字符串时,我希望得到相同的结果。 我当前的C#代码看起来像这样… 但是末字节结果不匹配。 Java得到… C#得到… 我需要C#代码才能获得与Java代码相同的结果(不是相反),有什么想法吗? 谢谢。
-
列表不可哈希,但元组可哈希?
问题内容: 在如何哈希列表?有人告诉我,我应该转换为一个元组第一,如到。 因此,第一个不能散列,而第二个可以散列。为什么*? *我并不是真正地在寻求详细的技术说明,而是在寻找一种直觉 问题答案: 主要是因为元组是不可变的。承担以下工作: 现在,当您这样做时会发生什么?您已修改字典中的键!远道而来!如果您熟悉哈希算法的工作原理,这会让您感到恐惧。另一方面,元组是绝对不变的。看起来好像是在修改元组,但
-
将Java哈希码合并为“主”哈希码
问题内容: 我有一个实现了hashCode()的向量类。它不是我写的,而是使用2个质数对2个向量分量进行异或运算。这里是: …因为这是来自已建立的Java库,所以我知道它可以正常工作。 然后,我有一个Boundary类,其中包含2个向量:“开始”和“结束”(代表直线的端点)。这两个向量的值是边界的特征。 在这里,我尝试为构成该边界的向量的唯一2元组(起点和终点)创建一个良好的hashCode()。
-
当哈希图的值相同时,如何根据键对象的属性对哈希图进行排序?
我有一个HashMap,其中类的对象(对象1,对象2,对象3)作为键,java.util.Date(日期1,日期2,日期3)作为值。HashMap已经根据值进行了排序,即基于日期对象。键对象具有名为name的属性。 现在,当HashMap的值相同时,即当值的日期相同时,我需要检查键对象的名称(obj.name),并根据键对象的名称属性对HashMap进行排序。请注意,只有当HasHMap和值的日期
-
如何将一个哈希映射列表中的不同值添加到另一个哈希映射列表中
有人能帮我找到一份没有重复的正确清单吗。 我有一个哈希映射列表,比如“HashMap map”,它的大小是4。键值对类似于以下内容 我想创建另一个Hashmap列表,其中包含“uri\u path”的单个条目以及相应计算的平均值和计数。这就是我正在尝试的。理想情况下,新列表的大小应小于原始列表的大小。有人能帮我理解是不是出了问题