《限流》专题
-
log4j将Appender限制到特定级别
下面是我使用的一些代码: 如何只打印信息日志?
-
Hibernate-JPA中的无限递归[重复]
我得到了错误下的无限递归。 下面是我的代码 另一个班 我无法理解为什么在UI上获取此值时会出现此错误。
-
pyspark java。lang.OutOfMemoryError:超出GC开销限制
我试图用火花处理10GB的数据,它给了我这个错误, Java语言lang.OutOfMemoryError:超出GC开销限制 笔记本电脑配置为:4CPU,8个逻辑内核,8GB RAM 提交Spark作业时进行Spark配置。 在网上搜索了这个错误后,我有几个问题 如果回答,那将是一个很大的帮助。 1) Spark是内存计算引擎,用于处理10 gb的数据,系统应具有10 gb的RAM。Spark将1
-
限制分页中的可见页数
我正在开发一个jQuery分页工具,当我让分页工作时,我看到了一个缺陷: 在桌面上有一行14个分页链接是可以的,但在移动设备上是不行的。因此,我想将一次可见页面的数量限制为5个(不包括next/prev按钮),并在到达第三个可见页面时进行更新,并更新分页中的可见页面 到目前为止,我已经编写了这个CodePen。我知道有插件可以为我做这件事,但我想避免在这个项目中使用插件。 HTML(正在分页的示例
-
扫描仪类的hasNext()无限循环
我正在尝试编写使用Scanner类从用户那里获取输入的代码。但是hasNext()、hasNextInt()和hasNextLine()每次都会运行无限循环。
-
长溢出,即使未超过限制
我有一段代码,我将byte、short和int设置为它们的最大值,然后将它们的总和乘以10,再加上50000。我在计算器上计算出这应该是允许的,因为结果小于long的最大值,但它给了我一个奇怪的输出。 输出:预期输出:
-
java.io.FileNotFoundException:/sdcard/testwrite.txt:open失败:EACCES(拒绝权限)
-
Symfony 3登录表单无限循环
我的Symfony版本是:3.0.6 我从几个小时与认证战斗。我有登录表格 我的security.yml看起来: 若数据库中不存在用户名,表单可以显示给我。但如果我输入了一些密码(也错了),我在“check_path”URL上有无限循环。 登录表单上的字段正确:\用户名和\密码。表单“action”与安全中的“check_path”相同。 我做错了什么...这是非常奇怪的,因为所有是像在教程。 控
-
Python递归限制与堆栈大小?
我明白了在递归中,每个递归调用是如何堆栈在堆栈上的;如果超过堆栈限制,则会出现堆栈溢出。那么为什么Python的返回一个数字;递归调用的最大深度? 这不是取决于我在递归函数中做了什么吗?还是以某种方式将变量保存在堆栈以外的其他地方?它是如何工作的?
-
硬币兑换的复杂性有限
如果每枚硬币的数量是无限的,那么复杂性是O(n*m),其中是总变化,是硬币类型的数量。现在,当每种类型的硬币都受到限制时,我们必须考虑剩余的硬币。我设法使它与的复杂性使用另一个大小的,所以我可以跟踪每个类型的剩余硬币。有没有一种方法可以让复杂性变得更好?编辑:问题是计算进行精确给定更改所需的最少硬币数量以及我们使用每种硬币类型的次数
-
Apache Shiro角色和权限不工作
我正在使用Apache Shiro(v1.2.3),我正确地设置了用户名/密码身份验证,并且它正在工作(我将密码散列和salt存储在远程数据库中)。我现在正在尝试使用角色设置权限。我有一个扩展的领域,例如。 我的如下所示: credentialsMatcher=org.apache.shiro.authc.Credential.sha256CredentialsMatcher credential
-
Kotlin-无限但可取消定时器
目前有这种方法 但是我怎么能有一个重复的执行与以下要求。 不递归。 无限时间/执行,但可以使用其公共方法取消。
-
限制炫耀文档的可见性
运行api服务后,我的swagger文档位于localhost: port/docs。这将显示我所有的api。无论如何,是否只显示某些api或某些标签下的api? 也许某个标签下的所有api都有不同的文档url? 我正在用快递运行它。
-
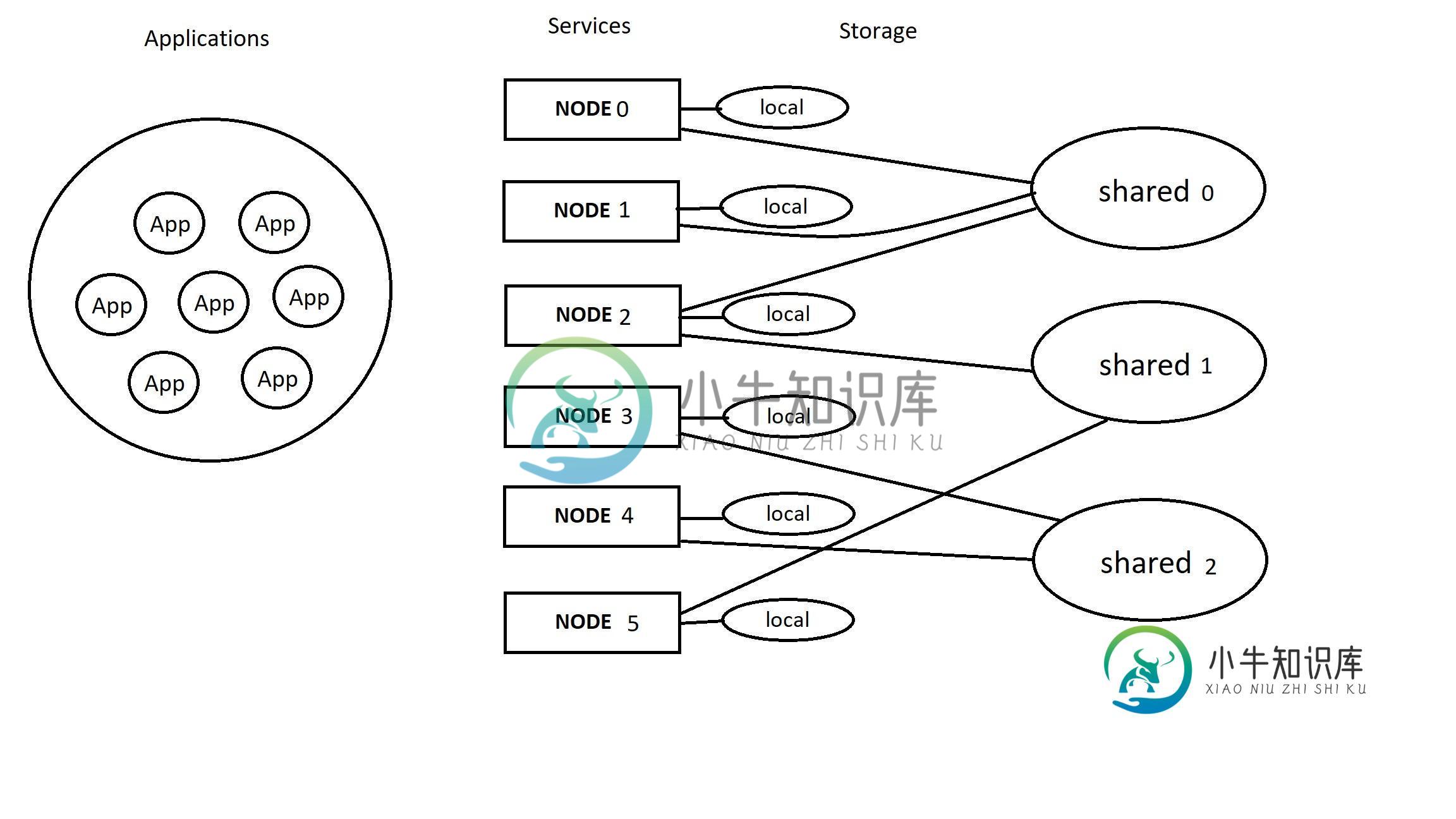 具有限制的再平衡算法
具有限制的再平衡算法请帮助解决以下问题。 给出了以下实体: < li >应用。应用程序驻留在存储上,它们通过服务节点产生流量。 < li >服务。服务分为几个节点。每个节点都可以访问本地或/和共享存储。 < li >存储。这是应用程序驻留的地方。它可以是本地的(仅连接到一个服务节点),也可以由几个节点共享。 规则: 每个应用程序都放置在某个特定的存储上。并且不能改变存储 只要新的服务节点可以访问应用程序的存储,应用程
-
如何在Java中无限期等待?
有没有更好的写法呢?由于某种原因,我真的需要这个循环吗?(似乎与有关)