《分库分表》专题
-
确认MSVC 2015 RC中与分配器相关的标准库Bug
下面是一个SSCCE: GCC喜欢它。 ICC喜欢它。 Clang喜欢它。 甚至MSVC2013也喜欢它。 但是MSVC2015 RC吐槽: 相关程序给出了类似的可疑的听起来错误。下面有两个: 错误C2664:“void std::_wrap_alloc>::deallocate(int*,unsigned int)':无法将参数1从”std::_container_proxy*“转换为”int*
-
从Firebase数据库节点读取部分数据(不是全部)
我正在处理需要以这种方式读取 firebase 节点的项目: 假设我在Firebase实时数据库中有一个节点。在该节点中,我有消息。当用户在消息框中输入时,我需要显示消息。但是一次阅读所有消息太耗时了。 我想要的是,一次读取消息并将其显示给用户。当用户按下按钮时,我会读取另一个消息并将其显示给用户。依此类推……会更快更方便。 但是我找不到任何方法让事情像这样工作。我尝试了,但是它读取了节点中的所有
-
Neo4j图形数据库中复杂匹配评分时的性能?
我有Neo4J3.3.5图形数据库:27GB,50KK节点,500KK关系。索引打开。模式。个人电脑:16GB内存,4个核心。 由于缺少后联合处理,我使用+来合并所有关系的分数。 不幸的是,性能较低。我在5-10秒内得到一个关系(如上)查询的响应。当我试图将结果与+组合时,查询“never”结束。 做这件事的更好/正确的方法是什么?也许我在图形设计上做错了什么?硬件配置到低?或者也许有一些算法可以
-
go 有没有能持久化的分布式定时任务库?
写了个基于kratos的服务,基本需求是:可以增删管理定时任务(如配置每天、每周发个统计报告),支持分布式结构,持久化任务。加分项包括:注册回调、结果和日志记录、失败重试等。 看kratos已经支持的transport有两个:asynq和machinery,但似乎都不满足需要基本的持久化任务需求,machinery甚至还不能删除已经添加的任务。 考虑到服务可能会重启,那么添加过的任务如何恢复呢?如
-
第三部分:Ceph 进阶 - 5. 清空 OSD 的分区表后如何恢复
本篇内容来自 zphj1987 —— 不小心清空了 Ceph 的 OSD 的分区表如何恢复 假设不小心对 Ceph OSD 执行了 ceph-deploy disk zap 这个操作,那么该 OSD 对应磁盘的分区表就丢失了。本文讲述了在这种情况下如何进行恢复。 破坏环境 我们现在有一个正常的集群,假设用的是默认的分区的方式,我们先来看看默认的分区方式是怎样的。 1、查看默认的分区方式。 root
-
如何将一个列表随机分为n个几乎相等的部分?
问题内容: 我已经阅读了[将列表切成n个几乎相等长度的分区重复问题的答案。 这是公认的答案: 我想知道,如何修改这些解决方案,以便将项目随机分配给分区而不是增量分配。 问题答案: 对列表进行分区之前先对其进行调用。
-
通过将分号分隔开来从单个查询中删除多个表
问题内容: 我试图从sqlite的单个操作中删除多个表。我尝试用分号分隔它,但没有按预期进行。这是我当前的代码: 我需要一些指导,以解决问题可能出在哪里,或者如果我缺少什么。 问题答案: 要使用多个语句进行原子操作,请使用事务: 如果使用sqlite3_prepare_v2,则必须一个接一个地执行这五个命令。使用sqlite3_exec,您可以一次调用执行它们(但不支持SQL参数)。
-
配置单元:如何将数据从分区表插入到分区表中?
查询示例: 典型错误消息: 处理语句时出错:失败:执行错误,从org.apache.hadoop.hive.ql.exec.mr.MapredTask返回代码2 问题2:当我运行命令?我是否只运行相同的命令,但使用STRING而不是bigint?**完整错误消息:**
-
在四分之一小时内每30分钟使用一次Cron表达式?
我目前正在尝试生成一个cron表达式,它在一天中每30分钟运行一次,但是在10:15, 10:45, 11:15等时间。我知道cron表达式每30分钟运行一次,但是它在10:00, 10:30, 11:00, 11:30等时间运行。我想知道是否有办法创建一个cron表达式,它可以在9:15, 9:45, 10:15, 10:45等时间运行,比如在四分之一小时内运行?
-
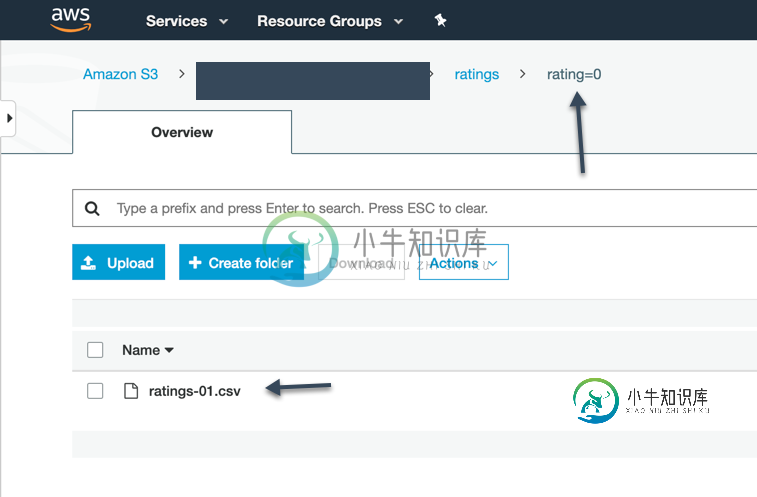 Apache Spark未使用配置单元分区外部表中的分区信息
Apache Spark未使用配置单元分区外部表中的分区信息我有一个简单的配置单元-外部表,它是在S3的顶部创建的(文件是CSV格式的)。当我运行配置单元查询时,它会显示所有记录和分区。 但是,当我在Spark中使用相同的表时(Spark SQL在分区列上有where条件),它并没有显示应用了分区筛选器。然而,对于配置单元托管表,Spark能够使用分区信息并应用分区筛选器。 是否有任何标志或设置可以帮助我利用Spark中Hive外部表的分区?谢了。
-
配置单元分区表读取所有分区,尽管有Spark过滤器
但是我得到了这个错误: sparkException:由于阶段失败而中止作业:阶段0.0中的任务236失败4次,最近的失败:阶段0.0中丢失任务236.3(TID 287,server,executor 17):org.apache.hadoop.security.AccessControlException:权限被拒绝:user=user,access=read,inode=“/path-to-
-
根据子字符串分隔符拆分字符串,将分隔符保留在结果中
我希望能够根据子字符串分隔符拆分字符串,在分隔符子字符串的第一个字符之前开始拆分。现在: 将给我,但我希望得到
-
集中式网络,分散式网络和分布式分类帐之间有什么区别?
本文向大家介绍集中式网络,分散式网络和分布式分类帐之间有什么区别?相关面试题,主要包含被问及集中式网络,分散式网络和分布式分类帐之间有什么区别?时的应答技巧和注意事项,需要的朋友参考一下 回答: 分布式分类帐:这是共享分类帐,不受任何中央机构的控制。它本质上是分散的,并充当金融,法律或电子资产的数据库。 集中式网络:集中式网络具有中央机构以方便其操作。 分散网络:分散网络中连接的节点不依赖于单个服
-
Kafka自定义分区-每个分区用户数据自定义的使用者分配器
我正在实现一个自定义消费者的主题/分区分配在Kafka。为此,我将重写抽象类,该类又实现接口。 作为自定义赋值器的一部分,我希望发送一个关于消费者订阅的每个主题的每个分区的单个(浮动)信息。 我知道可以通过重写接口的默认方法向赋值器发送自定义数据。 但是,问题是,从上面的方法签名中,我无法获得为使用者注册的每个主题分配给带下划线使用者的分区列表。 谢谢你。
-
如何在Java中将URL分解为其组成部分?
问题内容: 我的要求很简单,但是我需要做很多事情,因此我正在寻找可靠的解决方案。 是否有一个很好的轻量级库,用于将URL分解为Java中的组成部分?我指的是主机名,查询字符串等。 问题答案: 看一看java.net.URL。它具有完全符合您要执行的操作的方法。 主机名: 查询字符串: Fragment / ref / anchor: 路径: