《分库分表》专题
-
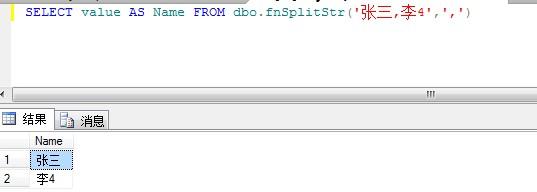 SQL server中字符串逗号分隔函数分享
SQL server中字符串逗号分隔函数分享本文向大家介绍SQL server中字符串逗号分隔函数分享,包括了SQL server中字符串逗号分隔函数分享的使用技巧和注意事项,需要的朋友参考一下 继SQl -Function创建函数数据库输出的结果用逗号隔开,在开发中也有许多以参数的形式传入带逗号字条串参数(数据大时不建议这样做) 例:查找姓名为“张三,李二” 的数据此时在数据库里就要对此参数做处理如图: 函数代码如下 好了,关于sql字符
-
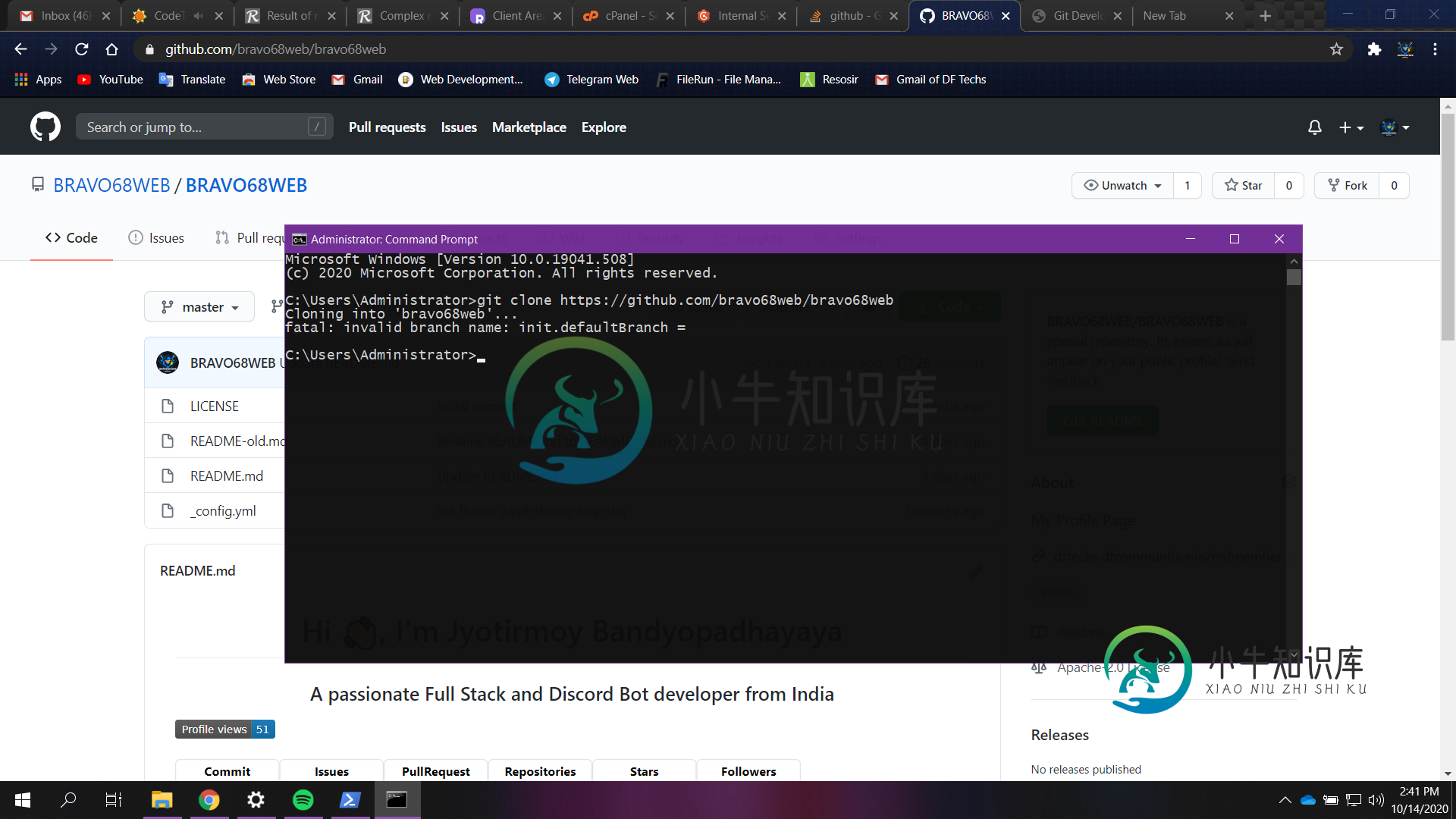 Git错误"致命:无效分支名称:init.default分支="
Git错误"致命:无效分支名称:init.default分支="我在进行git克隆时遇到此错误 错误:- 尝试重新安装git(最新) 还是相同的错误 操作系统:-Windows
-
如何用可视化分析器分析PyCuda代码?
问题内容: 当我创建一个新会话并告诉可视化分析器启动 python/pycuda脚本我得到以下错误消息: 以下是我的偏好: 启动: 工作目录: 参数: 我在ubuntu10.10下使用cuda4.0。64位。分析编译的示例是有效的。 p、 我知道这个问题[如何在 Linux系统?](https://stackoverflow.com/questions/5317691/how-to-profile
-
将没有分隔符的字符串拆分为列
问题内容: 我需要在SQL Server 2012中将一列中的字符串拆分为一个字符,并将每个字符串拆分成它自己的列。 例如:如果我有一个栏,我需要把它拆分成,,,,,与每个这些转化为自己列。 要拆分的列的长度可能会有所不同,因此我需要使其尽可能地动态。 问题答案: 您可以这样做: 输出: 这是动态版本:
-
在java、int和String中拆分逗号分隔的值
我在文本文件中有以下内容要导入ArrayList: 澳大利亚,2 加纳,4 中国,3 西班牙,1 我的ArrayList由来自另一个类Team的对象组成,该类具有TeamName和排名字段。我可以获取以下内容以将String和int导入团队名称,但我无法分离应该是团队排名的数字: 我猜我必须在该行的某个地方使用拆分,或者将字符串转换为整数??
-
无法切换回当前分支之前的分支
我在一个分支“测试”中工作,并进行了拉操作,现在我按照原点进行更新。 我签出分支“开发”,它位于源/开发后面,我复制了一些代码更改。现在我运行: 当我在分支“测试”中工作时,我得到了许多未跟踪的文件,而不是暂存的文件。现在我只想签回测试分支并推动我的更改。我的更改很少,所以我可以还原并重做它们。但如何切换分支,因为我遇到了错误: 错误:签出将覆盖以下未跟踪的工作树文件: 所有未标记和未跟踪的文件
-
解压缩分为几个部分的GZIP http请求
我正在做一个http代理,在解压响应时遇到了一个问题,这些响应是在客户端向服务器发出请求后从服务器发出的。 E、 g.客户端发送gethttps://stackoverflow.com/questions/some_question . 服务器分几个部分发送响应。我使用以下方法对响应部分进行解压缩。 在回应的第一部分 在某种程度上,我得到了comjava。io。EOFException:ZLIB输
-
Jenkins多分支作业对于某些分支失败
我有一份Jenkins Multi-branch的工作,从GitLab签出并构建代码。直到最近,它还可以正常工作,但现在一些(但不是全部)来自优秀大师的分支无法构建。大师总是建造没有问题。当我从GitLab中的repo或通过git checkout-b本地分支master并推回到GitLab,然后允许多分支作业拾取新分支时,它无法构建它。我从管道插件SCMBinder类得到消息:“无法确定[bra
-
合并到主分支后自动删除 git 分支
我们将尝试在github中创建一个工作流,其中每个票据都是master的分支 票据完成后,工作将合并到暂存中,在暂存中执行回归和集成测试,然后将其合并到主控中。 一个团队领导提出了合并后旧票分支的问题。 我发现了这个脚本,想知道它是否能在我们的环境中工作。我们只想删除已经合并到主目录中的分支。
-
积分流中的反应Spring积分接入通量
我已经看到了在中间访问通量的问题,我想知道为什么我用以下方式成功地在通量中编写逻辑: 首先,我想知道为什么我从未将错误抛出控制台,但在调试时我看到了错误。我还想知道这是如何工作的,为什么我需要变量(它总是产生,即使流可以继续并正常工作)。当我省略
-
如何在java中用'~~'分隔符拆分字符串?
我有输入字符串'~~'作为分隔符。 例如:字符串s=“1~~vijay~~25~~pune”;当我在Java中用'~\\~'拆分它时,它工作得很好。 还有其他人面临同样的问题吗?请就这个问题发表评论。
-
在拆分字符串函数中查找分隔符
我想在拆分函数调用中使用空格作为分隔符,但我想在单个单元格数组中输入某些单词;例如。 例如: 在带有一些分隔符的函数拆分调用之后,输出应如下所示: 我需要找到一个分隔符(或正则表达式模式)用于split函数。我如何着手做那件事?
-
Spark重新分区创建的分区超过128 MB
假设我有一个1.2 GB的文件,那么考虑到128 MB的块大小,它将创建10个分区。现在,如果我将其重新分区(或合并)为4个分区,这意味着每个分区肯定会超过128 MB。在这种情况下,每个分区必须容纳320 MB的数据,但块大小是128 MB。我有点糊涂了。这怎么可能?我们如何创建一个大于块大小的分区?
-
数据框架-连接/分组依据-聚集-分区
我可能对加入/组By-agg有一个天真的问题。在RDD的日子里,每当我想执行a. groupBy-agg时,我曾经说reduceByKey(PairRDDFunctions)带有可选的分区策略(带有分区数或分区程序)b.join(PairRDDFunctions)及其变体,我曾经有一种方法可以提供分区数量 在DataFrame中,如何指定此操作期间的分区数?我可以在事后使用repartition(
-
Itext:使用条形码分隔符拆分pdf文档
我面临以下用例: 我收到一个包含许多文档的pdf。每个文档具有不同的页数。它们由条形码页分隔。 是否可以拆分包含多个文档的多页PDF,这些文档由带有条形码的页面分隔,并为每个文档创建一个新的PDF? 我听说我们可以用Itext:https://developers.itextpdf.com/examples/stamping-content-existing-pdfs/clone-splittin