《均衡》专题
-
有没有一种方法来衡量一个列表的排序情况?
我的意思是,这不是要知道列表是否排序(布尔值),而是像“排序”的比率,像统计学中的相关系数。 例如, > 如果列表中的项目按升序排列,则其比率为1.0
-
负载平衡地理网络Tomcat HAProxy
最近,我在一台机器上使用HAProxy配置了两个Tomcat(A和B)的集群(一切正常)。我已经在两个网络服务器上解除了Geonetwork WAR。我启动Tomcat A没有问题,但是当启动Tomcat B时,当它的“geonetwork.war”试图访问Lucen索引时出错,这是由于Tomcat A启动时write.lock生成的锁(我假设)。 错误如下: 2016-11-22 20:47:5
-
衡量C/C性能的困难
我写了一段C代码来展示关于优化和分支预测的讨论中的一个观点。然后我注意到比我预期的更多样化的结果。我的目标是用C和C之间的通用子集编写它,这两种语言都符合标准,并且相当可移植。它在不同的Windows PC上进行了测试: 用VS2010编制/英特尔酷睿2、WinXP的O2优化结果: 编辑:编译器的完整开关: /Zi/no logo/W3/WX-/O2/Oi/Oy-/GL/D " WIN32 "/D
-
“再平衡”在阿帕奇·Kafka语境中意味着什么?
我还从https://cwiki.apache.org/confluence/display/kafka/kafka+0.9+consumer+rewrite+design上看到了这段话,但我似乎无法理解它,所以如果有人能帮助我理解它,我将不胜感激: 再平衡是这样一个过程:一组使用者实例(属于同一组)协调起来,以拥有该组订阅的主题的一组互斥分区。在使用者组成功的重新平衡操作结束时,所有订阅主题的每
-
kafka是否跨实例或线程平衡分区?
假设答案是,是的,Kafka不会再平衡,那么有什么解决方案可以让Kafka在各种情况下平衡
-
关于再平衡的Kafka流重新处理旧消息
我有一个Kafka Streams应用程序,它从几个主题读取数据,连接数据并将其写入另一个主题。 每小时消耗/产生几百万条记录。每当我关闭一个代理时,应用程序就进入重新平衡状态,在重新平衡多次之后,它开始使用非常旧的消息。 注意:当Kafka Streams应用程序运行良好时,它的消费者滞后几乎为0。但再平衡之后,它的滞后从0到1000万。 这会不会是因为偏移.保留.分钟。 在这方面的任何帮助都将
-
Kafka消费者,很长时间的再平衡
我们正在运行一个3 broker Kafka 0.10.0.1集群。我们有一个java应用程序,它产生了许多消费线程,从不同的主题消费。对于每一个主题,我们都指定了不同的消费者群体。 很多时候,我看到每当这个应用程序重新启动时,一个或多个CG需要超过5分钟来接收分区分配。在此之前,这个话题的消费者不会消费任何东西。如果我去Kafka broker并运行Consumer-Groups.sh并描述特定
-
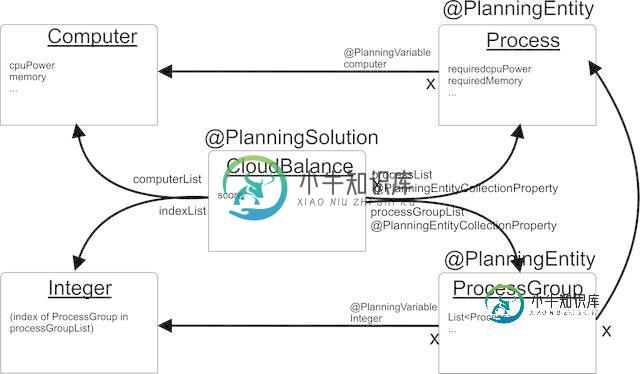 云平衡-有界空间情形下的附加规划实体
云平衡-有界空间情形下的附加规划实体我成功地修改了nice CloudBalancing示例,以包括这样一个事实:在任何给定的时间,我可能只有有限数量的计算机打开(thanx optaplanner团队--很容易做到)。我相信这被称为有界空间问题。很管用。 这些进程是按组来的,比方说每个组按给定的顺序有20个进程。我想修改示例,让optaplanner也更改这些组的顺序(而不是一个组内的进程)。因此,我在域中添加了一个类,其成员为,
-
OptaPlanner-云平衡附加硬约束
此约束是否在分数计算器()中。它是否可以检查一个解决方案中的进程组是否被分配到相同的CPU并给它打分? 有没有其他更好的方法,比如使用ValueSelector? 并且我在缺省情况下得到了一个解决方案,即使进程不能分配给CPU(因为限制)。计划者就是这样工作的吗?
-
为什么点燃集群不平衡负载?
我在3个节点上进行了压力测试,但只有一个CPU很高,其他的都很低。Ignite集群使用TCP发现,我有一个jdbc连接,例如:jdbc:Ignite:Thin://172.16.14.15、172.16.14.16、172.16.14.17/
-
spark-cassandra-connector支持内置负载平衡吗?
我有一个基于Scala的应用程序,我需要把它连接到Cassandra。我发现DataStax Enterprise驱动程序在这方面非常有用,这些驱动程序有很多很酷的特性,比如用于Cassandra的内置负载平衡,这对我来说非常重要。不幸的是,Scala没有任何本地DSE驱动程序。我知道我们可以使用DSE Java驱动程序,但在这种情况下,我们失去了很多Scala的酷特性。我还发现了由Datasta
-
负载平衡器和无服务器NEG不工作
我配置了Google Cloud load balancer和无服务器NEG来让我的app engine在静态IP中工作,但它无论如何都不起作用。下面是我用于配置的命令。 请帮我拿这个。 提前感谢!
-
带Zookeeper的负载平衡器
这意味着Zookeeper将负载均衡器理解为一个客户机,并与之建立联系。但是负载均衡器只是ping TCP2181就出来了。
-
如何在支持粘性负载平衡的Web应用程序上进行性能测试?
嗨, 我读了很多博客和教程。我不知道如何在基于cookie的粘性Web应用程序上进行性能测试,该应用程序位于反向代理负载均衡器后面。我有3个支持的应用程序服务器,为购物车的同一个实例提供服务。负载均衡器位于它们前面并引导流量。 问题:当我发送HTTP请求进行性能分析时,负载平衡器(通过cookie跟踪客户端ip)将HTTP请求重定向到分配给的同一后端服务器。我可以选择使用IP欺骗,但当后端服务器分
-
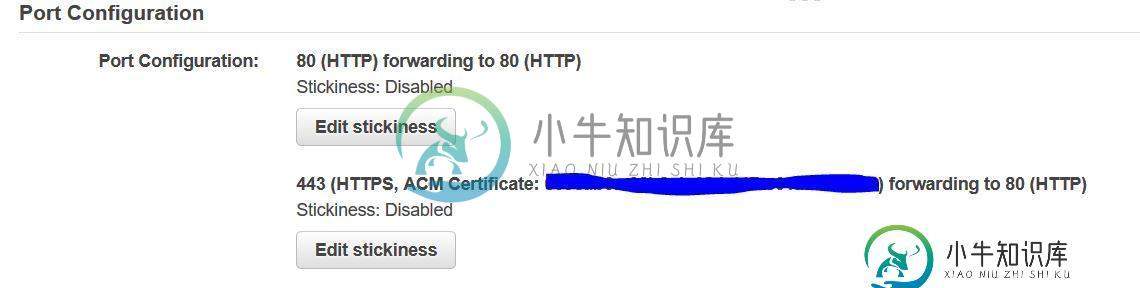 在负载平衡器后面的EC2上使用cloudfront和backend在AWS上托管前端时出现ERR_INSECURE_RESPONSE错误
在负载平衡器后面的EC2上使用cloudfront和backend在AWS上托管前端时出现ERR_INSECURE_RESPONSE错误我正在尝试使用云前端在 AWS 上托管我的前端,并在经典负载均衡器后面的 EC2 上使用后端。我已将 SSL 证书导入到 ACM 中。使用 ACM,证书已安装在云前和经典负载均衡器上。 云端配置: 经典负载平衡器配置:负载平衡器托管在api.mydomain上。com和使用ACM安装的SSL证书。 EC2正在运行一个Nodejs服务器,侦听端口80。我还没有在EC2上安装SSL证书,因为AWS文档