
云平衡-有界空间情形下的附加规划实体

我成功地修改了nice CloudBalancing示例,以包括这样一个事实:在任何给定的时间,我可能只有有限数量的计算机打开(thanx optaplanner团队--很容易做到)。我相信这被称为有界空间问题。很管用。
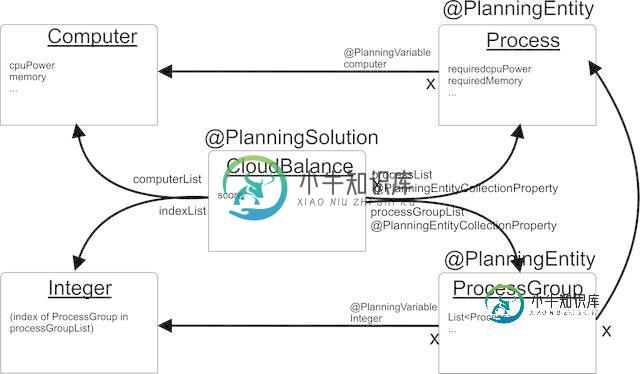
这些进程是按组来的,比方说每个组按给定的顺序有20个进程。我想修改示例,让optaplanner也更改这些组的顺序(而不是一个组内的进程)。因此,我在域中添加了一个类processgroup,其成员为列表
,processgroup的实例存储在列表
中。所需的优化将洗牌该列表的成员,导致processgroup的实例被放置在列表列表
的不同索引处。processGroup的索引应为processGroup.index。
文档说明“如果有疑问,规划实体是多对一关系的多个方面。”这意味着processgroup是规划实体,成员index是规划变量,被分配给(希望)不同的整数。在每次新分配索引后,我都必须使用列表列表
processGroup.index的升序排列)。这似乎非常古怪和繁琐。有更好的主意吗?
提前谢谢!
菲利普。
共有1个答案

目前的设计有几个缺点:
- 它需要2个(真正的)实体类(每个实体类有1个规划变量):可能会增加搜索空间(=求解时间更长,更难找到好的甚至可行的解决方案)+它增加了配置复杂性。如果可以合理避免,不要使用多个真正的实体类。
- GroupProcess整数变量需要全部不同且以某种方式是顺序的。这听起来像是一个链式规划变量(参见文档中关于链式变量和车辆路径示例),在这种情况下,整个问题可以表示为一个仅有一个变量的简单VRP,但这真的适用于这里吗?
思路:这个模型有些不对劲:
-
null
-
我正试图用java的Optaplanner实现一个简单的云平衡系统,该系统具有过度约束的规划。 最喜欢的是,我正在尝试使用Optaplanner Java库实现一个简单的云平衡系统,该系统具有过度约束的规划。我将模型映射到我的问题(车辆和资产),进行变量替换cpuPower- 如果我使用这个简单的例子,我会收到一个所有进程都已签名的响应,尽管其中一些不能分配给计算机。对于这个问题,optaplan
-
此约束是否在分数计算器()中。它是否可以检查一个解决方案中的进程组是否被分配到相同的CPU并给它打分? 有没有其他更好的方法,比如使用ValueSelector? 并且我在缺省情况下得到了一个解决方案,即使进程不能分配给CPU(因为限制)。计划者就是这样工作的吗?
-
我正在使用的,并将其调用为 。 的方差非常高,以至于大约1%的对集(用百分位数方法验证)使得集合中的值总数的20%。如果Spark随机使用shuffle进行分区,那么很有可能会有1%的数据落入同一分区,从而导致工作人员之间的负载不平衡。 有没有办法确保“重”元组在分区中正常分布?我实际上将分成两个分区,和,基于) 给出的 阈值,以便分离这组元组,然后重新分区。 但获得几乎相同的运行时间。负载可能已
-
我有自定义背景可绘制的EditText: EditText代码: 我正在使用android数据绑定库和MVVM架构。 当允许编辑并且用户开始在EditText中键入文本时,在键入的单词下会出现额外的下划线(它只属于当前键入的单词,EditText文本的所有其他部分都没有下划线): 我试图通过向EditText添加滤色器来删除下划线: 但不管用。 “java.lang.Integer不能强制转换为A
-
我是微服务的新手。(学习阶段)。我有一个问题。我们在云中部署微服务。(例如 AWS)。云已经提供了负载平衡和日志。我们还在Spring Boot中实现了负载平衡(功能区)和日志(Rabbit MQ和Zipkin)。这两种实现有什么区别?我们两者都需要吗?有些人可以回答这些问题吗? 提前感谢。
-
是否有一种方法可以在微服务的两个pod之间进行主动和被动负载平衡。假设我有两个运行微服务的实例(pod),它是使用K8s服务对象公开的。是否有一种方法来配置负载平衡,使一个pod始终获得请求,当该pod停机时,另一个po将开始接收请求? 我在该服务的顶部还有一个ingress对象。