《均衡》专题
-
如何在Apache Spark中实现任务的动态负载平衡
考虑以下Java伪代码: 上面的Java代码将使我的100个线程都处于繁忙状态,假设方法'process_task_and_split_to_sub_tasks()'可以将任何大任务拆分为许多较小的任务。 有没有一种方法可以在Spark中实现同样的功能,可以与其他工具相结合? null 在这种情况下,动态负载平衡是这样的:已经收到以'a'开头的行的映射器可能想进一步拆分它的行--到以'ab'、'a
-
Kubernetes服务集群IP,如何在不同节点之间平衡内部负载
我创建了一个部署,它导致跨2个节点存在4个吊舱。 然后,我通过一个服务公开这些pod,该服务将产生以下集群IP和podendpoint: 如果通过集群IP在内部访问服务,请求将在两个节点和所有pod之间平衡,而不仅仅是在单个节点上的pod之间平衡(例如,像通过节点端口访问一样)。 我知道kubernetes使用IP表来平衡单个节点上跨吊舱的请求,但我找不到任何文档来解释kubernetes如何平衡
-
作为SSL终端和负载平衡器的OpenShift-Nginx pod
过去,我在Ubuntu上为使用了以下配置文件。它做以下工作: SSL终止 负载均衡器 插入自定义标头 记录调用 我想用部署为OpenShift集群中的pod的复制相同的内容。我可以在OpenShift集群的目录中看到。当我尝试启动一个时,它显示了一个GitHub存储库的字段,其中包含一个示例存储库--https://GitHub.com/sclorg/nginx-ex.git
-
Kafka流localstore分区分配不平衡
首先,很抱歉,如果我的术语不准确,我对Kafka很陌生,我已经尽可能多地读过了。我们有一个使用kafkastreams的服务,kafka版本:2.3.1。流应用程序具有一个流拓扑,该流拓扑从“topica”读取,执行转换并发布到另一个主题“topicb”,然后由拓扑的另一个流消费,并使用Ktable(localstore)聚合它。侦听器将ktable更改发布到另一个主题中。 主题有24个分区。我们
-
如何在ApacheCamel中为http4组件添加负载平衡。对于http4组件代码,请检查下面的代码
Application.yml 文件 在上面的场景中,我们可以在哪里添加多台服务器?在yml文件配置中,如果是,我们如何添加它。 感谢你的帮助。 谢谢
-
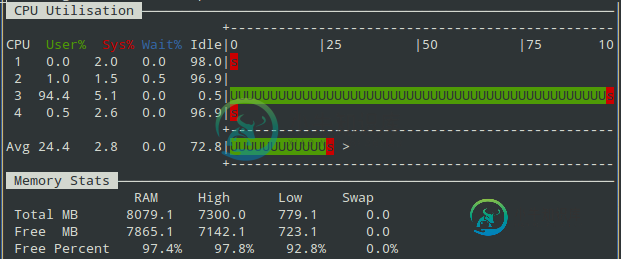 node.js CPU负载平衡
node.js CPU负载平衡我用JMeter创建了测试来测试幽灵博客平台的性能。Ghost是用Node.js编写的,安装在云服务器上,有1GB的内存和1个CPU。 我注意到在400个并发用户之后JMeter得到错误。到400个并发用户的负载是正常的。我决定增加CPU,增加了1个CPU。 但是错误重现并添加了2个CPU,总共4个CPU。问题发生在400个并发用户之后。 我想知道是否有可能平衡CPU之间的负载?
-
WSO2 ESB动态负载平衡endpoint平衡算法
我使用的是WSO2 470 ESB。我需要使用一个提供自定义负载平衡策略的动态负载平衡endpoint。我知道WSO2是基于apache Synapse的,在此基础上我可以找到以下内容: http://synapse.apache.org/userguide/config.html#dlbendpointconfig 真的吗?是否可以通过我自己的类自定义平衡策略?
-
Kafka会允许“无平衡”分区吗?
在系统设计中提出的一个问题是,如果消息键的选择方式在数据流中经常发生,这是否意味着只有一个主题分区将专门接收这些消息,即使这会在分区如何填充数据的方式上造成不平衡? Kafka是否有一种机制可以在多个分区之间“拆分”具有相同键的消息,从而在这种情况下牺牲顺序? 或者键中没有例外
-
Kafka流再平衡:从再平衡到错误的状态转换
我有4个单一分区和应用程序的三个实例的主题。我试图通过编写一个自定义的PartitionGrouper来实现可伸缩性,它将创建如下3个任务: 第一个实例-topic1,分区0,topic4,分区0 第二个实例-主题2,分区0 第三实例-桌面3,分区0 我将NUM_STANDBY_REPLICAS_CONFIG配置为1,因为它将在本地维护状态(也可以消除invalidstatestore异常)。 上
-
在Kafka Streams中重新平衡期间,分区处理一直停滞,直到重建状态存储
假设我有有状态的 Kafka Streams 应用程序,该应用程序使用具有 3 个分区的主题中的数据。目前,我正在运行上述应用程序的2个实例。让我们这样说: 分配了 和 , 分配了 。 因此,现在我想添加新实例,以完全利用并行化。 在我的理解中,一旦我启动了一个新实例,就会发生重新平衡: 或 中的一个以及相应的本地状态存储将从现有实例迁移到新添加的实例。在此示例中,让我们假设 在 上迁移。 同时,
-
使用Apache Camel和Netty对TCP流量进行负载平衡会导致事务失败
null 1.这是Apache Camel-Netty的有效用例吗?我应该看米娜还是其他人? 2.是否可以尝试将tcp通信路由到JMS或其他组件,然后最终到达tcpendpoint? 3.我是否需要编码器/解码器,或者这个配置应该工作? 编辑2: 我增加了客户端的接收超时,并立即注意到预期缓冲区长度的不匹配问题下降到小于1%。但是,我看到使用和不使用Camel时每个事务的响应时间都很大;几乎高出1
-
通过Eureka进行负载平衡,丝带?
Eureka是否提供开箱即用的负载平衡,是否需要另一个依赖项? 为什么是丝带而不是尤里卡? 为什么通过API网关使用负载平衡? Spring-cloud-starter-loadbalancer,为什么需要这个? 客户端平衡还是服务器端负载平衡,为什么用一个胜过另一个?
-
如何在 AWS 网络负载平衡器上保持 TCP 连接处于活动状态
架构: 我们有一系列物联网设备通过AWS网络负载平衡器(NLB)连接到后端服务器。这是一个双向通道(不是请求-响应样式,而是从任何一方传递给另一方的消息)。 目标: 如何在不活动期间保持连接(NLB的两侧)处于活动状态。 说明:客户端经常进入非活动模式,并且不会向服务器发送(或接收)任何内容。如果此状态持续时间超过 350 秒(NLB 的连接空闲超时值),LB 将以静默方式终止连接。这很糟糕,因为
-
衡量Android执行时间的最佳方法?
什么是最好的方法来衡量Android代码段的执行时间? 我有一段前后的代码,我想用时间戳来确定它的执行时间(例如,中的一段,以及活动方法中的另一段)。 我已经试过了。toMillies(false),但它只会向我返回秒数(最后是常量)。我还尝试了两个java函数:和。第一个返回纪元时间的毫秒,第二个不返回。 测量执行时间并获得良好精度的最佳方法是什么?
-
如何为一个主题增加分区的数量,改变每个分区的领导者并重新平衡它们
如果我们有一个主题在Kafka,它有5个分区,我们可以增加到30个分区。另外,在增加分区的数量之后,我们按照代理ID的顺序更改每个分区的领导者,并为该特定主题重新平衡集群。我们怎么能那样做?