《jdbc》专题
-
带有传统数据库的JDBC Kafka连接器
我正在尝试将kafka-jdbc连接器(源代码和接收器)与非常旧的数据库(cloudscape)一起使用。我有这个数据库的 JDBC 驱动程序。我将驱动程序放在Confluent(版本5)的“/share/java/kafka/connect/jdbc”文件夹中,并创建了属性文件。 启动连接器时,日志如下: 我想JDBC驱动程序很旧(它使用JAVA1.3)这一事实存在问题。驱动程序使用RMI协议进
-
融合kafka jdbc连接查询模式
我正在使用合流kafka connect jdbc源将mysql表中的记录推送到我的kafka主题,但似乎日期列被转换为纪元时间。 这是我的配置: kafka主题中的输出: 我也在类似于“select from_unixtime(updated _ on)from temp”的查询中尝试了from _ unixtime(),但是那不行。 有没有办法推到YYYY-MM-DD HH:MM:SS格式的K
-
Kafka connect confluent jdbc 不控制 MSSQL 数据库中的会话池
我正在使用Kafka连接和融合jdbc。将源连接器与Mssql集成,几天前操作区警告我们数据库中有大量处于“睡眠”状态的会话。我需要控制这些会话,但显然连接器(融合jdbc)的配置中没有这些属性。 你有什么想法来纠正这个问题吗?
-
Kafka JDBC源连接器:从列值创建主题
我有一个微服务,它使用 OracleDB 在表中发布系统更改。表包含一个,其中包含事件类型的名称。 JDBC Source Kafka Connect可能会接受表更改,并在KAFKA-TOPIC中使用列的值发布它们? 这是我的源代码kafka连接器配置:
-
kafka connect jdbc:SQLException:只有在使用分布式模式时才没有合适的驱动程序
我们已经成功地使用 mySQL - 使用 jdbc 独立连接器的 kafka 数据摄取,但现在在分布式模式下使用相同的连接器(作为 kafka 连接服务)时面临问题。 connect-distributed.properties档案- 我有我的连接器罐在这里- 我可以通过以这种方式运行脚本来运行独立模式- 但是当我尝试调用 REST API 来运行分布式模式连接器时,出现错误: 错误- 注意 -
-
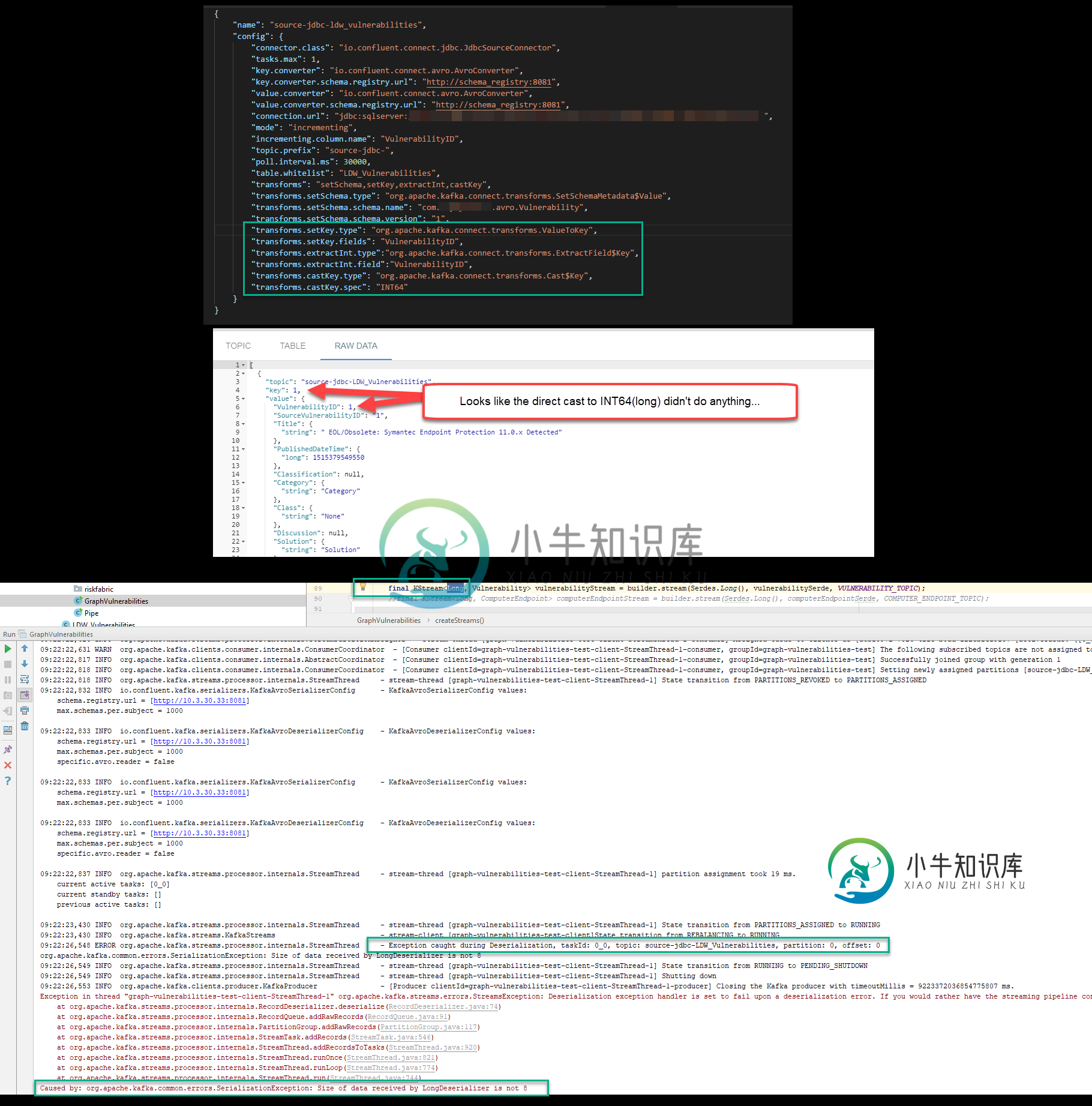 Kafka Streams JDBC源长期不兼容
Kafka Streams JDBC源长期不兼容问题:在设置一个 Kafka 管道后,该管道使用 Kafka Connect JDBC 源和 Avro 序列化程序和反序列化程序将数据拉入,一旦我尝试使用 Kafka Streams Java 应用程序将该数据读入 KStream,就会收到以下错误。 org.apache.kafka命令错误。SerializationException:LongDeserializer接收的数据大小不是8 我试图
-
Kafka Connect:多个DB2 JDBC源连接器失败
我正在尝试在本地Docker容器中使用Kafka Connect(使用官方的ConFluent映像),以便将DB2数据推送到OpenShift(在AWS上)上的Kafka集群。我在使用DB2 JDBC-Jar时使用了ConFluent JDBC连接器。我有不同的连接器配置,因为我使用带有“transforms.create键”的SMT(创建我的密钥),并且我表中的键列有不同的名称。 以下是我的步骤
-
java jdbc中的连接异常
这是类的构造函数之一。新对象在数据库中创建新记录。当我在源代码中“手工”创建这个对象时,一切都很好。但是当我将创建声明放入按钮的actionlistener中时,编译器返回sql异常。 我得到的例外是
-
Kafka连接JDBC源出记忆错误
我正在使用 Confluent JDBC-Source 连接器运行以下作业: 我有一个类似的Kafka-Connect作业在同一个数据库和同一个用户上成功运行,但使用另一个较小的表。所以连接不是问题。 在运行作业的 Kafka-connect 服务器上的日志中,我看到以下内容: 所以,没什么可说的。运行此作业的服务器现在无响应,并且不响应 REST 调用。有什么想法吗?
-
JDBC Kafka Connect with DB2
我正在努力让Confluent的kafka连接器连接到DB2。 我正在 docker 中运行一个 ubuntu 实例来测试普鲁波斯。该解决方案需要部署到 kubernetes,所以 docker 就是这样。 我已经使用apt-get安装了ConFluent平台并添加了他们的repos。所有服务都在运行,kafka,zoo的,模式和kafkaRest。 我已经创建了我的kafka连接属性文件,如本文
-
Kafka连接汇合JDBC MySQL实现错误
我正在尝试将MySQL与Kafka Connect连接,并且出现了许多错误。我正在共享我的connect-standalone.properties和mysql-jdbc-connector.properties,并显示错误。我的 Kafka 和 MySQL 在不同的集群中,我使用的是融合连接器,但不是在融合接口中。我下载了4.1.0 JDBC MySQL融合连接器。 MySQL-JDBC-con
-
无法通过JDBC源连接器触发自定义生成器拦截器
我已经创建了一个自定义的生产者拦截器(Audit病人拦截器),它接受一些自定义配置(application_id,类型等)。)。我已经从奥迪生产者拦截器项目生成了一个罐子,并将罐子放在Kafka连接中 /usr/share/java/monitoring-interceptors.当我尝试发布具有以下配置的JDBC-Source连接器时,我的审计拦截器没有被触发。 正如您在配置中看到的,我在连接器
-
kafka jdbc接收器连接器独立错误
我正在尝试从kafka中的主题将数据插入postgres数据库。我正在使用以下命令加载 sink-quick start-MySQL . properties如下 我得到的错误是 Postgres jar文件已经在文件夹中。有人能提出建议吗?
-
如何将kafka-connect-jdbc-5.5.0.jar添加到Debezium/连接
我已经将 Kafka-connect-jdbc-5.5.0.jar 文件从 Confluent 下载到我的本地机器中,我想知道一种将此 jar 添加到 plugin.path=/kafka/connect 的方法。我正在尝试将数据接收器到 MySQL 服务器,所以我使用“连接器.class”:“io.confluent.connect.jdbc.JdbcSinkConnector”,但我面临“er
-
合流Kafka连接分布式jdbc连接器
我们已经成功地使用了MySQL - 使用jdbc独立连接器的kafka数据摄取,但现在在分布式模式下使用相同的连接器(作为kafka connect服务)时面临问题。 用于独立连接器的命令,工作正常 - 现在,我们已经停止了这一项,并以分布式模式启动了kafka connect服务,如下所示 2 个节点当前正在运行具有相同连接服务。 连接服务已启动并正在运行,但它不会加载 下定义的连接器。 应该对