
Kafka Streams JDBC源长期不兼容

问题:在设置一个 Kafka 管道后,该管道使用 Kafka Connect JDBC 源和 Avro 序列化程序和反序列化程序将数据拉入,一旦我尝试使用 Kafka Streams Java 应用程序将该数据读入 KStream,就会收到以下错误。
org.apache.kafka命令错误。SerializationException:LongDeserializer接收的数据大小不是8
我试图尽可能地遵循现有的示例,但有些事情没有意义。我将在下面包含所有代码/附加信息,但我有几个问题…
>
我目前在理解上的最大差距之一是Avro记录的“KEY”使用了什么?(在运行时)在我身上出错的行与我告诉KStream键是LONG的事实有关,然而当检索Avro记录时,长度小于8(Long类型的预期长度)。
当我设置我的JDBC源时,那里没有任何东西可以标识键是什么——我在留档中也没有看到任何东西会让我相信我可以指定键,尽管我已经尝试过了:
curl -X POST \
-H "Content-Type: application/json" \
--data 'see next code block for formatted data' \
http://localhost:8083/connectors
// This is the data chunk used above but in a string - broke it apart for readability here
{
"name": "source-jdbc-ldw_applications",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"tasks.max": 1,
"connection.url": "jdbc:sqlserver://dbserver;databaseName=dbname;user=kafkareader;password=kafkareader;",
"mode": "incrementing",
"incrementing.column.name": "ApplicationID",
"topic.prefix": "source-jdbc-",
"poll.interval.ms": 30000,
"table.whitelist": "LDW_Applications",
"transforms": "setSchema",
"transforms.setSchema.type": "org.apache.kafka.connect.transforms.SetSchemaMetadata$Value",
"transforms.setSchema.schema.name": "com.mycompany.avro.Application",
"transforms.setSchema.schema.version": "1"
}
}
通过上述操作,我得到了运行报告的以下模式:
curl http://localhost:8081/subjects/source-jdbc-LDW_Applications-value/versions/1 |jq
这是它的输出:
{
"subject": "source-jdbc-LDW_Applications-value",
"version": 1,
"id": 9,
"schema": "{\"type\":\"record\",\"name\":\"Application\",\"namespace\":\"com.baydynamics.avro\",\"fields\":[{\"name\":\"ApplicationID\",\"type\":\"long\"},{\"name\":\"Name\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"Description\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"Group\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"OwnerUserID\",\"type\":[\"null\",\"long\"],\"default\":null},{\"name\":\"RiskScore\",\"type\":[\"null\",{\"type\":\"int\",\"connect.type\":\"int16\"}],\"default\":null},{\"name\":\"RiskRating\",\"type\":[\"null\",\"string\"],\"default\":null},{\"name\":\"ServiceLevelTierID\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"LossPotentialID\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ConfidentialityRequirementID\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"IntegrityRequirementID\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"AvailabilityRequirementID\",\"type\":[\"null\",\"int\"],\"default\":null},{\"name\":\"ApplicationCategoryID\",\"type\":[\"null\",\"long\"],\"default\":null}],\"connect.version\":1,\"connect.name\":\"com.baydynamics.avro.Application\"}"
}
为了让这个模式看起来更漂亮一些:
{
"type":"record",
"name":"Application",
"namespace":"com.baydynamics.avro",
"fields":[
{
"name":"ApplicationID",
"type":"long"
},
{
"name":"Name",
"type":[
"null",
"string"
],
"default":null
},
{
"name":"Description",
"type":[
"null",
"string"
],
"default":null
},
{
"name":"Group",
"type":[
"null",
"string"
],
"default":null
},
{
"name":"OwnerUserID",
"type":[
"null",
"long"
],
"default":null
},
{
"name":"RiskScore",
"type":[
"null",
{
"type":"int",
"connect.type":"int16"
}
],
"default":null
},
{
"name":"RiskRating",
"type":[
"null",
"string"
],
"default":null
},
{
"name":"ServiceLevelTierID",
"type":[
"null",
"int"
],
"default":null
},
{
"name":"LossPotentialID",
"type":[
"null",
"int"
],
"default":null
},
{
"name":"ConfidentialityRequirementID",
"type":[
"null",
"int"
],
"default":null
},
{
"name":"IntegrityRequirementID",
"type":[
"null",
"int"
],
"default":null
},
{
"name":"AvailabilityRequirementID",
"type":[
"null",
"int"
],
"default":null
},
{
"name":"ApplicationCategoryID",
"type":[
"null",
"long"
],
"default":null
}
],
"connect.version":1,
"connect.name":"com.baydynamics.avro.Application"
}
所以,再一次,我没有看到任何东西表明上面的任何特定字段将是记录的关键。
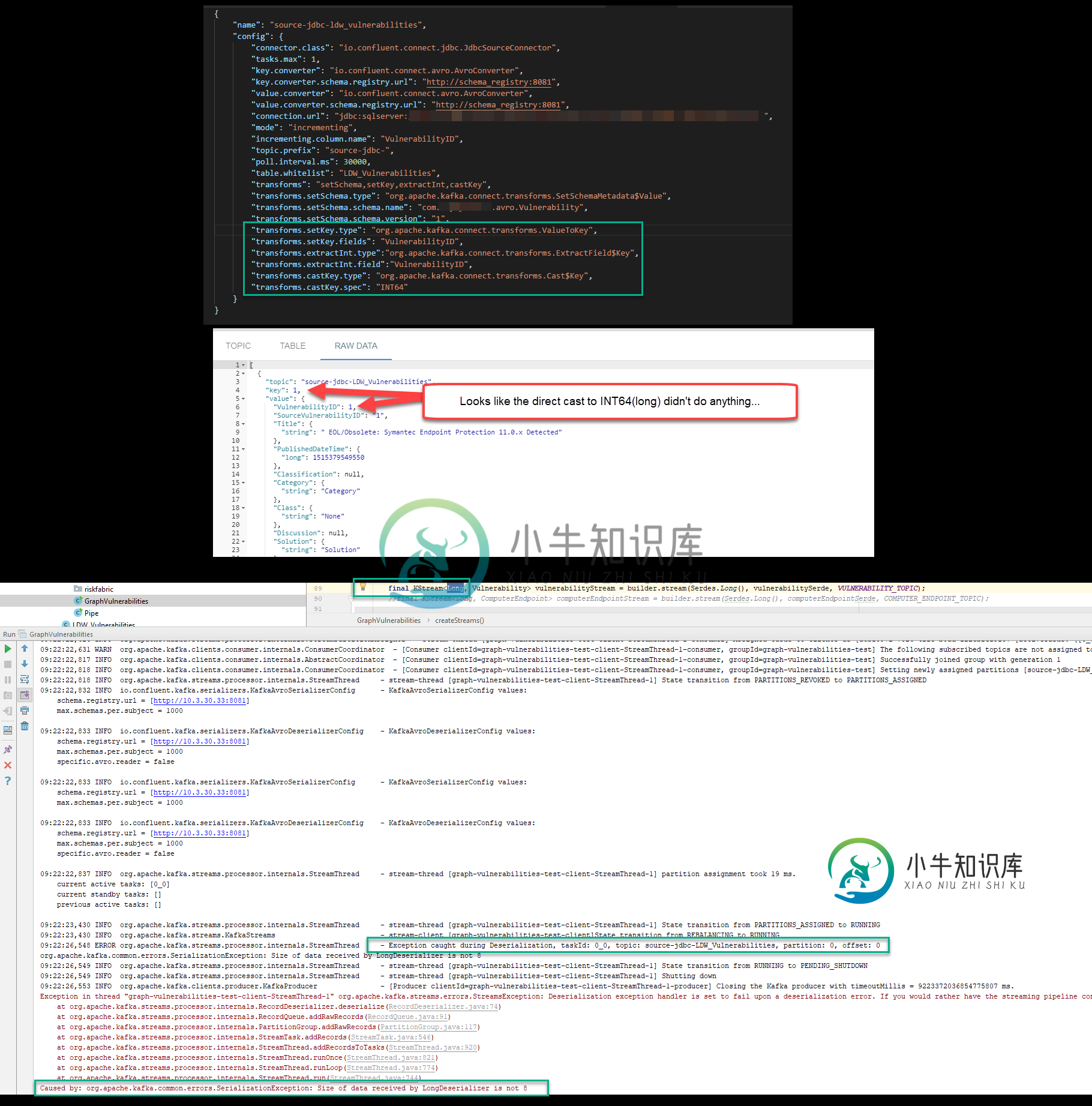
然后我进入Kafka Streams,我试着把这些数据放入KStream...它爆炸了...
final KStream<Long, Application> applicationStream = builder.stream(Serdes.Long(), applicationSerde, VULNERABILITY_TOPIC);
所以,事情是这样的,因为我知道存储在幕后的数据是SQL Server中的BIGINT,并且映射到Java中的LONG,所以我将KStream的密钥类型设置为Long,然后我使用Serdes.Long()反序列化器作为KStream构建器的参数。
调试时,我看到原始记录的长度为 7,这就是它引发错误的原因。显然 Avro 以一种更好地压缩的方式序列化东西?我不知道。无论如何,问题是我什至不知道它认为它实际上使用的密钥是什么?!所以谁知道 - 也许我对 Long 的假设是不正确的,因为它实际上并没有使用 ApplicationID 作为键?为什么我会认为是?!
任何关于这方面的帮助将不胜感激。我知道上面有很多信息,但简单来说..
- 使用JDBC Kafka连接将数据推送到主题
- 数据正在进入主题-我可以通过控制台看到它
- 试图将这些数据推送到流中,这样我就可以用这些数据做一些很棒的事情,但由于Serdes与Avro Record不兼容,尝试填充流时会失败
共有1个答案
ConFluent JDBC源连接器不会生成带有密钥的记录。已经记录了添加此支持的功能请求。
同时,您可以使用单个消息转换从值中提取一些字段,从而实质上创建密钥。内置的ValueToKey转换就是这样做的。这篇博客文章有一个SMT的例子。
-
我目前正在使用gradle,似乎可以通过java插件设置sourcecompatibility和targetcompatibility 我想知道除了与旧的JDK向后兼容之外,我们使用sourcecompatibility/targetcompatibility的原因是什么? 如果没有设置sourcecompatibility/targetcompatibility,升级到最新的java会更容易吗?
-
是2048位的RSA键,但有不同的表示形式(Sun或OpenSSL)。 是2048位的字节数组。 问题是:我对有不同的结果。在Sun JRE上是128位的AES密钥,在Android上是2048位的数组,包含以下字节: [1,-1,-1....,-1,0,(此处为实际密钥字节)] 原始包装按以下方式进行: UPD:我没有注意,没有注意到这样一个事实:unwrapped不是256位,而是2048位。
-
完成上一节的初次运行后,你肯定会发现一点:一旦你按下 Ctrl+C,停下标准输入输出,logstash 进程也就随之停止了。作为一个肯定要长期运行的程序,应该怎么处理呢? 本章节问题对于一个运维来说应该属于基础知识,鉴于 ELK 用户很多其实不是运维,添加这段内容。 办法有很多种,下面介绍四种最常用的办法: 标准的 service 方式 采用 RPM、DEB 发行包安装的读者,推荐采用这种方式。发
-
如果你正在管理开源项目中的程序员,要尽量保持足够的时间,这样他们才能获得足够的技术和政治技能—最少也需要几年时间。当然,没有项目,无论是开源还是闭源,都可以从轮换程序员中获益。新来者搞清楚窍门需要的时间在不同环境下各不相同。但是在开源项目中的代价更加巨大,因为离开的开发者不仅带走了他们的知识,也带走了社区中的他们的地位和其中建立的人际关系。 开发者已经积累的信誉不能够传递。一个新来的开发者不能继承
-
问题内容: 当我尝试执行此代码时,在“ with DateDimension”行出现错误: 消息206,级别16,状态2,第15行 操作数类型冲突:日期与int不兼容 这是我正在使用的SQL查询: 问题答案: 您的问题在于该部分。尝试使用,如下所示: 编辑:我不知道您的原始代码是否要使用该选项,但是如果您不知道我建议您阅读此内容。基本上,在这种情况下,这意味着您可以使用CTE列出1,000个日期。
-
日期格式与Javascript日期对象格式相同,例如- 2017年5月25日(星期四)10:00:00 GMT+1200(新西兰标准时间) 我以前用的是下面的格式- 我当然可以修改格式化程序 EEE MMM dd yyyy HH:MM:SS'GMT'Z'('ZZZZ')'