《jdbc》专题
-
Regex用于分析数据库列,如JDBC ResultSet
我正在使用JDBC从查询结果中获取列。 例如: 我想在运行查询之前解析它们。本质上,我希望为列标签创建一个数组,该数组将与resultSet所期望的值相匹配。get**方法。出于说明的目的,我想用这个替换上面的循环,并得到相同的结果: 这看起来很简单。我可以用一个简单的正则表达式解析我的语句,该正则表达式接受SELECT和from之间的字符串,使用列分隔符创建组,并从组中构建arrayOf列。但是
-
.NET SQL插入比JDBC慢?(JDBC快4倍)
我在。NET本地SQL客户端之间用C#进行了一些测试,并与java中的JDBC驱动程序进行了比较,结果让我大吃一惊,我想我一定是在。NET代码中做错了什么。结果在一个有整数和文本字段的表中插入100万次,我在每次尝试之前清空它,运行为发布而构建的程序,并由它们自己运行。 null 更新:SQL探查器结果。NET: SQL探查器结果JDBC:
-
为什么MySQL insert比JDBC慢?
-
找不到JDBC驱动程序
因此,我一直在使用sbt with assembly将所有依赖项打包到一个jar中,用于spark工作。我做了几个工作,使用设置连接池信息,将其广播出去,然后在RDD上使用获取连接,并将数据插入数据库。在我的sbt构建脚本中,我包括 这确保JDBC连接器与作业打包在一起。一切都很好。 因此,最近我开始使用SparkSQL,并意识到使用中的新特性,简单地获取一个dataframe并将其保存到jdbc
-
Spark jdbc-read->update->写无主键的大表
这个表有大约100万条记录,数据大小大约。我的执行器内存只有。我可以使用Spark-JDBC处理这个表吗。
-
存储过程的jdbc-varbinary(max)out参数被截断为8000字节
存储库代码是 我的测试代码如下所示,当我运行它时,我会得到错误: 当我注销时,使用:
-
对于多个JDBC驱动程序,正确的复制策略是什么?
我有下面的版本。格雷德尔在我的项目中 文件。实际上,这个Oracle JDBC依赖项导入多个JAR,它们之间有更多冲突文件(内容不同)(例如和此目录中的其他文件)。 当DuplicatesStrategy设置为WARN时,Oracle驱动程序将覆盖SQL Server JDBC驱动程序的。覆盖此(和其他)文件会产生什么后果? 我应该如何处理这些重复文件?有没有办法从所有jar中获取所有文件?jar
-
JDBC连接在Windows上工作,但在Ubuntu上不工作
我有一段非常简单的Java代码,在那里我尝试从Java连接到我的Oracle DB。 在Windows下一切正常,但当我尝试在Ubuntu上运行时,我得到了一个错误。 我读了很多书,也试过很多解决方法。这是我的代码: 当我运行它时,我收到一个错误: 连接失败Java.sql.sqlRecoverable异常:IO错误:网络适配器无法在oracle.jdbc.driver.T4CConnection
-
我应该将时区与Postgres和JDBC的时间戳分开存储吗?
看起来(也许我错了),如果您想要保留JDBC和Postgres发生的事情的时区,您需要将时区与时间戳分开存储。 也就是说,我更愿意给我的ORM/JDBC/JPA一个Java(或Joda),其中包括时间区域到Postgres字段。我希望在检索时,不管服务器的时区(或默认为UTC)如何,都能返回一个,时区为。但只需看看大多数JDBC代码(以及依赖于它的事情不会发生)。 这是正确的吗? 当postgre
-
在ubuntu 18.04中通过eclipse使用mySql(mysql 5.7.22)进行JDBC连接时出错[重复]
请帮助解决这个错误。同样的代码在windows中运行良好。但是我不明白为什么它不能在Linux(Ubuntu 18.04)上运行。 以下代码: 运行代码时引发此异常:
-
Java:无法为EmbeddedDerby加载JDBC驱动程序
我在为Em申明德比加载JDBC驱动程序时遇到了问题。以下是我编译和运行我的程序的案例 > 案例1: 编译:E:\java\WorkReminder Run: E:\java\WorkReminder 错误: 无法加载JDBC驱动程序org . Apache . derby . JDBC . embedded driver。请检查您的类路径。Java . lang . classnotfoundex
-
具有InterBase JDBC驱动程序的sun/io/ByteToCharConverter
对于InterClient7.5.1和8.1.5,在Java8中创建新的JDBC连接失败 此类似乎被InterClientJDBC库引用或使用。Java7不会发生错误。是否有方法解决此错误? 此代码重现了Java 8上的问题: 输出: interbase.interclient.Connection处线程“main”java.lang.NoClassDefFoundError:sun/io/Byt
-
线程“main”java.lang.ClassNotFoundException中出现异常:未能找到数据源:jdbc
以下是我从IntelliJ获得的代码: 当我在spark-shell中运行它时,它正在运行文件:/opt/spark/bin/spark-shell--jars/home/tigergraph/ecosys/tools/etl/tg-jdbc-driver/tg-jdbc-driver-1.2.jar 我怎么才能修好?
-
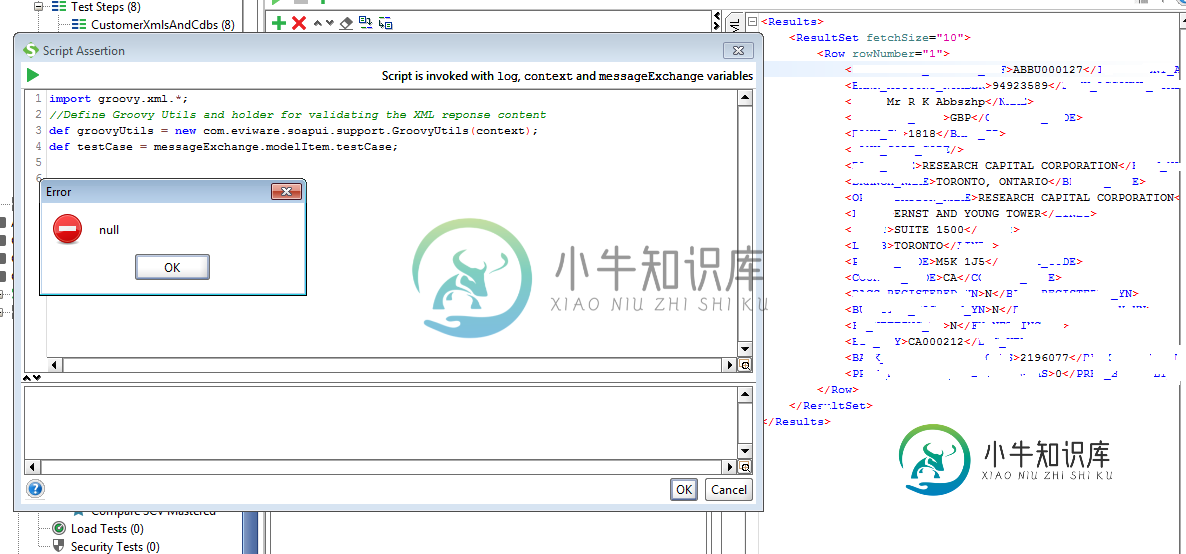 messageExchange对象在JDBC Teststep断言上不可用,但在SOAP请求断言上可用
messageExchange对象在JDBC Teststep断言上不可用,但在SOAP请求断言上可用我的动机是使用我存储在“属性”测试步骤中的 XML 文档断言来自 JDBC 调用的响应。我需要验证一些值。 我正在尝试在 SoapUI 5.2.1 中的 JDBC 测试步骤中使用脚本类型断言。我以前也为“SOAP 请求”测试步骤创建了脚本类型断言,它们工作正常。在JDBC的情况下,当我使用: 我明白了错误 无法获取空对象的属性“modelItem”。
-
如何通过。要从jdbc驱动程序读取的enc密码文件
我想将rdbms中的数据摄取到spark。早些时候,我使用sqoop在hdfs中加载数据,因为我正在传递。 我想使用spark.readjdbc。我尝试通过文件名 但它不起作用。我需要一些解决方案来使用. enc文件与火花读?